
Introduction
We have explored the Pipeline API of the transformers library which can be used for quick inference tasks. You can find more about it in my previous blog post here.
Now let’s go deep dive into the Transformers library and explore how to use available pre-trained models and tokenizers from ModelHub on various tasks like sequence classification, text generation, etc can be used.
So now let’s get started…
To proceed with this tutorial, a jupyter notebook environment with a GPU is recommended. The same can be accessed through Google Colaboratory which provides a cloud-based jupyter notebook environment with a free NVIDIA GPU.
Installation of Transformers Library
First, let’s install the transformers library,
!pip install transformers[sentencepiece]
To install the library in the local environment follow this link.
You should also have an HuggingFace account to fully utilize all the available features from ModelHub.
Getting Started with Transformers Library
We have seen the Pipeline API which takes the raw text as input and gives out model predictions in text format which makes it easier to perform inference and testing on any model. Now let’s explore and understand how the pipeline API works and the different components involved in it.
Tokenizers
Like any other neural network, the transformers also can’t process the raw input text directly, hence it needs to be preprocessed into a form that the model can make sense of. This process is called tokenization where text input is converted into numbers. To do this we use a tokenizer that does the following
- Splitting the input text into words, subwords, or individual letters that are called tokens.
- Mapping each token with a unique integer.
- Arranging and adding required inputs that are useful to the model.
The preprocessing and tokenization process needs to be done in the same way as when the model was trained. Since we are using pre-trained models, we need to use the corresponding tokenizer for the model and this can be achieved by using AutoTokenizer class.
Let’s get the model/checkpoint name from the ModelHub and load the corresponding tokenizer by using the from_pretrained method from AutoTokenizer class.
from transformers import AutoTokenizer checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
In the above code, we have imported the AutoTokenizer class from the transformers library and initialized the model checkpoint name.
Now let’s initialize the tokenizer,
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=checkpoint)
When the above code is executed, the tokenizer of the model named distilbert-base-uncased-finetuned-sst-2-english is downloaded and cached for further usage. You can find more info about the model on this model here.
Now we can use this tokenizer directly on the raw text to get a dictionary of tensors to feed it directly to the model. The transformers will only accept tensors as input, hence the tokenizer return the input in tensor form.
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I am very excited about training the model !!",
"I hate this weather which makes me feel irritated !"
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
Output:

From the above output, we can see that the output is a dictionary containing input_ids and attention_mask keys. The input_ids consist of tokenized inputs and attention_mask contains the 1s and 0s which are used by the attention layer in the transformer defining whether the corresponding token should be attended or not.
Now let’s go through the model…
Model using Transformers Library
We can download the pre-trained model the same way we downloaded the tokenizer.
from transformers import AutoModel checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
We are using the same from_pretrained method from the AutoModel class to load the pre-trained model.
model = AutoModel.from_pretrained(checkpoint)
Similar to the tokenizer, the model is also downloaded and cached for further usage. When the above code is executed, the base model without any head is installed i.e. for any input to the model we will retrieve a high-dimensional vector representing contextual understanding of that input by the Transformer model.
The above transformer model which encoder-decoder architecture is able to extract useful and important features/contextual understanding from the input text, which can be further used for any task like text classification, language modeling, etc…
The output of the model is a high dimensional vector and it has three dimensions,
- Batch size: The number of sequences processed at a time.
- Sequence Length: The length of each sequence or numerical representation.
- Hidden Size: The vector dimension of model input.
We can check the output of our model by following,
outputs = model(**inputs) print(outputs.last_hidden_state.shape)
Output:
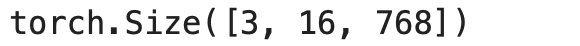
We can get the outputs bypassing the tokenized inputs into the model. From the shape of the output’s hidden state, we can see that our model has a batch size of 3, a sequence length of 16, and a hidden state of size 768.
The above output of the transformer model can be sent a model head to perform our required task.
We can get the model directly from the checkpoint by using different class types of AutoModel i.e
- AutoModelForSequenceClassification – This class is used to get a text classification model from the checkpoint.
- AutoModelForCasualLM – This class is used to get a language model from the given checkpoint.
- AutoModelForQuestionAnswering – This class is used to get a model to perform context-based question answering etc…
There are different architecture available in the Transformers library, each one designed for a specific task.
Now let’s finally look at a Sequence classification task and how it can be done using AutoModel.
Sequence Classification
Now let’s import the AutoModel and AutoTokenizer classes and get our model and tokenizer from the checkpoint.
from transformers import AutoModelForSequenceClassification, AutoTokenizer checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
Now let’s download the model and get some predictions,
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
We use the same from_pretrained method we used previously to get our classification model.
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I am very excited about training the model !!",
"I hate this weather which makes me feel irritated !"
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
We now have the tokenized inputs ready. Now let’s get the predictions,
outputs = model(**inputs) print(outputs)
Output:

print(outputs.logits.shape)
Output:

