This article was published as a part of the Data Science Blogathon
Overview
When Apache Cassandra first came out, it included a command-line interface for dealing with thrift. Manipulation of data in this manner was inconvenient and caused knowing the API’s intricacies. Although the Cassandra query language is like SQL, its data modeling approaches are entirely different.
A poor data model in Cassandra can decrease performance, especially when users try to apply RDBMS principles to Cassandra. It is best to follow the rules outlined below.
Table of Content
- Introduction.
- SQL VS CQL (NoSql).
- Cassandra data model rules.
- Cassandra data model components.
- About myself.
- Conclusion.
Introduction
A decent Cassandra data model distributes data equally throughout the cluster’s nodes. Put restrictions on the size of a partition. Reduces the number of divisions that a query returns. The primary goal of the Cassandra Query language is to provide a structured approach to the data.
SQL VS CQL(NoSql) – Creating databases in CQL and SQL
Cassandra Query Language (CQL) offered abstraction. CQL is comparatively similar to SQL, which is used in relational databases like MySQL and Postgres. For users who are familiar with relational databases, this commonality lowers the entrance barrier.
/* Create a new keyspace in CQL */
CREATE KEYSPACE product WITH replication =
{'class': 'Skyline', 'replication_factor': 1};
/* Create a new database in SQL */
CREATE DATABASE product;
Cassandra Data Model Rules
Cassandra is a key-value store and a NoSQL database. The following are the characteristics of the Cassandra data model:
- Cassandra stores the data as a series of rows arranged at tables.
- Tables refer to as column families.
- A primary key value identifies each row.
- The vital key can divide the data.
- You can retrieve all the data or only a subset of it based on the primary key.
Cassandra Data Model Requirements:
Writes are not costly in Cassandra. Cassandra does not allow joins, group by, OR clauses, aggregations, and other similar operations. You must save your data in such a way that it is entirely retrievable. As a result, while modeling data in Cassandra, we must follow some criteria.
Cassandra provides fast write performance. So, to improve read performance and data availability, aim to maximize your writes. There is a cost associated with data write and data read. So, to increase data read performance, increase the amount of data writes.
Cassandra Data Model Components
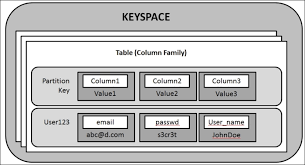
Cassandra’s data model provides a structure for data storage. The components of the Cassandra data model are keyspaces, tables, and columns.
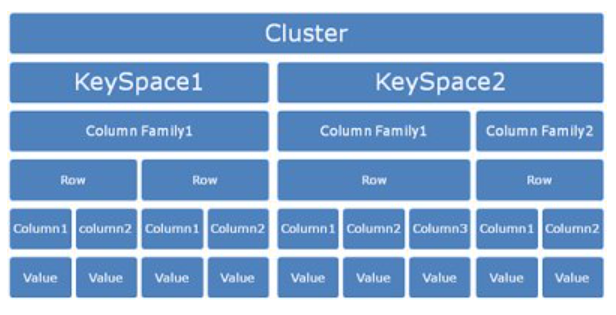
Keyspaces:
At the most basic level, the Cassandra data model comprises key spaces. Key spaces are data containers, comparable to a relational database’s schema or database. Key spaces often include many tables.
There is no default keyspace, so we must establish a keyspace before creating tables.
A keyspace can include an unlimited number of tables, and a table can only belong to one keyspace. This is a one-to-many connection.
At the keyspace level, we define repetition. Replication of three, for example, shows that each data row in the keyspace will have three copies.
create keyspace TestDB
with replication = {
'class': 'SimpleStrategy',
'replication_factor' : 3 # ->3 is Replication factor for this keyspace
};
Use TestDB; #Command to use the keyspace.
You must also provide the replication factor when creating the keyspace. We can change the replication factor.
The following sample query displays the command for establishing a keyspace with the name TestDB, replication as SimpleStrategy, and a replication factor of three. It also shows the use command to use the keyspace.
Tables:
We define the tables within the key spaces. We also knew tables as Column Families in early versions of Cassandra. Tables comprise columns and a primary key, and they store data in rows.
A table contains data in both horizontal and vertical forms, which are rows and columns. Tables have several rows and columns. It knew a table as a Column Family in older versions of Cassandra.
In some Cassandra error messages and documentation, we still refer to it as a column family.
The statement for establishing a table named employee with four columns emp_id, emp_firstname, emp_lastname, and emp_salary has given in the query:
Create table Department(
deptID int primary key,
numEmployees counter);
Update Department set numEmployees = numEmployees +1
where deptiD = 1000;
Emp_id is of the integer type in this query, emp_firstname and emp_lastname, the text type, and emp_salary is defined as duplicate. We should note that emp_id is the primary key to the table. The primary key in database terms is a column that contains unique values for each row in a table.
Columns:
Columns define the data structure of a table. We connect each column with a data type, such as integer, text, double, or Boolean. This course will go through these Cassandra data model components in depth.
In Cassandra, a column is a single piece of data with a type assigned to it.
It has several characteristics, including:
- Integer, large integer, text, float, double, and Boolean are examples of column types.
- Collection types like set, list, and map are also available in Cassandra.
- In addition, each column value has a timestamp that shows when it was last updated.
- The function of write time may get the timestamp.
Counter:
A counter is a specific column that keeps an incremented number. It may count the number of times an event or process occurs. The counter has the following features:
- Only by adding or subtracting from the existing value can the value be updated.
- A counter will start with a value of zero before the first update.
- We may update only the counter columns in Cassandra using the current value.
