This article was published as a part of the Data Science Blogathon
Gathering and getting ready datasets is one of the critical techniques in any Machine learning project. People accumulate the dataset thru numerous approaches like databases, online repositories, APIs, survey forms, and many others. But when we want to extract any internet site data when no means of API is there then the best alternative left is Web Scraping.

In this article, you will learn about web scraping in brief and see how to extract data from websites with a hands-on demonstration with python. We will be covering the following topics.
Table of Contents
- What is Web Scraping
- Why is Web Scraping used
- Challenges and Guide for Web Scraping
- Python Libraries for Web Scraping
- Hands-on Web Scraping with Python
- Web Scraping using lxml
- Web Scraping using Scrapy
- End Notes
What is Web Scraping?
Web scraping is a simple technique that describes an automatic collection of a huge amount of data from websites. Data is of three types as structured, unstructured, and semi-structured. Websites hold all the types of data in an unstructured way web scraping is a technique that helps to collect this instructed data from websites and store it in a structured way. Today most of the corporate use web-scraping to leverage good business decisions in this comparative market. So let’s learn why and where web scraping is used the most.
Why is Web Scraping used?
We have already discussed that to automatically fetch data from websites web scraping is required but where it is used, And what is a requirement to do so? To better understand this let’s look at some applications of web scraping
- Price Comparison – Some various platforms and websites provide comparison, pros, and cons of different products of different companies on their platforms that make customer easy to choose the right product for them. Parsehub is a great example that compares the prices of various products from different shopping websites. College Dunia is another example that compares the rating, courses fee structure of different institutions.
- Research and Development – most of the websites use cookies, privacy policies. They scrape the user data like timestamp, time spent, etc to conduct various statistical analyses and manage customer relationships in a better way.
- Job Listing – many job portals display job openings in a different organization according to location, skills, etc. They scrape the data from the organization’s careers page to list many openings from different companies on one single platform.
- Email Gathering – companies that use email for marketing purposes use web scraping to gather lots of emails from different websites and send bulk emails.
Now I hope that it makes a clear understanding that why web scraping is necessary and use most, and this application widens your thought and you can think of many different applications it is used nowadays.
Challenges and Guide for Scraping
If you know HTML, and CSS then it is very to understand and perform web scrapping easily because in a nutshell by web scrapping we extract data of websites that return in an HTML doc form and CSS is to get specific data that we are looking for. And it is also important because web scrapping faces a little challenge.
- Variety – Each website is different which has different formatting, different templates. You need to inspect through website HTML to extract relevant information.
- Durability – Websites updates with time. new posting and formatting keep changing so once you had built a web scrapper and it runs flawlessly that does not mean that always after some time it will run fine.
But in this article, we will perform from ground level so you can follow it easily.
Python Libraries for web scraping
requests – It is the most basic library for web scraping. The request is a python in-built module that allows you to send an HTTP request like a GET, POST, etc to websites using python. Getting the HTML content of a web page is the first and foremost step of web scraping. Due to its ease of use, it comes as the motto of HTTP for humans. However, requests do not parse the retrieved HTML content. for that, we require other libraries.
Beautiful Soup(bs4) – Beautiful Soup is a Python library used for web scraping. It sits at a top of an HTML or XML parser which provides python idioms for iterating, searching, and modifying a parse tree. It automatically converts incoming documents to Unicode and outgoing documents to UTF-8. Beautiful Soup is easy to learn, robust, beginner-friendly and, the most used web scraping library in recent times with request.
pip install bs4
lxml – It is a high performance, fast HTML and XML parsing library. It is faster than a beautiful soup. It works well when we are aiming to scrape large datasets. It also allows you to extract data from HTML using XPath and CSS selectors.
pip install lxml
Scrapy – Scrapy is not just a library, it is a complete web scraping framework. Scrapy helps you to scrape a large amount of dataset efficiently and effectively. It can be used for a wide range of purposes, from data mining to monitoring and automated testing. Scrapy creates spiders that crawl across websites and retrieve the data. The best thing about scrapy is it is asynchronous, and with the help of spacy, you can make multiple HTTP requests simultaneously. You can also create a pipeline using scrapy.
pip install scrapy
Hands-on Web Scraping with Python
Problem Description
We are going to scrape the data from the Ambition box website. Ambition Box is a platform that lists job openings in different companies in India. If you visit the companies page you can observe the name of the company, rating, review, how old the company is, and different information about it. So we aim to get this data in a table format that consists of the name of the company, rating, review, company age, number of employees, etc information. There are about 33 pages and on each page, approximately 30 companies are listed and we want to fetch all the 33 pages of each company data in the dataframe.
