Introduction
In our quest for precise fitness tracking, the integration of Kalman filters into smartwatch technology has ushered in a new era of accuracy in monitoring physical metrics like steps taken, calorie expenditure, and heart rate. However, skepticism often arises when discrepancies occur between sensor data and actual measurements. For instance, consider the scenario of counting steps during a jog—while physical observations suggest one count, sensor readings may indicate another.
This article delves into the indispensable role of Kalman filters in reconciling such disparities, providing an insightful exploration of their functionality and applications in enhancing fitness metrics. Through a comprehensive examination of Kalman filters, we aim to shed light on their significance in bridging the gap between sensor data and real-world observations, thereby revolutionizing how we perceive and utilize fitness tracking technology.

Learning Outcomes
- Understand the fundamental principles behind Kalman filters and their significance in signal processing and state estimation.
- Gain insights into the integration of Kalman filters with smartwatch technology for enhancing accuracy in fitness tracking metrics.
- Learn how Kalman filters reconcile discrepancies between sensor data and physical measurements, thereby optimizing the estimation of system states.
- Explore practical applications of Kalman filters in various domains, including dynamic systems, Hidden Markov Models, and Measurement System Analysis.
- Acquire hands-on experience through coding examples, enabling the implementation of Kalman filters in real-world scenarios.
- Develop an appreciation for the versatility and effectiveness of Kalman filters in handling noise and uncertainty in measurements, leading to more accurate and efficient estimation outcomes.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Kalman Filter?
The Kalman filter is a fundamental tool in statistics and control theory, is an algorithm designed to estimate the state of a system by incorporating a sequence of measurements taken over time, accounting for statistical noise. It achieves this by combining the predicted state of the system and the latest measurement in a weighted average. These weights are assigned based on the relative uncertainty of the values, with more confidence placed in measurements with lower estimated uncertainty. This process is also referred to as linear quadratic estimation.
Linear Dynamical System for Kalman Filter
To know the usability of the Kalman Filter, we need to have a little bit of intuition about the Linear Dynamical System. A dynamical system evolves throughout time, so it’s a function of time. Most of the systems that we see in real life are dynamical systems. We have a particular branch of mathematics known as Calculus which describes a dynamic system very well. It works in the area where we deal with change rates overtime or any other parameters.
We call it a differential equation, right? So, if a set of differential equations describes a system, we call it a Linear Dynamic System. We must develop an algorithm to check an autonomous car’s position (latitude and longitude), direction, velocity, and other parameters. Now the position is nothing but a distance. And distance and velocity can be described with the help of differential equations, like rate of change in position or rate of change in direction or rate of change in velocity, etc.

Kalman Filter and Hidden Markov Model
The Kalman Filter is a method for solving the continuous version of Hidden Markov Models. Hidden Markov deals with latent variables. Let me give a little bit of intuition. When you see a happy face in a crowd, you don’t know the reason for their happiness. There can be many factors like the guy got a job, or meet someone, etc. these factors are latent or hidden because you see only the outcome(happiness).
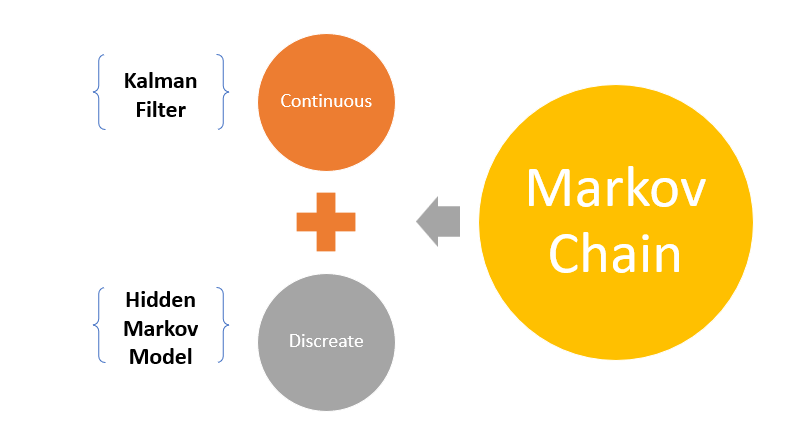
Markov chain says that only your present determines your future, not the past. For our happiness example with Hidden Markov Model, we want to determine the factors or variables(hidden) that cause feelings of happiness before the happy expression(outcome). I have written an article about Markov chain you can check that for more. Below I have given the link for the same.
