This article was published as a part of the Data Science Blogathon
Introduction
The deep learning algorithms required the data in a specific order or shape. First, we have to arrange the data in batches, then we have to feed the batched data to the model in the epoch loop.
You will learn through this article (1) how to arrange the data with the help of the Torch library. (2) Early and lazy loading of data. Early loading is to load the entire data into the memory before the training.
In your data science career, you may have to deal with large data that has a size more than the size of your computer memory.
In short, if you have data in GBs you can not load the entire data at once. I also faced the same problem sometimes back. This is the reason I am sharing my experience here. The solution is simple but a bit tricky and called lazy loading, and we will learn this particular solution to this problem here. So in the next few minutes, you will get a complete understanding of how to use the Torch dataset class more efficiently than before.
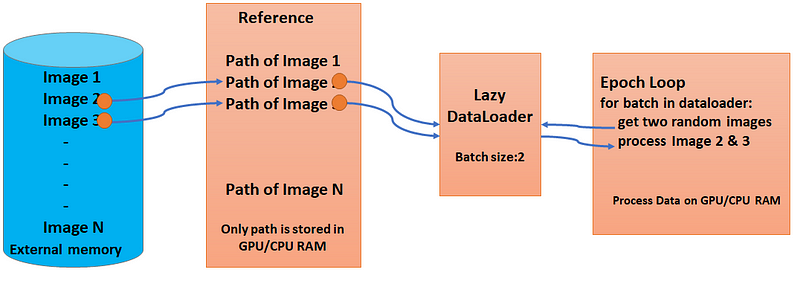
Lazy Loader (Image by Author)
What is the Torch Dataset?
Before jumping directly into the customization part of the Dataset class, let’s discuss the simple TensorDataset class of PyTorch. If you are already familiar with the basics of the TensorDataset of PyTorch library, you can ignore this explanation and directly jump to the Custom Dataset section. Suppose you have a list of inputs and a list of labels(target). What I mean is basically a one-one mapping between input data and the target data(for example one image is labelled with a class).
If you are confused with this one-to-one mapping you can refer to this article of RNN. In this case, you should use the TensorDataset class directly. Let’s create our inputs and labels with a simple example where a row of 5 * 3 matrix represents our input data sample with a sample size of 5 and 5 elements in our target data. Before proceeding, I want to tell you that Torch operations are similar to NumPy and Torch processes its data in its native format(tensor).
import torch
inp = torch.arange(1,16).reshape(5,3)
label = torch.randint(1,3,size=(5,))
print(inp)
print(label)
output:
tensor([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12],
[13, 14, 15]])
tensor([2, 1, 2, 2, 2])
To create Torch Dataset just pass your input and labels in the TensorDataset class and it will give you all your data samples in torch tensor form. Let’s have a look :
ds = TensorDataset(inp, label)
for inp, label in ds:
print('{}:{}'.format(inp, label))
#Output
tensor([1, 2, 3]):1
tensor([4, 5, 6]):2
tensor([7, 8, 9]):1
tensor([10, 11, 12]):2
tensor([13, 14, 15]):2
What is the Torch Dataloader?
DataLoader class arranged your dataset class into small batches. The good practice is that never arrange your data as it is. You have to apply some randomization techniques while picking the data sample from your data store (data sampling)and this randomization will really help you in good model building. Let’s see how the Dataloader class works.
dl = DataLoader(ds, batch_size=2)
for inp, label in dl:
print('{}:{}'.format(inp, label))
output:
tensor([[1, 2, 3],
[4, 5, 6]]):tensor([1, 2])
tensor([[ 7, 8, 9],
[10, 11, 12]]):tensor([1, 2])
tensor([[13, 14, 15]]):tensor([1])
As you can see in the above code Dataloader loaded our data into fixed-size batches (except the last one) with correct labeling in a sequential fashion. There are common sampling methods in Dataloader class for example if you pass the shuffle argument in the function then random shuffling batches will be generated.
dl = DataLoader(ds, batch_size=2, shuffle=True)
for inp, label in dl:
print('{}:{}'.format(inp, label))
output:
tensor([[10, 11, 12],
[ 1, 2, 3]]):tensor([2, 1])
tensor([[13, 14, 15],
[ 7, 8, 9]]):tensor([1, 2])
tensor([[4, 5, 6]]):tensor([1])
If you have Cuda in your machine and you want to transfer your data from CPU to GPU memory during the training time then in that case you can enable pin_memory=True, this will transfer the data in page-locked memory and with this approach, you can enhance the training speed. That’s it, your data is ready for training your neural network.