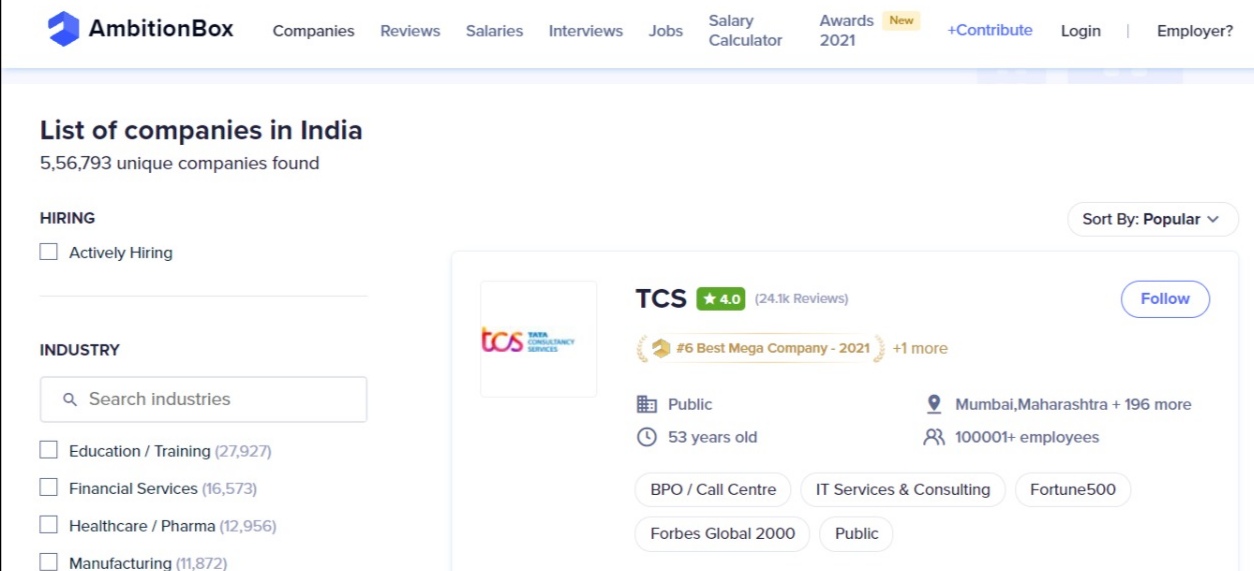
Let’s get started!
Import the libraries
Make a request
Now we will create an HTTP request to the Ambition Box website and it will give us a response HTML document content.
import pandas as pd
import requests
from bs4 import BeautifulSoup
import numpy as np
webpage=requests.get('https://www.ambitionbox.com/list-of-companies?page=1').text
Parse through response using beautiful soup
We have the HTML content, and to extract the data present in that we will use beautiful soup which creates a parser around it. If you print the parser output using prettify function then you can see the extracted document in a readable format.
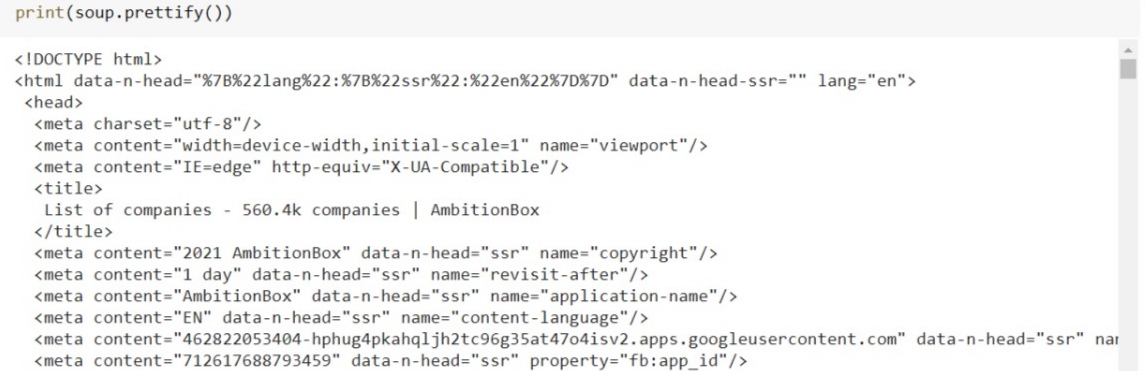
How we will find each text we need?