In Hidden Markov Model, we assume the hidden state is one of a few classes, and the movement among these states uses a discrete Markov Chain. Whereas, in Kalman filters, we consider that the unobserved state distribution is Gaussian and moves continuously according to linear dynamics. So obviously, the precision will increase. In case we try to measure a value.
Measurement System Analysis and Kalman Filter
Machine learning models aim to predict or estimate values or classes close to accurate ones. Estimation is the evaluation of hidden state in a system, like accelerometer sensors in smartwatches or GPS sensors. Accuracy and precision are crucial, with higher precision resulting in lower variance and lower uncertainty. Random measurement error produces variance, which can be removed by averaging or smoothing measurements. To achieve closer estimation, more measurements data, particularly continuous hidden data, is needed, with Kalman filters advocating for this.
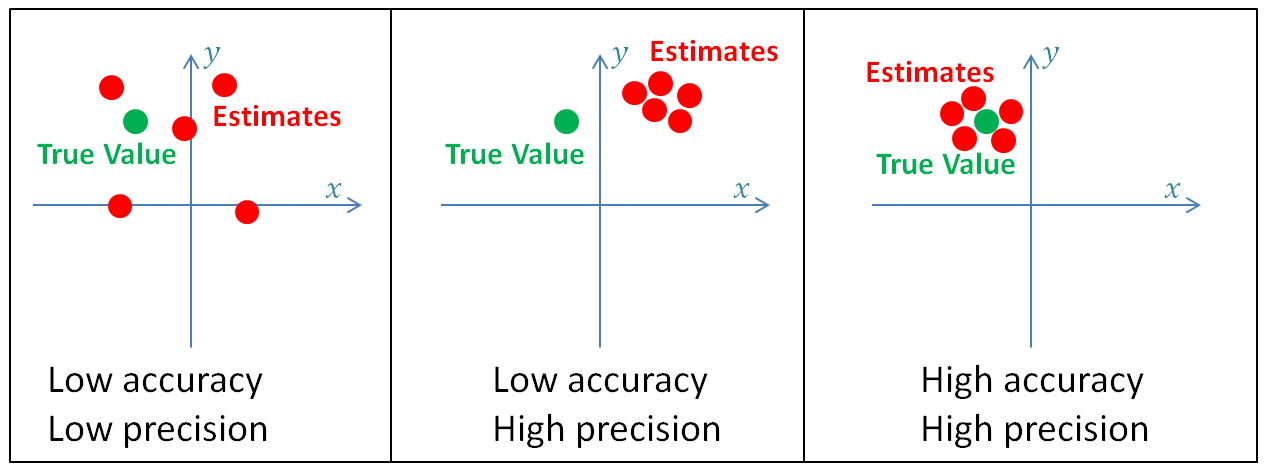
Why use Kalman Filters?
