This article was published as a part of the Data Science Blogathon
Introduction
Analyzing texts is far more complicated than analyzing typical tabulated data (e.g. retail data) because texts fall under unstructured data.
Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to texts and their choice of words may vary significantly without getting deviated from the theme. For example:
Statement 1: I liked the story of the movie
Statement 2: The plot of the movie is awesome and quite engaging
In the above two statements, the theme is the same (or rather similar) but, from a semantic point of view, the two statements are not the same. The second statement uses more words to express the same theme than the first one. It is quite easy to understand that even though both the statements are conveying similar meanings, they cannot be represented in a tabular format quite easily. This is just one of the many problems. Another issue with textual data is polysemy. For example:
Statement 3: The robbers tried to loot the bank but failed
Statement 4: The robbers followed the bank of the river to avoid the police
Apparently the chunk ‘the bank’ has a different meaning in the above two sentences. This is the polysemy issue. Focusing only on the word, without considering the context, would lead to an inappropriate inference. In the same way, synonyms may create some issues. In fact, the data available in the real world in textual format are quite noisy and contain several issues. This makes the analysis of texts much more complicated than analyzing the structured tabular data. This tutorial will try to focus on one of the many methods available to tame textual data. This is called Latent Semantic Analysis (LSA).
What is Latent Semantic Analysis (LSA)?
Latent Semantic Analysis (LSA) involves creating structured data from a collection of unstructured texts. Before getting into the concept of LSA, let us have a quick intuitive understanding of the concept. When we write anything like text, the words are not chosen randomly from a vocabulary.
Rather, we think about a theme (or topic) and then chose words such that we can express our thoughts to others in a more meaningful way. This theme or topic is usually considered as a latent dimension.
It is latent because we can’t see the dimension explicitly. Rather, we understand it only after going through the text. This means that most of the words are semantically linked to other words to express a theme. So, if words are occurring in a collection of documents with varying frequencies, it should indicate how different people try to express themselves using different words and different topics or themes.
In other words, word frequencies in different documents play a key role in extracting the latent topics. LSA tries to extract the dimensions using a machine learning algorithm called Singular Value Decomposition or SVD.
What is Singular Value Decomposition (SVD)?
Singular Value Decomposition or SVD is essentially a matrix factorization technique. In this method, any matrix can be decomposed into three parts as shown below.
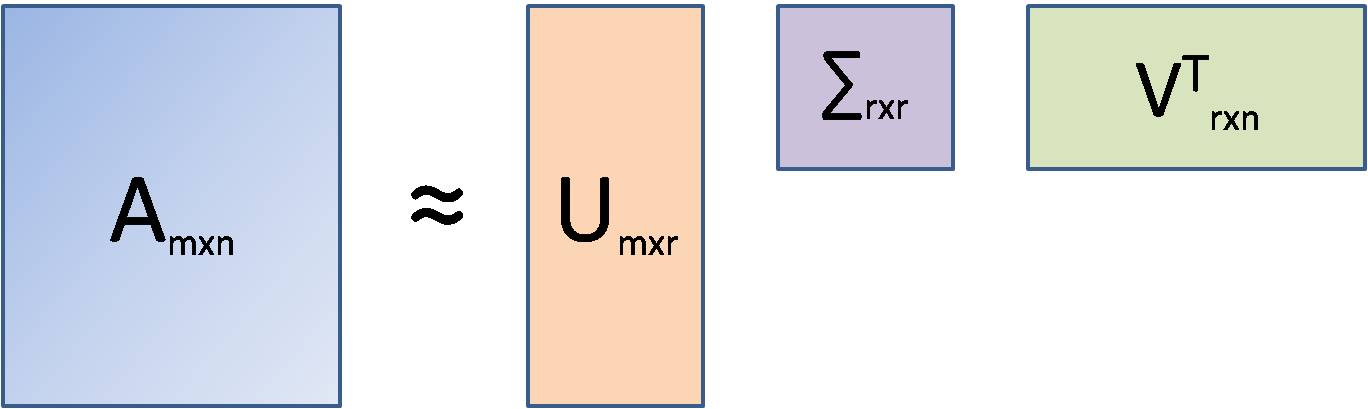
Here, A is the document-term matrix (documents in the rows(m), unique words in the columns(n), and frequencies at the intersections of documents and words). It is to be kept in mind that in LSA, the original document-term matrix is approximated by way of multiplying three other matrices, i.e., U, ∑ and VT. Here, r is the number of aspects or topics. Once we fix r (r<<n) and run SVD, the outcome that comes out is called Truncated SVD and LSA is essentially a truncated SVD only.