In the following query, a counter column called numEmployees is assigned to the table Department.
Create table Department(
deptID int primary key,
numEmployees counter);
Update Department set numEmployees = numEmployees +1
where deptID = 1000;
For a record with deptID = 1000, it also illustrates how to increase the column value depending on the previous value.
Good Primary Key in Cassandra
Let’s see some examples and find which primary key is genuine.
Here is the table Music_Playlist.
Create table Music_Playlist
(
Song_Id int,
Song_Name text,
Year int,
Singer text,
Primary key(Song_Id, Song_Name)
);
In the above illustration, table Music_Playlist,
Song_Id is the partition key, and
Song_Name is the clustering column
We will base data gathered on Song_Name. We will create only one partition with the Song_Id. There will not be any other partition on the table Music_Playlist.
This data model will slow data retrieval because of the bad primary key.
Here is another table Music_Playlist.
Create table Music_Playlist
(
Song_Id int,
Song_Name text,
Year int,
Singer text,
Primary key((Song_Id, Year), Song_Name)
);
In the above example, table Music_Playlist,
Song_id and Year are the partition key, and
Song_Name is the clustering column.
They will assemble data based on Song_Name. In this record, each year, we will build a new partition. All the songs of the year will be on the identical node. This primary key will be very useful for the data.
By the way, data retrieval will be quick by this data model.
Create a table according to your queries:
Create a table based on your searches. Make a table that will answer your questions. Make a table in such a way that just a few partitions must be read.
Handling One to One Relationship in Cassandra:
The term “one-to-one connection” refers to the correlation between two tables. For example, a student may only register for one course, and I’d like to find out they enrolled in which course.
So, in this example, your table structure should include all the student’s information on that specific course, such as the course name, the student’s roll number, and the student’s name.
Create table Student_Course
(
Student rollno int primary key,
Student_name text,
Course_name text,
);
Handling One to Many Relationships in Cassandra
One-to-many connections are when two tables have one-to-many connectivity. Many students can study a course. I’d want to find all the students enrolled in a specific course.
So, if I query on the course name, I’ll get a long list of students who will take that course.
Create table Student_Course
(
Student_rollno int,
Student_name text,
Course_name text,
);
Now, to retrieve all the students for a particular course, we have to type the following query.
Select * from Student_Course where Course_name='Course Name';
Handling Many-to-Many Relationship in Cassandra
Having a lot of communication between two tables is referred to as having a lot of connections.
Many students can take a course, for instance, and a single student can study a variety of courses. I’d want to find all the students enrolled in a specific course. In addition, I’d want to search for all the courses that certain students enrolled in.
So, In this case, I will have two tables, i.e. divide the problem into two problems. First, I will create a table by which you can find courses by a particular student.
Create table Student_Course
(
Student_rollno int primary key,
Student_name text,
Course_name text,
);
We can find all the courses by a particular student by the following query.
Select * from Student_Course where student_rollno=rollno;
Second, we create a table by which we can find how many students are studying a particular course.
Create table Course_Student
(
Course_name text primary key,
Student_name text,
student_rollno int
);
This statement is to find a student in a particular course by the following query.
Select * from Course_Student where Course_name=CourseName;
Employee Cassandra data model:
Let’s look at an example to better understand the model. We have two rules to frame a Cassandra model.
- Spread Data Evenly Around the Cluster.
- Minimize the Number of Partitions Read
- Query to get the details of an employee against a particular employee ID:
The schema looks like this:
CREATE TABLE employee (
employee_ID int PRIMARY KEY,
employee_Name text,
designation text,
salary int,
location text
)
Let’s match against the rules. As each employee has a different partition hence, it matches the spread of the data evenly around the cluster rule. Yes, only one partition is read to get the data, to minimize the number of partitions read rule is applied.
2. Query to get the details of all the employees for a particular job designation:
Now the requirement for an employee has changed. Now we need to get the details about the designation of the employee. The schema will look like this:
CREATE TABLE employee (
employee_ID int,
employee_Name text,
designation text,
salary int,
location text,
PRIMARY KEY (designation, employee_ID)
)
In the above schema, composite primary key comprising designation, which is the partition key, and employee_ID as the clustering key.
This appears to be good, however, let’s check our rules once more:
Spread data equally across the cluster — our schema may break this rule. If a high number of entries fit into one category, we will group the data into one division. We will not disperse the data.
Reduce the number of partitions read — To retrieve the data, we read only one partition.
3. Query to get the details of all employees details living in a particular location:
If a single partition has many records, it would be difficult to distribute the data uniformly across the cluster. We may solve this problem by creating the model in the following way:
CREATE TABLE employee (
PRIMARY KEY ((designation, location), employee_ID)
employee_ID int,
employee_Name text,
designation text,
salary int,
location text,
)
Now the distribution will be more across the cluster as we are considering the location of each employee.
Both the rules satisfy this schema,
Summing up the rules, RDBMS and Cassandra are different, so we need to think of other ways to design a Cassandra data model. The above laws need to be followed to produce a suitable data model, which will be fast and efficient.
About Myself:
I’m Lavanya, living in Chennai. I am a passionate writer and enthusiastic content maker. I am fond of reading books on deep learning. While reading, I came across many fascinating topics in ML and deep learning. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of deep learning. I am seeking forward to your valuable comments and views on my article.
Conclusion
I hope you enjoyed the article, and I am happy if I hear some comments about my article from your side, so feel frank to add them up in the comment section. Thank you for reading.
Image Sources
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.






Thanks for the detailed design guide. Appreciated your efforts
I wish you had also supplied the data for this. Or if you did, I could not find it in the article