This article was published as a part of the Data Science Blogathon
PySpark Column Operations plays a key role in manipulating and displaying desired results of PySpark DataFrame. It is important to know these operations as one may always require any or all of these while performing any PySpark Exercise. PySpark DataFrame is built over Spark’s core data structure, Resilient Distributed Dataset (RDD).

In this article, we learn few PySpark operations that involve columns majorly. We will start from the basic installation of necessary libraries, creation of SparkSession and would explore the various method involved in PySpark DataFrame Column operations. By the end of this article, one would be able to perform PySpark DataFrame manipulation with minimum effort. It is advisable to read the complete article step by step as each section will have reference to its previous section.
Table of Contents
- Introduction
- Creating New Column in PySpark DataFrame
- Renaming an Existing Column in PySpark DataFrame
- Selecting One or More Columns of PySpark DataFrame
- Creating a Column Alias in PySpark DataFrame
- Conclusions
Introduction
Resilient Distributed Dataset is a low-level object that allows Spark to work by dividing data into multiple cluster nodes. But since Resilient Distributed Dataset is difficult to work directly, we use Spark DataFrame abstraction built over RDD. Spark DataFrame behaves similarly to a SQL table. These PySpark DataFrames are more optimized than RDDs for performing complicated calculations. In each section, we will first look at the current PySpark DataFrame and the updated PySpark DataFrame after applying the operations.
For the practice purpose, we will execute the PySpark operations in Google Colaboratory Notebook.
Creating New Column in PySpark DataFrame
In this section, as a part of the prerequisite, we will first create a SparkSession. Then we will create a new dataframe by importing a CSV file. Later we will create a new column using the .withColumn() method.
Installing Libraries
!pip install pyspark
Importing the Libraries
from pyspark.sql import SparkSession
Creating Spark Session
spark = SparkSession.builder.appName('PySpark Column Ops').getOrCreate()
Here, will have given the name to our Application by passing a string to .appName() as an argument. Next, we used .getOrCreate() which will create and instantiate SparkSession into our object spark. Using the .getOrCreate() method would use an existing SparkSession if one is already present else will create a new one.
Reading the Dataset
df = spark.read.csv('Fish.csv', sep = ',', inferSchema = True, header = True)
Here, we imported the Fish dataset downloaded from Kaggle.
Checking the Imported Dataset
df.show()
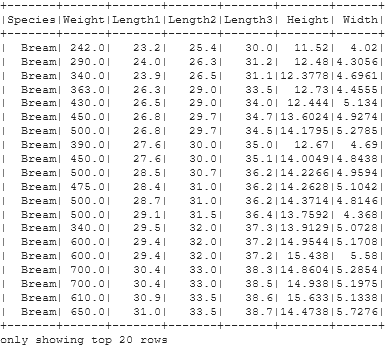
Creating a New Column
df = df.withColumn('Weight in Kg', df.Weight/1000)
Let’s suppose I want a new column with the Weight of Fishes in Kilograms. Here, we used the .withColumn() method. In the .withColumn() method, the first argument is the new column name we want, the second argument is the column values we want to have. Here, we have given the New Column name as ‘Weight in Kg’ and its values as Column Weight divided by 1000, which will convert Weight values from Grams to Kilograms.
Checking the Updated DataFrame
df.show()
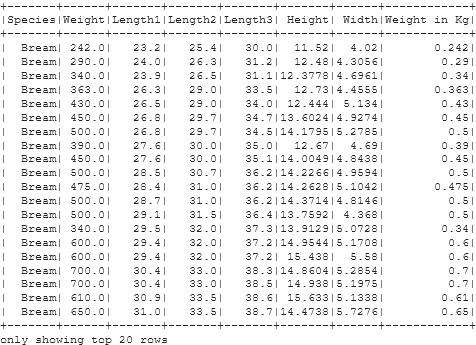
Renaming an Existing Column in PySpark DataFrame
In this section, we we will rename our PySpark DataFrames’s existing column using the .withColumnRenamed() method.
Let us continue with the same updated DataFrame from the last step with an additional Column of Weights of Fishes in Kilograms.
Checking the Current PySpark DataFrame
df.show()
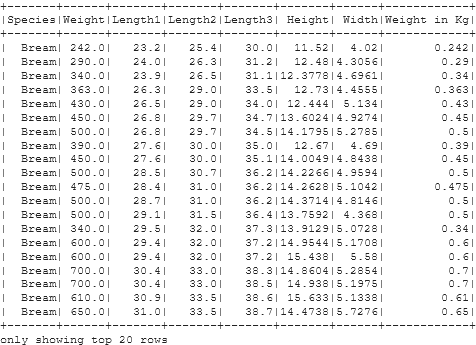
Renaming the Column
df = df.withColumnRenamed("Weight in Kg", "Weight in Kilograms")
We updated our existing Column name ‘Weight in Kg’, created in the previous section, into a new name ”Weight in Kilograms’. Here, we used the .withColumnRenamed() method to fulfill our needs. The .withColumnRenamed() method takes two arguments, first is the existing column name we want to update, second is the new column name we want to change into.
Checking the updated PySpark DataFrame
df.show()
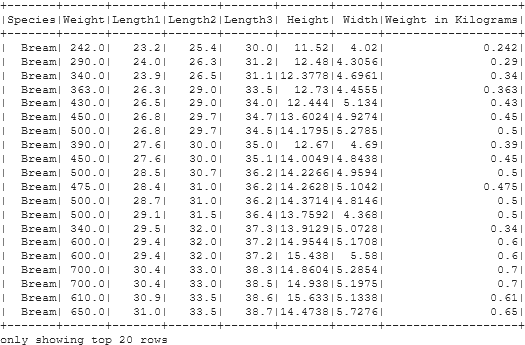
Selecting One or More Columns of PySpark DataFrame
In this section, we will see how to select columns in PySpark DataFrame. To select one or more columns of PySpark DataFrame, we will use the .select() method. This method is equivalent to the SQL SELECT clause which selects one or multiple columns at once.
Let us continue with the same updated DataFrame from the last step with renamed Column of Weights of Fishes in Kilograms.
Checking the Current PySpark DataFrame
df.show()
Selecting the Columns
df.select(df.Weight, df['Weight in Kilograms']).show()