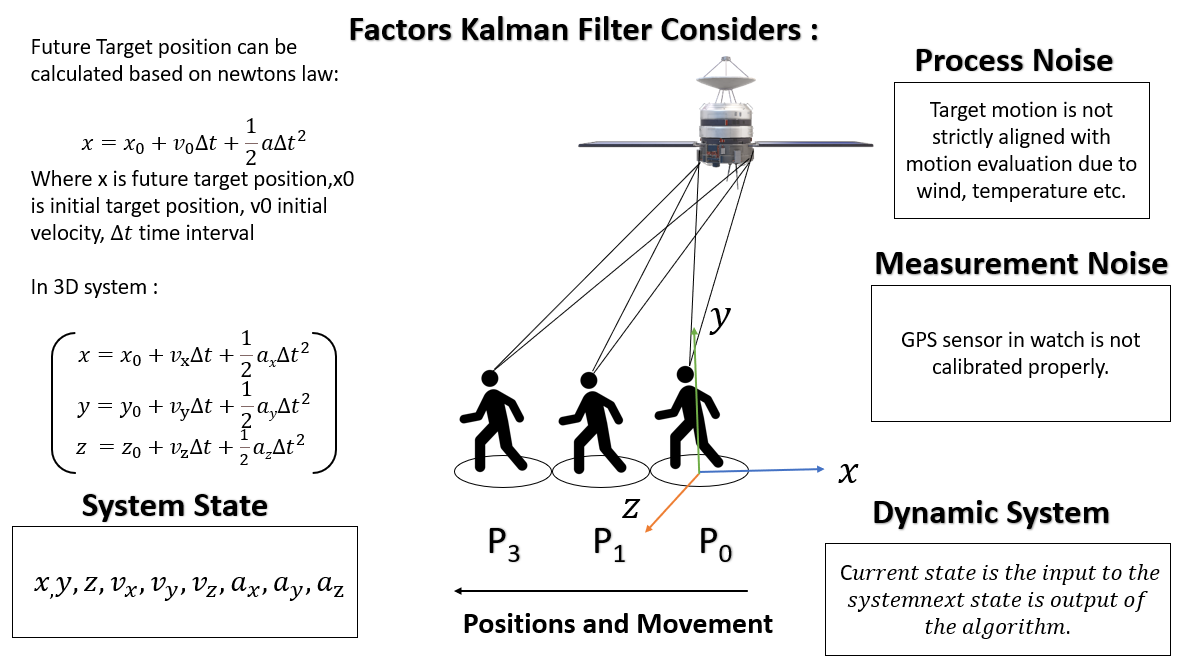
Let’s consider our first example. Our smartwatches have GPS sensors to track our physical movement during walking or running based on position or location coordinates. The most challenging part is giving you accurate and precise data—many external hidden factors like thermal noise, receiver clock precession, materials, GPS satellite location, etc., create problems in accuracy and precession. The Kalman filter Python estimates these hidden variables based on inaccurate and uncertain measurement, as it also provides a future state prediction based on the previous estimation. The below image gives some intuition of the factors that the Kalman filter considers.
Take another example of an Autonomous car. In an autonomous vehicle, inbuilt sensors determine the position of objects surrounding the vehicle. Also, a model that predicts the future positions of the objects. The issue with it in real-time system predictive model and sensors may not work well it leads to uncertainty. But with The Kalman filter, we can curb the uncertainty impact with the help of a distribution. More often, a gaussian distribution.
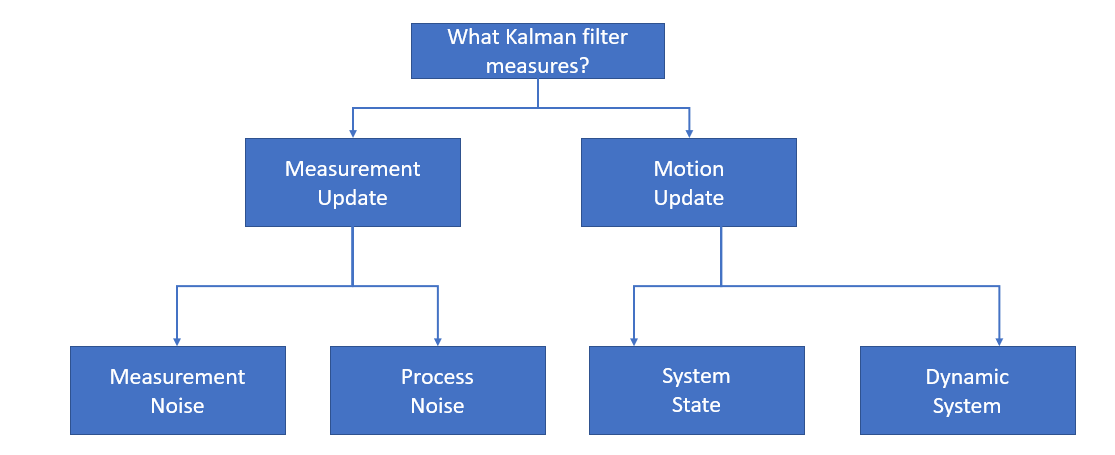
