Introduction to Human Perception and Speech
I am always fascinated by speech processing. In recent years I started to dig deep into Speech related subjects. So, I thought to write my experience and learnings over here. My objective here is to give you guys my perspective based on Speech Processing.
First, let me tell you about what is “sound to us.” If you think about that, I will give you a boring mathematical quantification or definition of sound you’re mistaken. 3 -4 years back, I read a book by Yuval Noah Harari, “Sapiens: A brief history of humankind.” One particular line caught my attention, ” There are no gods, no nation, no money, and no human rights except our collective imaginations.” It is a weighty, meaningful line. So what is imagination?
What is Perception and Imagination?
I know Ed Sheeran is an extraordinary singer. So I went to one of his concerts after paying a very hefty amount for the ticket. How do I know Ed is a remarkable singer? Well, I was listening to his songs for quite some time. Especially his song like “Perfect’,” Shape of You,” and “Castle on the hill.” I looped it back numerous times. So based on these data, my judgment is he is an extraordinary singer. Also, This experience data is helping me to draw a picture that the concert will be fantastic irrespective of the actual outcome.
So while I said that “drawing a picture that the concert will be fantastic.” That’s my imagination, for which the outcome is unpredictable. But from where is this image coming? Well, somewhere in my mind, Ed Sheeran’s songs have created a satisfaction that gave me the instantaneous boost of serotonin-like happy hormones. Now that’s my perception about Ed Sheeran’s songs, which leads me to imagine the concert will be great. So perception is acknowledging something that exists.
Few things about perception. Do you like and loopback all the available songs by your favorite singer, or do you loop back a bunch of particular music of your favorite singer? We listen to some selective songs of our favorite singer. So perception has a “Limited selective weightage set.” Also, two people whose favorite singer is Ed Sheeran can have a different set of this limited selective weightage set.
Weber Fincher Law
What is this “Limited selective weightage set?” Let’s say you have 20 cards, and some steal five cards from it. You will notice it when next time you are going to play with it. But let’s say you have 20,000 cards, and then five cards are stolen. How often will you notice that five are missing? It leads us to Weber–Fechner law. Weber states that “the minimum increase of stimulus which will produce a perceptible increase of sensation is proportional to the pre-existent stimulus.”
At the same time, Fechner’s law is an inference from Weber’s law (with additional assumptions) which states that the intensity of our sensation increases as the logarithm of an increase in energy rather than as rapidly as the increase. These laws are fundamental to the understanding of sound perception.
Let’s look at Weber’s Law mathematically.
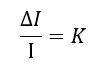
Where ΔI represents the difference threshold, I describe the initial stimulus intensity, and K Signifies that the proportion on the left side of the equation remains constant despite variation in the I terms.
Then what is Weber Fincher Law?
The rate of impulse discharge from a receptor is directly proportional with the log intensity of the stimulus
Where,
R=Rate of impulse discharge.
S=Strength of stimulus.
K=Constant
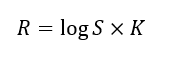
Folks are familiar with the “SCRUM poker game”; they know we use the Fibonacci series to prioritize user stories. Why not a regular sequence of numbers? Or an arrangement of even or odd numbers? The reason is Weber–Fechner law. The Fibonacci sequence is a nonlinear lagging exponential sequence. So the prioritizing idea with the Fibonacci series becomes realistic according to the Weber–Fechner laws of human perception. But if we use a continuous sequence like 1,2,3, it will follow linearity, so it is not that realistic for human perception. So prioritizing can be ward off from reality.
Perception of Speech
Speech signal emerges from a speaker’s mouth, nose, and cheeks; it is a one-dimensional function (air pressure) of time. Microphones convert the fluctuating air pressure into electrical signals, voltages, or currents, in which form we usually deal with speech signals in speech processing. While we are speaking, we are generating multiple frequency components. Well, what is frequency components?
Let me ask you a question. How many times in a day do you check your Facebook or Instagram? If the answer is 5 for Facebook and 10 for Instagram. Then it’s your frequency of checking Facebook or Instagram per day. If I ask you how frequently you visit social networking sites in a day, you can describe these prementioned frequencies. A similar kind of thing happens while we speak a word or sentence. Those frequencies have some values in a speech signal and a pattern. The below picture is a representation of Speech in the Time-Amplitude domain consisting of multiple frequencies.
Sentence Spoken in Here is “Hello World.” The representation looks complex, right? How can I guess the frequencies? It seems too much data in the time domain. How can I know the frequencies? Humans can perceive a value as “A Big team” or “A small Team”; it does not mean anything until we quantify it. A team of 2 is smaller than a team of 5. A group of 4 is bigger than 2 but smaller than 5.
Quantification gives us information to build our perception. So we need to quantify the frequencies within the Speech. But it’s not the only reason. Humans are imperfect at perceiving time. Interesting right? Well, in college, some of us love to bunk classes to go out for a movie or game, or party. Most of these guys can tell you a rough estimation of how many times did they bunk classes (frequency).
But they will be unable to tell you which day which time they did that. Maybe this is the reason we say, “Time heals everything.” Or “Public has a concise memory.” Perceptually we are oblivious to the time. As time passes, we become perceptually more oblivious. It is the reason in application fields like the Telecom domain. We don’t process our signal in the Time domain; all the filtering, encoding, Convolution, etc., are done in the frequency domain.