We can see that our model has returned a 3 x 2 matrix, (since we have 3 sequences in input and there are 2 classes).
We can apply the softmax activation to our outputs for easy understanding,
import torch outputs = torch.nn.functional.softmax(outputs.logits, dim = -1) print(outputs)
Output:
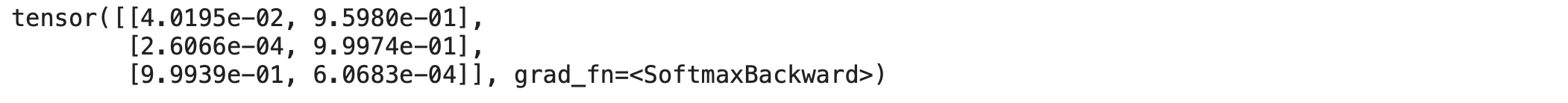
We can see that the outputs are passed through softmax activation to get the probabilities of each class for the input sentences.
We have [0.04, 0.95] as the output for the first input, [0.0002, 0.99] as the output for the second input, and finally [0.99, 0.000006] as the output for the third input sample.
If we check the labels of the model by,
model.config.id2label
We get the output as,

Hence we can see that our model is 95% confident that the first input sample belongs to the POSITIVE class, 99% confident that the second input sample belongs to the POSITIVE class, and 99% confident that the third input sample belongs to the NEGATIVE class. We can see that the model’s output is pretty accurate.
Therefore the Pipeline API for Text classification can be written as,
Code:
# Imports
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# Define the model checkpoint
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
# Download and cache the tokenizer and classification model
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
# Define the inputs and tokenize them
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I am very excited about training the model !!",
"I hate this weather which makes me feel irritated !"
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
# Get the outputs from the model
outputs = model(**inputs)
print(outputs)
# Find the class/label probabilities
outputs = torch.nn.functional.softmax(outputs.logits, dim = -1)
print(outputs)
# Find the label to class mapping for verification
print(model.config.id2label)
Conclusion
We have seen that we can download the pre-trained models and tokenizers and use them directly on our own dataset. From the above example, we have seen that the pre-trained model was able to classify the label/sentiment of input sequences with almost 100% confidence.
Hence we can conclude that these pre-trained models can be used to creating state-of-the-art NLP systems and by fine-tuning it on our own datasets we can be able to get awesome results by yielding higher scores in the required metric.
References:
Image Sources
Image 1 – discuss.hugging face.co
Link for the colab notebook – https://colab.research.google.com/drive/1OZ-JYvTu12CYppYoPAoydkGp5sDjzuL1?usp=sharing
About the Author:
I’m Narasimha Karthik, Deep Learning Practioner.
I’m a final-year undergraduate student at PES University. Currently working with Computer Vision and NLP. Experience in working with PyTorch, Fastai, Tensorflow, and Keras frameworks. You can contact me through LinkedIn and Twitter for any projects or discussions.
Thank you
Hi,
I am Narasimha Karthik J, a Data Scientist at Boeing Research in Bengaluru. I have experience in fine-tuning language model models (LLMs) for various domain-specific applications and deploying them. Additionally, I am experienced in LLM training, fine-tuning, RAG, and working with the latest frameworks and technologies.
Thanks and Regards,
Narasimha Karthik J





Hi This is very useful I have a question though. When I pass a large enough list of sentences to the model as input, the kernel repeatedly crashes. The maximum amount it seems to be able to handle is 100 items in the list of sentences. Even if I pass the whole data in batches, the kernel still crashes. Any idea why?
Hi How can I pass a large list of sentences to the model? When I try to do so, the kernel crashes. Otherwise, if I use a data loader or load the data in batches, it still crashes. The upper value seems to be of a 100 different items.