Table of Contents
— What is Automated Machine Learning?
— Machine Learning Pipeline
— Why Automation in Machine Learning
— Autopilot
— Six steps- Raw data to deployment
— Parameters for Autopilot
— Automated Machine Learning with Comprehend
— Benefits & Working of Comprehend
— Amazon Athena
— Conclusion
What is Automated Machine Learning?
Automated Machine learning (AutoML) is that the effort of automating the processes of the machine learning pipeline.
But if you are new to the ML field, you may hear the word Machine learning Pipeline. Here is the short intro to the pipelining.
What is Machine Learning Pipeline?
Machine Learning pipeline is the multiple sequential steps that contain everything from the data collection, data extraction to the model deployment. The various journey from raw data to the deployment is called the machine learning pipeline.
Why Automation in Machine Learning?
Machine learning Engineers, Data Scientists, Cloud Architects spend a lot of time in building, monitoring, changing, and managing the ML pipelines. They need to prepare the data, process the data, visualize, make data-driven decisions, decide the suitable algorithms, tools, techniques, software, etc. Highly experienced data scientists or ML engineers use their skills and intuition to choose the best frameworks and algorithms to use according to the business problems and domain of that particular problem statement.
Most of the time, ML practitioners want to get more accurate results. So they will be checking for suitable parameters to get highly accurate results. They will tune those parameters which are called ” Hyperparameter Tuning”. For performing Hyper-parameter tuning, ML engineers should have a piece of wide knowledge of tuning techniques. It requires experience, intuition, and time. Because it is an experimental technique as it tests various new values to the parameters and finds the best hyper-parameter for our model. This is an iterative and huge time-consuming process.
Imagine a scenario, that we just use a service that automatically prepares, cleans, and trains the best-fitted model for our dataset and deploys it to the production with just a click…
Automated ML is such a service that automates various sequential processes(pipelines) like preparation, training, deployment, monitoring, etc.
There are various cloud providers which provide Automated ML. Here are the top cloud service providers from Gartner as of July 2021

Image 1 – https://d2908q01vomqb2.cloudfront.net/da4b9237bacccdf19c0760cab7aec4a8359010b0/2021/08/02/2021-CIPS-MQ.png
The top 3 platforms which provide Automated ML are
1) Amazon – Sagemaker Autopilot
2) Google Cloud – AutoML
3) Microsoft Azure – AutoML
Here we will see Amazon Sagemaker Autopilot’s usage and features.
Amazon Sagemaker
Amazon SageMaker is used by many data scientists, ML engineers. They use to prepare, build, train and deploy machine learning models quickly. It has built-in tools for every step of ML development, that is labeling, data preparation, feature engineering, statistical bias detection, model selection, training, tuning, hosting, monitoring, and management.
Autopilot
Amazon Sagemaker Autopilot is the automated ML service of AWS.
It simplifies the ML pipelines and handles many processes of the model development life cycle (MDLC). In short, simply import the dataset to the autopilot and it gives out fully trained and optimized predictive models. These models are selected by Autopilot and we have full control over the generated models. We can modify and select the top-performing models based on the expected accuracy, latency, and many more evaluation metrics.
We just need to provide our raw data in an S3 Bucket. Example: Tabular form of data – CSV file. Then provide details like which columns are independent and which columns are dependent (i.e) the Column we are going to predict. Then Autopilot will do the necessary procedures and pipeline and gives the model.
S3 Bucket is the Amazon’s Storage Service. We can store and retrieve data.
Six Steps – Raw data to Deployment
Here are the 6 simple steps to load, analyse, deploy our automated model.
1. Loading Raw Data
We have to first import our data to train the model. The data must be in a supported format such as tabular form. So we have to load our data from the S3 bucket(AWS Simple Storage Service) for training the model.
Image 2
2. Selecting Target
For predicting the output, we must specify the outcome column or dependent column. The column we are going to predict from the already known column is the target column. That should be selected in this step. It also performs feature engineering and fills the missing data, provides insights about columns, etc. All the manual processes are automated.

Image 3
3. Automated Model Building
In this step, the autopilot automatically prepares the data and create multiple set of models and choose the best model out of those models and trains the data and tune the hyperparameters.

Image 4
4. Model and Notebooks Control
Here, the user is provided with many controls. They have full control over the model’s notebooks. The important feature of Autopilot is that it provides full visibility into each of those steps and gives us all the code for our reference. Autopilot shares the model along with all logs, metrics, and generates a Jupyter notebook that contains the code to reproduce the model pipelines.
5. Model LeaderBoard
After training and tuning, it creates a leaderboard of the models trained. From the wide set of models, we can select the model which performs according to our business problem and use it for deployment. After this, We can just deploy with a single click.