To get any name from an HTML document there is a special tag in which it is written. If you go on the website and right-click if you go on inspect section then you can see that each company’s information is in a separate division(div) tag. In that, there is a unique class or id to element so by using tag, class, id we can get the desired results. the heading is written in the H1 tag. for example if we want to access this then it’s easy.
soup.find_all('h1')[0].text
How to get the name of companies?
The names of all the companies are written in an H2 tag. we can run a loop and get all names of companies on the first page. when we write find all it extracts a list object and in that we access a zero-based index which is the title of the text and access the text written in that. Strip function is used to avoid the extra spaces that are used in a web page for design.

How to extract other details?
If you inspect on rating, review of companies then they all are written in paragraph(p) tag. Along with the paragraph tag, they are having a unique class name using which we can identify them. Rating is having rating class, reviews are having review class But company type, company age, headquarters location, and several employees are in the same tag and having the same class name. To access this we will use list indexing.
for i in soup.find_all('p'):
print(i.text.strip())
Creating a list of each feature
Now as we have seen we will access each feature using tag and class. so let us create a separate list of each feature whose length will be 30. first, we will store the list of all the 30 divisions means all company divisions in a variable, and apply a loop over it.
company=soup.find_all('div',class_='company-content-wrapper')
print(len(company)) #30
Now we can easily loop over the company variables and get all the information on the first page.
name = []
rating = []
reviews = []
comp_type = []
head_q = []
how_old = []
no_of_employees = []
for comp in company:
name.append(comp.find('h2').text.strip())
rating.append(comp.find('p', class_ = "rating").text.strip())
reviews.append(comp.find('a', class_ = "review-count").text.strip())
comp_type.append(comp.find_all('p', class_ = 'infoEntity')[0].text.strip())
head_q.append(comp.find_all('p',class_='infoEntity')[1].text.strip())
how_old.append(comp.find_all('p',class_='infoEntity')[2].text.strip())
no_of_employees.append(comp.find_all('p',class_='infoEntity')[3].text.strip())
#creating dataframe for all list
features = {'name':name, 'rating':rating,'reviews':reviews,
'company_type':comp_type,'Head_Quarters':head_q, 'Company_Age':how_old,
'No_of_Employee':no_of_employees }
df = pd.DataFrame(features)
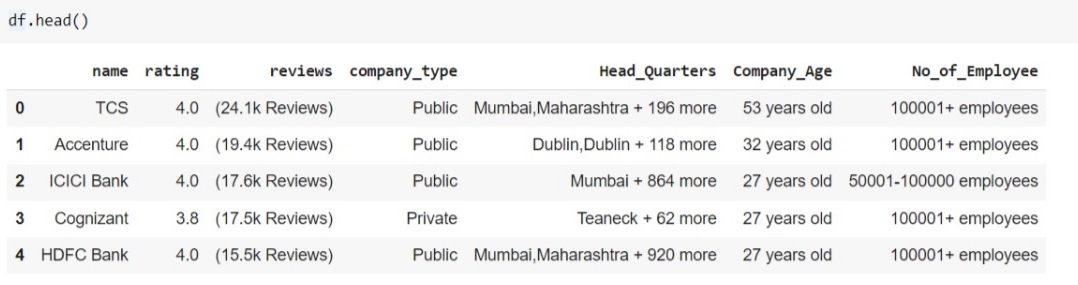
The above is a complete dataframe of only the first page, and now let’s kickstart our enthusiasm and fetch data for all the pages.
Creating a Final Dataframe
Let’s Prepare Dataset Using Web Scraping!