SVD is used in such situations because, unlike PCA, SVD does not require a correlation matrix or a covariance matrix to decompose. In that sense, SVD is free from any normality assumption of data (covariance calculation assumes a normal distribution of data). The U matrix is the document-aspect matrix, V is the word-aspect matrix, and ∑ is the diagonal matrix of the singular values. Similar to PCA, SVD also combines columns of the original matrix linearly to arrive at the U matrix. To arrive at the V matrix, SVD combines the rows of the original matrix linearly. Thus, from a sparse document-term matrix, it is possible to get a dense document-aspect matrix that can be used for either document clustering or document classification using available ML tools. The V matrix, on the other hand, is the word embedding matrix (i.e. each and every word is expressed by r floating-point numbers) and this matrix can be used in other sequential modeling tasks. However, for such tasks, Word2Vec and Glove vectors are available which are more popular.
Python Codes for Latent Semantic Analysis
For this tutorial, we are going to use the BBC news data which can be downloaded from here. This dataset contains raw texts related to 5 different categories such as business, entertainment, politics, sports, and tech. Our first task is to read the data from the raw text files.
!wget http://mlg.ucd.ie/files/datasets/bbc-fulltext.zip
!unzip bbc-fulltext.zip
import pandas as pd
import os, re
# Read each file as text files and put in a data frame
folders = os.listdir('/content/bbc/')
folders
# OUTPUT: ['business', 'entertainment', 'README.TXT', 'sport', 'tech', 'politics']
As can be seen in the output, there is a ‘README.TXT’ file available which is to be discarded. All other elements are the respective folders. Each folder has raw text files on the respective topic as appearing in the name of the folder. The next piece of code will create the data frame.
folders = os.listdir('/content/bbc/')
folders.remove('README.TXT')
df_dict = {'topic':[], 'news':[]}
for folder in folders:
files = os.listdir('/content/bbc/'+folder)
for file in files:
path = '/content/bbc/'+folder+'/'+file
f = open(path, 'r', errors='ignore').read()
df_dict['topic'].append(folder)
df_dict['news'].append(str(f))
df = pd.DataFrame(df_dict)
df.head()
The news column contains the texts which require some preprocessing before further analysis. Preprocessing would involve steps like
- Case conversion
- Removal of special characters and numbers (if any)
Using the RE package this processing can be done easily. A convenient function can do preprocessing and, as the data contain news heading, the function will return both the heading as well as the actual news content from individual texts. The codes are given below:
def simple_preprocessing(text):
heading = re.findall("^.+(?=\n)", text) # Extract the first line as heading
text = re.sub(heading[0], '', text) # Remove the heading
text = re.sub('\n', ' ', text) # Replace newline character with whitespace
text = re.sub('[$(.%),;!?]+','', text) # Remove common punctuations
text = text.strip() # Remove leading and training whitespaces
return (heading[0], text)
news_and_heading = [simple_preprocessing(txt.lower()) for txt in df['news']]
df_final = pd.concat([df, pd.DataFrame.from_records(news_and_heading,
columns=['Heading','News'])],
axis=1)
Latent semantic analysis (LSA) can be done on the ‘Headings’ or on the ‘News’ column. Since the ‘News’ column contains more texts, we would use this column for our analysis. Since LSA is essentially a truncated SVD, we can use LSA for document-level analysis such as document clustering, document classification, etc or we can also build word vectors for word-level analysis.
Document Clustering for Latent Semantic Analysis
Document clustering is helpful in many ways to cluster documents based on their similarities with each other. They are useful in law firms, medical record segregation, segregation of books, and in many different scenarios. Clustering algorithms are usually meant to deal with dense matrix and not sparse matrix which is created during the creation of document term matrix. Using LSA, a low-rank approximation of the original matrix can be created (with some loss of information although!) that can be used for our clustering purpose. The following codes show how to create the document-term matrix and how LSA can be used for document clustering.