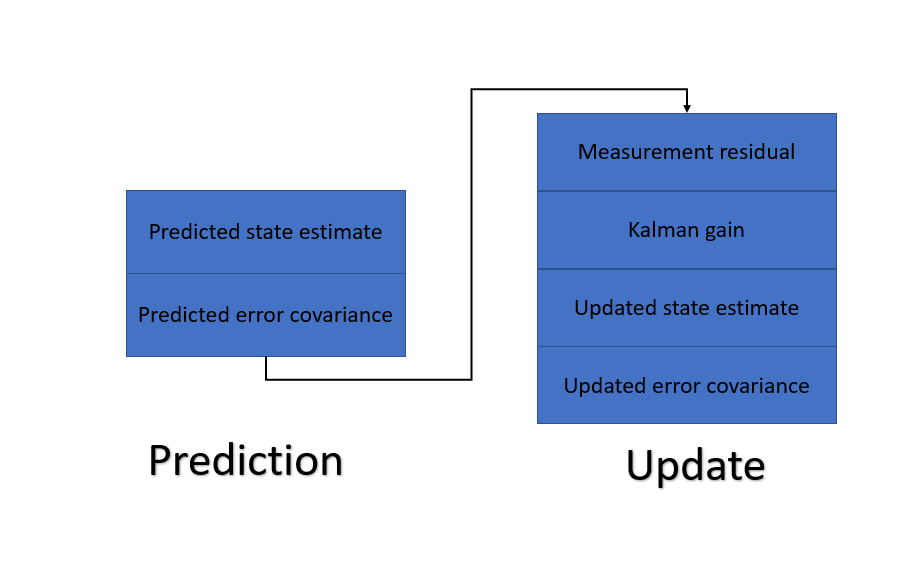
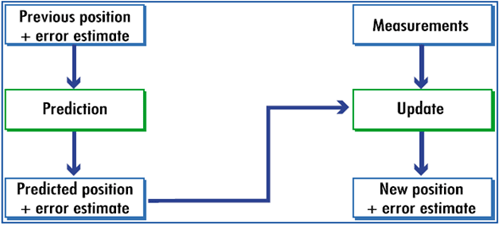
Internal Process of Kalman Filter
Kalman filter has two stages. It is a recursive process based on the continuous Markov chain. The two steps of it are two predicts and update. “prediction” and “update” are called “propagation” and “correlation.” Before we describe the process, lets us express one statistical term,’ Covariance.’ When we try to find the relation between two variables, we use two words Covariance and correlation. In the case of Covariance, we try to determine how much movement in one variable predicts the movement in corresponding variables. Covariance focuses on direction, not on strength. You can get some intuitive ideas from the below images about variance.

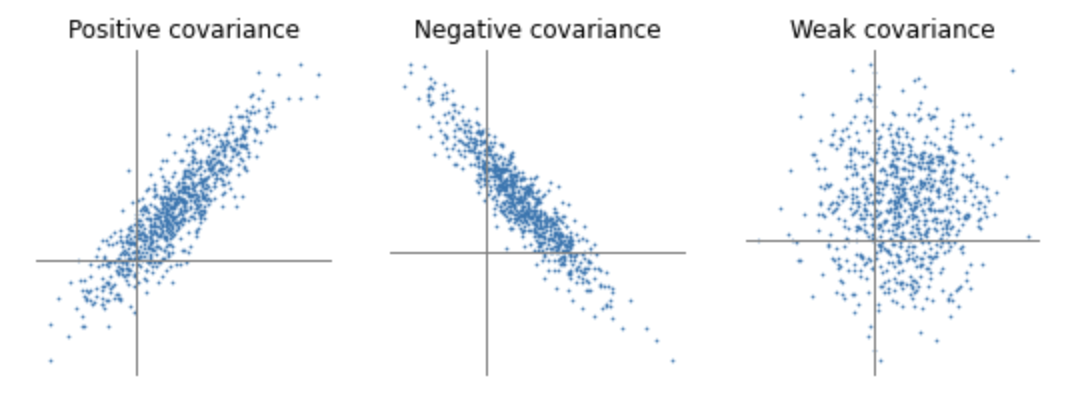
The Kalman Filter process model defines the evolution of the state from time t−1 to time t as:
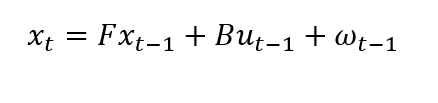
Here F is the state transition matrix that has been applied to the previous state vector xt−1 , B is the control-input matrix used to the control vector ut−1 , and wt−1 is the process noise vector considered zero-mean Gaussian with the covariance Q.