There are various mathematical methods available converting time-domain data representation to frequency domain representation.

For me, Laplace and Z transformation is a little bit fuzzy as they do not always have an Exact physical interpretation. If you have more excellent perception and imagination of differential equations, then it’s a valuable tool. But also, we need to remember that These transformations are somewhat related to each other.
Lossy Nature of Speech Perception
We will talk about Fourier transformation; a nonperiodic signal like Speech can be decomposed into a sine wave of continuous frequency from 0 to infinity as per Fourier transformation.
Now, if we perform this operation on our Prementioned Speech sample “Hello World,” it looks below.

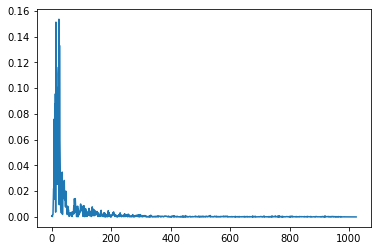
We can see there are lots of frequencies component. Are all these frequency components helpful for human perception of Speech? The ‘normal’ hearing frequency range of a healthy young person is about 20 to 20,000Hz. But for perception, it remains linear between 0- 1000 Hz, but it becomes logarithmic after 1000Hz. So you won’t differentiate sound between 10000Hz and 10010Hz. It is why all the ASR systems in their initial Digital Signal Processing feature extraction part use a masking filter that internally converts the frequencies of how a human perceives sound. These filters are MFCC, GFCC,PLP etc. See the below formula, how MFCC is using the logarithmic scale.
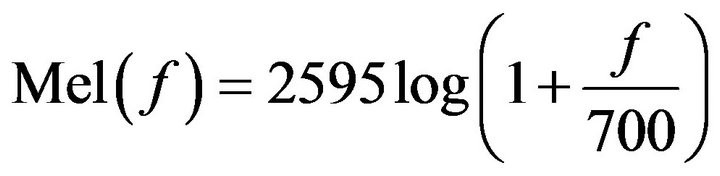
Issue related to lossy Speech Perception
Due to the above incapability of perception, we don’t perceive whispering speech. Also, apart from that, the understandability of Speech perception depends upon some other pre-learned data. Like we know, we have native and nonnative speakers for a particular language; below is one data for the same.

For Native speakers, while they learn a second language(L2), the impact of their first language(L1) can be seen during the articulation of L2. Or sometimes, one language has a different articulation and phonetics style. For English, there are two main segments like UK English and American English. Received Pronunciation(RP) is the most common English accent you’ll encounter when learning British English. In BBC News, the type of English. Understanding RP is going to help you distinguish between British and American accents. For instance, In RP, the letter “r” is pronounced very softly at the end of a word. For example, with a British accent, pronouncing the letter “r” barely happens. Like, in the word ‘Pork.’ You can even consider it a “silent r” in this context. A British person would pronounce the word water, whereas an American would say something closer to “wah-der.”
All these styles become challenging for speech perception. To remove that, some social network sites like LinkedIn have added a particular segment where people can utter their names and get the correct pronunciation.
Conclusion
So I have discussed human incapability of time perception and capability of frequency perception. Also, I have given a notion of how the psychoacoustic nature of humans works. The famous English poet William Blake once wrote, “If the doors of perception were cleansed, everything would appear to a man as it is, infinity.” Just think about that if we could have heard all the frequency components linearly and could distinguish each other, we could probably have understood Speech a lot more than what we do now. Also, I like to mention that, as I said before, we can not perceive the time domain correctly. A great man like Einstein had a mentality to perceive time as the fourth dimension!! Is it not a genius imaginativeness toward infinity?
Reference
[1]https://premieragile.com/why-are-fibonacci-numbers-used-in-story-point-estimation/#:~:text=Using%20the%20Fibonacci%20series%20turns%20out%20to%20be,number%20of%20the%20analogous%20bucket%20in%20the%20backlog.[2]Schroeder M.R. (1999) The Speech Signal. In: Computer Speech. Springer Series in Information Sciences, vol 35. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-662-03861-1_7
[3] https://lemongrad.com/english-language-statistics/
[4] https://en.wikipedia.org/wiki/Weber%E2%80%93Fechner_law