Now you have a better understanding of web scraping and how data is coming in a separate feature. So we are ready to create a final dataframe of all 33 pages and each page is having data of 30 companies. But on some pages, there are some inconsistencies like a little information about a company is not provided so we need to handle this. so we will place each feature in a try-except block and if data is not present then we will append the Null value in place of it. For fetching data from each page, we have to make a request again and again on a different page in a loop and fetch its data and after that, all the things are the same as above.
final = pd.DataFrame()
for j in range(1, 33):
#make a request to specific page
webpage=requests.get('https://www.ambitionbox.com/list-of-companies?page={}'.format(j)).text
soup = BeautifulSoup(webpage, 'lxml')
company = soup.find_all('div', class_ = 'company-content-wrapper')
name = []
rating = []
reviews = []
comp_type = []
head_q = []
how_old = []
no_of_employees = []
for comp in company:
try:
name.append(comp.find('h2').text.strip())
except:
name.append(np.nan)
try:
rating.append(comp.find('p', class_ = "rating").text.strip())
except:
rating.append(np.nan)
try:
reviews.append(comp.find('a', class_ = "review-count").text.strip())
except:
reviews.append(np.nan)
try:
comp_type.append(comp.find_all('p', class_ = 'infoEntity')[0].text.strip())
except:
comp_type.append(np.nan)
try:
head_q.append(comp.find_all('p',class_='infoEntity')[1].text.strip())
except:
head_q.append(np.nan)
try:
how_old.append(comp.find_all('p',class_='infoEntity')[2].text.strip())
except:
how_old.append(np.nan)
try:
no_of_employees.append(comp.find_all('p',class_='infoEntity')[3].text.strip())
except:
no_of_employees.append(np.nan)
#creating dataframe for all list
features = {'name':name, 'rating':rating,'reviews':reviews,
'company_type':comp_type,'Head_Quarters':head_q, 'Company_Age':how_old,
'No_of_Employee':no_of_employees }
df = pd.DataFrame(features)
final = final.append(df, ignore_index=True)
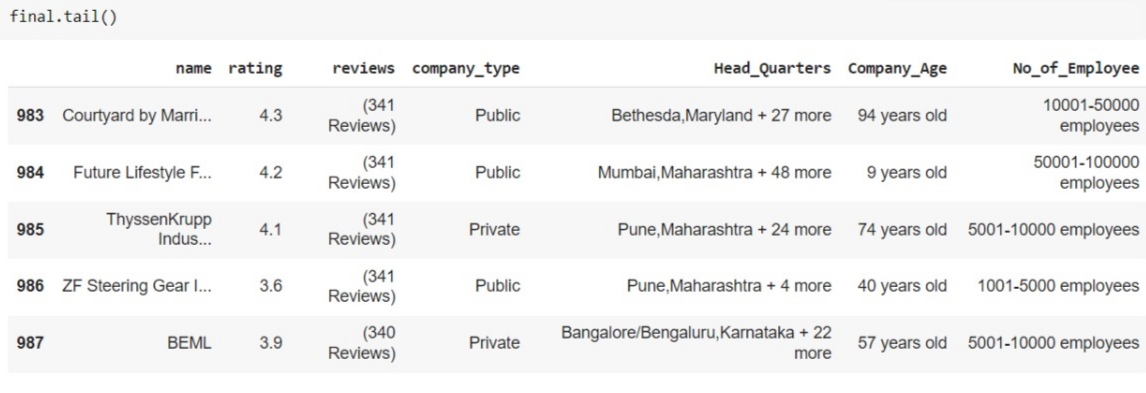
We have created a dynamic URL of each page to make a request and fetch the data and you can have a look at the final dataframe. That sits this is how web scraping is done.
Web Scraping using lxml
Now we have an understanding of how web scraping works, and how to extract a single piece of information from a website and implement a dataframe. What if we want to extract some paragraphs or some informant line from some blog or article then It is easy to do with lxml using XPath.
We will extract a paragraph from one of the Analytics Vidhya articles using lxml with only a few lines of code. I hope that you have already installed lxml using the pip command, and are ready to follow the below steps.
Step-1) Inspect the paragraph which has to be scrapped
Visit the article and select any paragraph and right-click on it and click on inspect option.

Step-2) Right-click element on source-code to the right
As you click on Inspect the Element section will open, and in that right-click on the selected element and copy XPath of element and come to the coding environment and save the path in a variable as a string.