from sklearn.feature_extraction.text import CountVectorizer import nltk from sklearn.decomposition import TruncatedSVD from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score from sklearn.manifold import TSNE from sklearn.preprocessing import LabelEncoder from nltk.corpus import stopwords import matplotlib.pyplot as plt import seaborn as sns from tqdm import tqdm, tqdm_notebook
stopword_list = stopwords.words('english')
dtm = CountVectorizer(max_df=0.7, min_df=5, token_pattern="[a-z']+",
stop_words=stopword_list, max_features=2000) # Only top 2000 most frequently ocurring words are considered
dtm.fit(df_final['News'])
dtm_mat = dtm.transform(df_final['News'])
tsvd = TruncatedSVD(n_components=200)
tsvd.fit(dtm_mat)
tsvd_mat = tsvd.transform(dtm_mat)
s_list = []
for clus in tqdm(range(2,21)):
km = KMeans(n_clusters=clus, n_init=50, max_iter=1000) # Instantiate KMeans clustering
km.fit(tsvd_mat) # Run KMeans clustering
s = silhouette_score(tsvd_mat, km.labels_)
s_list.append(s)
plt.plot(range(2,21), s_list) plt.show()
The line plot showing Silhouette scores at different numbers of clusters is shown below:
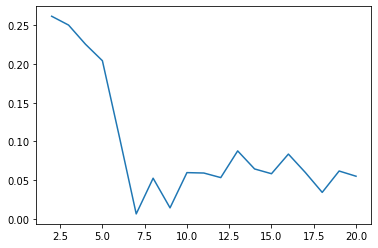
The plot shows clearly that the silhouette scores are quite low. Thus, either the clusters are not linearly separable or there is a considerable amount of overlaps among them. A TSNE plot is better suited in such a case. The TSNE plot extracts a low dimensional representation of high dimensional data through a non-linear embedding method which tries to retain the local structure of the data. The code as well as the TSNE plot is shown below.
tsne = TSNE(n_components=2) tsne_mat = tsne.fit_transform(tsvd_mat)
plt.figure(figsize=(10,8)) sns.scatterplot(tsne_mat[:,0],tsne_mat[:,1],hue=df_final['topic'])
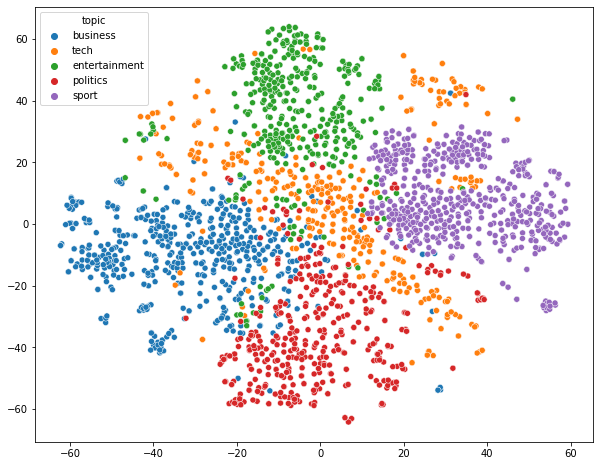
In this plot, only the tech-related news article looks like having a much wider spread whereas other news articles look quite nicely clustered. It also suggests that LSA (or Truncated SVD) has done a good job on the textual data to extract 200 important dimensions to segregate news articles on different topics. It is to be understood that TSNE is non-deterministic in nature and multiple runs will produce multiple representations, even though, the structure will be more likely to remain similar if not the same. This LSA can be also used for text queries, for example,
Query: “How is Microsoft performing in computer game?”
This query can be sent through the pipeline of document-term matrix creation which would be followed by LSA operation to create the necessary document vector and that can be compared with the vectors of news articles. The following codes show that result:
from sklearn.metrics import pairwise_distances import numpy as np query = "How is Microsoft performing in computer game?" query_mat = tsvd.transform(dtm.transform([query])) dist = pairwise_distances(X=tsvd_mat, Y=query_mat, metric='cosine') df_final['News'][np.argmin(dist.flatten())]
Output: xbox video game halo 2 has been released in the us on 9 november with a uk release two days later why is the game among the most anticipated of all time halo is considered by many video game pundits to be one of the finest examples of interactive entertainment ever produced and more than 15 million people worldwide have pre-ordered the sequel a science fiction epic halo centred the action on a human cyborg controlled by the player who had to save his crew from an alien horde after a crash landing on a strange and exotic world contained on the interior surface of a giant ring in space remembrance of things past it was not – but as a slice of schlock science fiction inspired by works such as larry niven’s ringworld and the film starship troopers it fit the bill perfectly halo stood out from a crowd of similar titles…(More)
Conclusion
The above outcome shows how correctly LSA could extract the most relevant document. However, as mentioned earlier, there are other word vectors available that can produce more interesting results but, when dealing with relatively smaller data, LSA-based document vector creation can be quite helpful.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
I am Subhasis Dasgupta, Associate Professor, Data Science, Praxis Business School, Kolkata. I am inclined towards learning and everyday I try to learn something new or try to hone my existing skills. I am also interested in Deep Learning and latest advancements in the area of Large Language Model. Finally, what I learn, I try to spread it so that the flow of knowledge never stops. My blogs are my attempts to spread my knowledge to the larger community.






Hi, this is a very interesting article. I have a question, can I use this model to train it with my own data set? My idea is to validate the semantic description of an automatically generated medical text regards
Hi, LSA is powerful and it can be used in different domains as well. So, if you have a reasonably large text corpus, you should get a good result.