Here, we used the .select() method to select the ‘Weight’ and ‘Weight in Kilogram’ columns from our previous PySpark DataFrame. The .select() method takes any number of arguments, each of them as Column names passed as strings separated by commas. Even if we pass the same column twice, the .show() method would display the column twice.
The select method returns a PySpark DataFrame, thus we have used the .show() method at the end to display the PySpark DataFrame.
Creating a Column Alias in PySpark DataFrame
To create an alias of a column, we will use the .alias() method. This method is SQL equivalent of the ‘AS‘ keyword which is used to create aliases. It gives a temporary name to our column of the output PySpark DataFrame.
Let us continue with the same updated DataFrame with renamed Column of Weights of Fishes in Kilograms.
Checking the Current PySpark DataFrame
df.show()

Creating Column Column Alias
df.select(df['Weight in Kilograms'].alias("Kilograms")).show()

Since, the .alias() method gives temporary name while selecting one or more columns, we will use the .alias() method along with .select() method. To give an alias to a column, simply add the .alias() method next to the column name.
Conclusions
In this article, we learned about the basic yet powerful PySpark column Operations to manipulate any PySpark DataFrame. These methods are one of the most must-have skills anyone should have. Most of the methods work similar to Pandas DataFrame and have method names similar to those used in SQL. A person having enough good expertise would require no time in learning these methods. Not to mention, all the methods used above can be used in a more optimized way. One can try using these methods in a more time and memory-conservative way.
References:
Image1: https://www.pexels.com/photo/photography-of-person-typing-1181675/
About the Author
Connect with me on LinkedIn.
For any suggestions or article requests, you can email me here.
Check out my other Articles Here and on Medium
You can provide your valuable feedback to me on LinkedIn.
Thanks for giving your time!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
IT Engineering Graduate currently pursuing Post Graduate Diploma in Data Science.