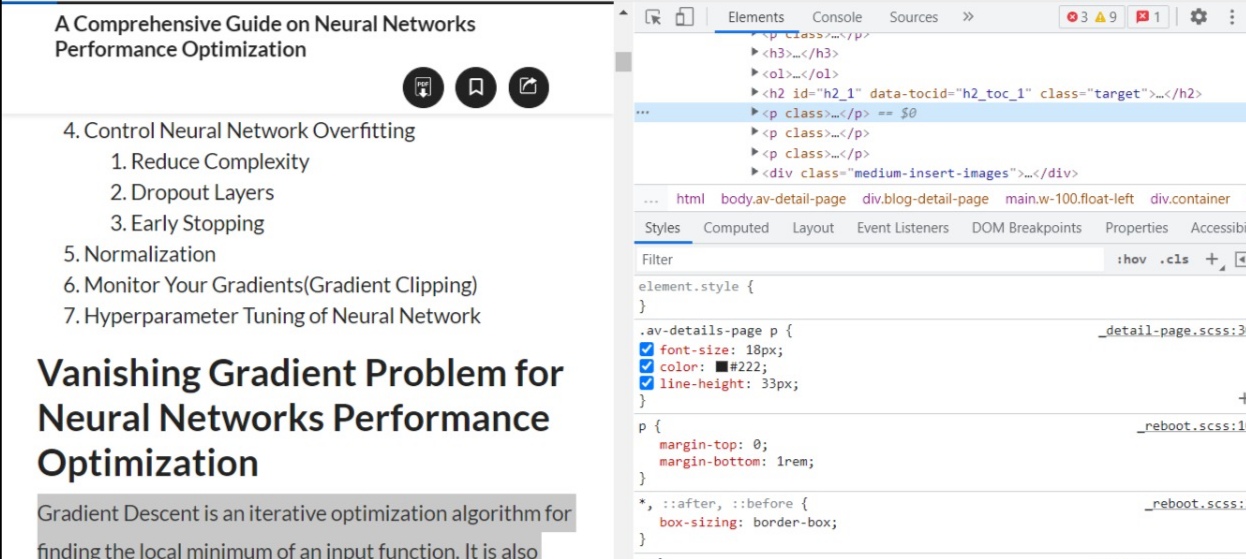
Step-3) HTTP Request to retrieve HTML content
Make HTTP requests on the Article website to retrieve the HTML content.
import requests from lxml import html URL = 'https://www.analyticsvidhya.com/blog/2021/09/a-comprehensive-guide-on-neural-networks-performance-optimization/' path = '//*[@id="1"]/p[5]' response = requests.get(URL)
Step-4) Get Byte string and filter source code
using lxml parser parses the response content received on request and converts it to a source code object.
byte_data = response.content source_code = html.fromstring(byte_data)
Step-5) Jump to preferred HTML element
Now using Xpath retrieve the desired paragraph we aim to get.
tree = source_code.xpath(path) print(tree[0].text_content())
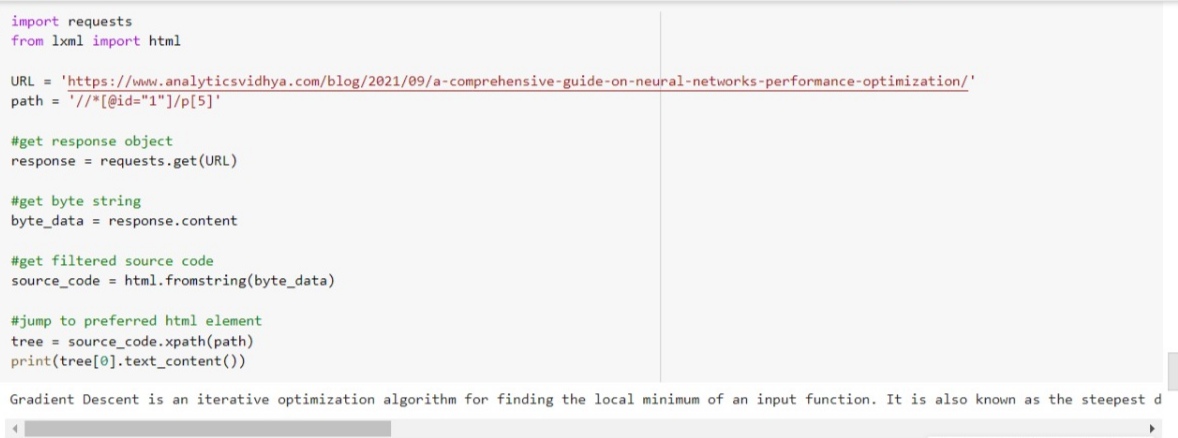
It’s done and this simple is using an lxml parser to extract a large amount of data from the website in our coding environment.