I won’t confuse you with the equations since the article is an intuitive picture of the Kalman filter. But one more important term I need to define without any equation. Calculating the Kalman gain(K) involved calculating the covariance matrix for the observation errors and comparing it with the process covariance matrix. In the case of Kalman Gain(K)–> 1, the measurements are accurate, but the estimates are unstable. A smaller value of Kalman gain means estimates are more stable, and the measurements are inaccurate.
Where to use Kalman filter
It is an exciting question that where the Kalman filter Python can be used. Everywhere. Any data capturing process can use the Kalman filter. Like Sensors, as we are not sure if the sensor’s measurement data is right or wrong. Data capturing during speech and image processing. Most of the uses case can be found in Space related activities.
Code:
#Install(in Windows) :
pip install filterpy#Considering a filter that tracks position and velocity using a sensor. only reads position:
from filterpy.kalman import KalmanFilter
f = KalmanFilter (dim_x=2, dim_y=1)#Assign some initial value for the state (position and velocity):
f.x = np.array([[2.], # position
[0.]]) # velocity#Define the state transition matrix:
f.F = np.array([[1.,1.],
[0.,1.]])#Define the measurement function:
f.H = np.array([[1.,0.]])#Define the covariance matrix.
f.P = np.array([[1000., 0.],
[ 0., 1000.] ])#Assign the measurement noise.
f.R = np.array([[5.]])#Assign the process noise.
from filterpy.common import Q_discrete_white_noise
f.Q = Q_discrete_white_noise(dim=2, dt=0.1, var=0.13)#perform the predict/update loop:
z = get_sensor_reading()
f.predict()
f.update(z)
do_something_with_estimate (f.x)Conclusion
The Kalman filter is a versatile tool used in signal processing and state estimation. It’s integrated with smartwatch technology for fitness tracking and reconciles sensor data with physical measurements. Its adaptability allows it to work across domains like dynamic systems, Hidden Markov Models, and Measurement System Analysis. Practical coding examples help optimize accuracy and efficiency in estimation processes. The Kalman filter Python is reliable in data science and engineering, providing precise insights.
Key Takeaways
- Understand the fundamental principles of the Kalman filter, an algorithm used for state estimation in dynamic systems by combining measurements and predictions.
- Explore how Kalman filters are integrated into smartwatch technology to enhance the accuracy of fitness tracking metrics like steps taken, calorie expenditure, and heart rate monitoring.
- Learn how Kalman filters reconcile discrepancies between sensor data and physical measurements, providing more accurate and reliable estimation of system states.
- Discover the versatility of Kalman filters across various domains, including dynamic systems, Hidden Markov Models, and Measurement System Analysis, showcasing their adaptability to different applications.
- Gain hands-on experience through coding examples that demonstrate the practical implementation of Kalman filters, enabling optimization of accuracy and efficiency in estimation processes.
- Recognize the reliability of Kalman filters in data science and engineering, providing precise insights and enhancing performance in real-world scenarios.
Code Resource: https://filterpy.readthedocs.io/en/latest/kalman/KalmanFilter.html
Frequently Asked Questions
Q1. What is the Kalman filter Python used for?
A. The Kalman filter Python is used for state estimation in dynamic systems, combining measurements and predictions to provide accurate and efficient estimates of system states.
Q2. Why is Kalman filter so popular?
A. The Kalman filter is popular due to its effectiveness in estimating states, adaptability to various systems, and optimal performance in handling noise and uncertainty in measurements.
Q3. Is Kalman filter a machine learning algorithm?
A. The Kalman filter is not a traditional machine learning algorithm; it’s a recursive estimation method widely used in control systems and signal processing for real-time state estimation.
Q4. What does the Kalman filter minimize?
A. The Kalman filter minimizes the mean squared error between predicted and observed values, optimizing the estimation of the true state in dynamic systems.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.