Custom dataset for large data
Now as we have seen the TensorDataset class so we can move further from the basic dataset. I will try to explain this section with the CIFAR-10 example but you can get the idea and solve your problem in your application. CIFAR-10 has 10 different classes of aeroplane, bird, cat, etc. The training directory has the following structure:
- Root Directory — Train
- Sub directory — Airplane, Bird, Cat …….(10 folders)
- Each folder contains 5000 images
To make a custom Dataset class: Make 3 abstract methods which are must
- __init__: This method runs once when we call this class, and we pass the data or its references here with the label data.
- __getitem__: This function returns one input and corresponding label at a time.
- __len__: This is to be defined to create the upper bound of the data or you can say it just returns the size of the data set.
We need to be careful in the __init__ function. Do not read whole data in the __init__ function if your data is very large to fit into memory. Store the references or indices of your data in __init__ function and load it into memory only when you actually require the data, yes inside your epoch loop. This way you can overcome the memory issue for large data.
But on the other hand, if you load the entire data in the init function then the getitem function will fetch the data directly from your CPU or GPU memory and the training speed will be faster. This all depends upon your dataset size and your requirement. But if you want to use less memory then lazily feed the data into memory as described here.
from torch.utils.data import Dataset, DataLoader, TensorDataset import glob from PIL import Image
class MyDaatset(Dataset):
def __init__(self, path, transform):
self.files = glob.glob(path)
print(type(self.files))
self.transform = transform
self.labels = [filepath.split('/')[-2] for filepath in self.files]
def __getitem__(self, item):
file = self.files[item]
label = self.labels[item]
file = Image.open(file)
file = self.transform(file)
return file, label
def __len__(self):
return len(self.files)
__init__: In __init__ we just storing the file paths in self.files object. What we need for the training is all the data samples and the corresponding labels but here we are not storing the input but we are storing only input’s references and we will use these references later in getitme function to load the data into memory, we are also storing the labels for all the data samples for this we are splitting the path from the references and get the sub-directory name like an airplane, Bird, etc as mentioned in above code. We should map it to integer values (because Neural Net is the only friend of numerical data) I leave this to you. A Transform function is needed to convert a PIL image to a tensor.
__len__: In the function __len__ we have to return just the actual length of the entire data that’s actually the total size of the data set.
__getitem__: The way we want our data, that way we need to implement the logic in this function. Here we have to map one image file to its corresponding label at a time. To achieve this we are calling the open and transform function on the image data, then we are converting the image into a torch tensor (we need to convert data into a tensor for training) and at last, we are returning the image with the corresponding label.
This is the way we can save our memory from overflowing. We shift our data to memory only when we need that particular data. I mean when we iterate our dataloader during training time, only that time our data will load into the memory.
from torchvision import transforms path = '/cifar10/train/*/*' transform=transforms.Compose([transforms.ToTensor()]) cifar_ds = MyDaatset(path, transform) cifar_dl = DataLoader(cifar_ds, batch_size=100, shuffle=True)
In the above code we have defined our transform function which transforms our image data into tensor data, call our custom dataset class as cifar_ds, then initialize the function DataLoader as cifar_dl with batch size as 100. Point to note here you have to choose your batch size wisely because it acts as a hyperparameter and it is also related to your memory size, if you have lower memory you can not choose a larger batch size. The main task of DataLoader is to create batches for our data with some sampling techniques as we discussed in the Dataloader section above.
Visualizing the data
If we want to verify our data, we can see it with torchvision and matplotlib. This will really help you when you are working in a Colab or Kaggle notebook and you want to see your data.
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
for images, labels in cifar_dl:
plt.imshow(make_grid(images, 10).permute(1,2,0))# 4 batch_size
plt.show()
Load data dynamically while training
Now we are ready for the training, I am not focusing on writing the training code. The below code is just an idea to iterate your own Dataloader during the training. When the Dataloader will call the getitem function of the dataset class, only that time it will fetch that data into memory.
for epoch in range(num_epochs):
for batch in cifar_dl:
//pass the data to the model
Conclusion
I really appreciate Torch that reduced our effort in designing the input pipeline for the model. Dataset and Datloader classes are very simple to use. The only thing you have to decide is when to load your data into the GPU/CPU memory. Early loading will boost the epoch loop speed only if you have no memory constraints. Lazy loading of data in getitme method will help you to handle a very large data set. I hope this article made your understanding much better of the Torch Dataset and Dataloader classes. Same approach you can use even in large textual data set in NLP problems.