Hands-on Web Scraping using Scrapy
Scraping data efficiently in a few minutes is everyone’s aim which is fulfilled by scrapy. with multiple spider bots that crawl on a website to retrieve data for you. In this section, we will be using scrapy in our local jupyter notebook(Goole collab) and scrape data in our dataframe. Scrapy provides a default quote website for learning web scraping using scrapy.
It consists of various quotes along with the author’s name and tags to which it belongs. we will create a dataframe with 3 columns as quote, author, and tag. After installing spacy follow the below steps. After scraping details from a website we will write details in JSON file and load dataframe from JSON using Pandas library.
Step-1) set Interactive python shell
from IPython.core.interactiveshell import InteractiveShell import scrapy from scrapy.crawler import CrawlerProcess
Step-2) Setup a Pipeline
here we create a class that creates a new JSON file and function to write all items found during scraping in a JSON file where each line contains one JSON element.
#setup pipeline
import json
class JsonWriterPipeline(object):
def open_spider(self, spider):
self.file = open('quoteresult.jl', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "n"
self.file.write(line)
return item
step-3) Define the Spider
Now we need to define our crawler(Spider) and we pass the URL from where to start parsing and which values to retrieve. I set the logging level to a warning so that notebook is not overloaded.
#define spider
import logging
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
custom_settings = {
'LOG_LEVEL': logging.WARNING,
'ITEM_PIPELINES': {'__main__.JsonWriterPipeline': 1}, # Used for pipeline 1
'FEED_FORMAT':'json', # Used for pipeline 2
'FEED_URI': 'quoteresult.json' # Used for pipeline 2
}
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.css('span small::text').extract_first(),
'tags': quote.css('div.tags a.tag::text').extract(),
}
Each quote is written in a separate division tag with class name as the quote so we have fetched all quotes using this division and quote CSS selector.
Step-4) Start the Crawler
define the scrapy crawler process and pass the spider class to start retrieving the data.
#start crawler
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
process.crawl(QuotesSpider)
process.start()
Step-5) Create DataFrames
The retrieved data is saved in a JSON file and we will load them as a dataframe using pandas.
import pandas as pd
dfjson = pd.read_json('quoteresult.json')
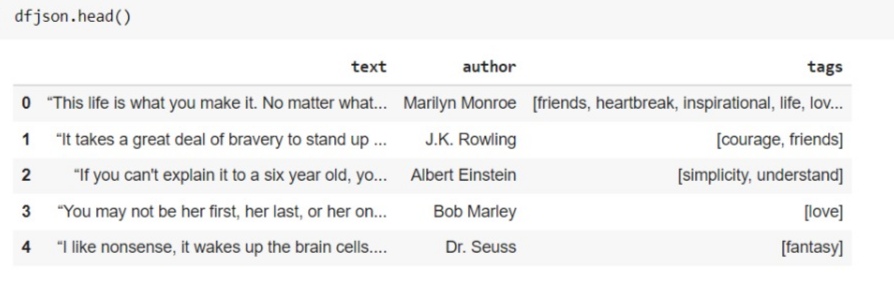
This is how scrapy works and helps you to extract lots of data from websites very quickly.
End Notes
In this article, we have learned about Web scraping, its applications, and why it is being used everywhere. We have performed hands-on live web scraping from websites to fetch different companies and prepare a dataframe that is used for further machine learning project purposes using beautiful soup. We have also learned about the lxml library and perform a practical demonstration. Apart from this, we have learned about the boss of web scraping library name scrapy and why it is known so.
You can do a lot more in this to convert it into an end-end project. Like when we fetch particular company details then try to search the company in google and fetch Its CEO, contact number, services, etc details and It will be very interesting to do so.
I hope you like the article and it was easy to follow up through each step. If you have any doubt or feedback, please post it in the comments section below.
About The Author
I am pursuing a bachelor’s in computer science. I am a data science enthusiast and love to learn, work in data technologies.
Connect with me on Linkedin
Check out my other articles here and on Blogspot
Thanks for giving your time!
I am a software Engineer with a keen passion towards data science. I love to learn and explore different data-related techniques and technologies. Writing articles provide me with the skill of research and the ability to make others understand what I learned. I aspire to grow as a prominent data architect through my profession and technical content writing as a passion.