Image 5
We can review all the automatically generated models. The list of trained models is ranked based on the evaluation metrics such as accuracy, precision, recall, Area under the curve (AUC).
6. Deploy and Monitor
After reviewing and selecting the best-suited model, we can go for deployment easily. We can also monitor the performance of the models.
If we need to capture incoming requests and responses, we can enable data capture for all prediction requests and responses of deployed models.
To Configure Autopilot Experiment, we need to provide some input parameters.
- Experiment Name: A name for identification of the experiments.
- Input Data Location: S3 location path of our dataset.
- Target attribute name: The target attribute is the attribute/dependent feature in our dataset that we want Amazon Sagemaker Autopilot to make predictions for.
- Output Data Location: The location in S3 where we want to store the output like models, metrics and notebooks.
- ML Problem type: The Machine Learning model such as Binary Classification, Regression, Multiclass classification. We can choose the problem type. The “AUTO” option allows autopilot to choose itself based on the given input data.
- Running Complete Experiment: We can choose to run a complete experiment or just to generate a Data exploration notebook.
Automated Machine learning with Comprehend
Amazon comprehend is an AI service to handle Natural Language Processing(NLP) tasks using machine learning. It unpacks the information from instructed data. We don’t need to glance through each and every document. Instead, Comprehend go through the text documents as input and find key phrases, sentences, language, and sentiment behind the context and makes our process easier. This service finds the critical elements of data such as references to people, accent, place, and can categorize multiple files based on topics.
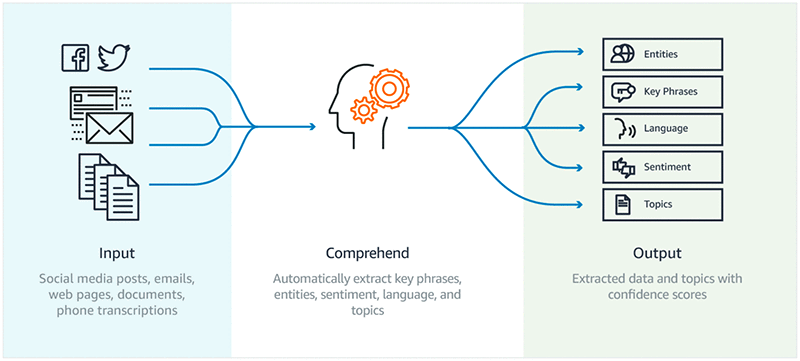
Image 6
Benefits of AWS Comprehend
Organize documents by topics
In Amazon comprehend, we can create custom models so that they can be trained to label documents with topics and tags. It provides a solution to categorize and classify multiple documents based on the contents.
Deep Learning-based NLP models
Amazon Comprehend analyse text by using deep learning models. These models are trained frequently with multiple domain knowledge bases. So higher accuracy is obtained.
Easier integration of NLP into Apps
Amazon Comprehend makes it easier to leverage the powerful text analysing capabilities and accurate NLP tasks into our wide range of applications with a simple API.
Low cost
By using this AWS service, we don’t need to pay minimum fees. We can pay only for the documents that we analyzed.
How Comprehend Works?
A pre-trained model is used for examining and analysing a document or group of documents to collect insights from it. This model is continuously re-trained from time to time with wide resources from various domains so that there is no need to provide training data.
Supported Languages on Comprehend
Code |
Language |
| de | German | ||
|
|
||
|
|
||
|
Italian | ||
| pt | Portuguese | ||
| fr | French | ||
| ja |
|
||
|
Korean | ||
| hi | Hindi | ||
| ar | Arabic |
| zh | Chinese (simplified) |
| zh-TW | Chinese (traditional) |
Sentiment Analysis With Comprehend
Sentiment analysis is the analysis of the overall emotional sentiment of the text and classifying it under categories of positive, neutral, negative, mixed. This will be helpful when analysing product reviews, movie reviews, customer feedback, product analysis, social media marketing, market research, etc. Comprehend also provides a confidence rating that gives an estimate for that sentiment being dominant. That is it shows the percentage of how sure the model output is correct.
Train and Deploying Comprehend Custom Model
Comprehend custom is also an Automated Machine learning model that enables us to tune Comprehend’s built-in model.
In the Amazon Comprehend, click Custom Classification and then train the classifier.
We need to set the configurations.
- Provide a name for the classification and choose a language.
- Choose the classifier mode
We can classify the documents using two modes
Multi-Class and Multi-Label Modes
Multi-class mode
The multi-class mode should have a single class for each document. For example, In multi-class mode, a movie can be classified as a comedy or as action, but not both at the same time.
Multi-Label Modes
The multi-label mode may have one or more classes for each document text.
For example, In multi-label mode, a movie can be classed as a drama movie, or it can be an action movie, an horror fiction movie, and a thriller movie, all at the same time.
3. Put the training data in Amazon Simple Storage Service(Amazon S3) bucket. Specify the path to the training data and path to the output data(S3 bucket path). Make sure the S3 bucket have AWS Identity and select IAM role with permissions to access the bucket from Amazon Comprehend.
4. Click Train classifier
5. Once the classifier is trained, we can deploy it to serve predictions.
6. Select the trained model and click on Actions.
7. Create Endpoint – Give a name and create Endpoint
8. Navigate to Real-time analysis, select Custom Analysis type. Select the custom Endpoint from the endpoint drop-down list.
9. Now Paste any review in the field and click Analyse.
10. Now we can see the results of classification from our custom model.
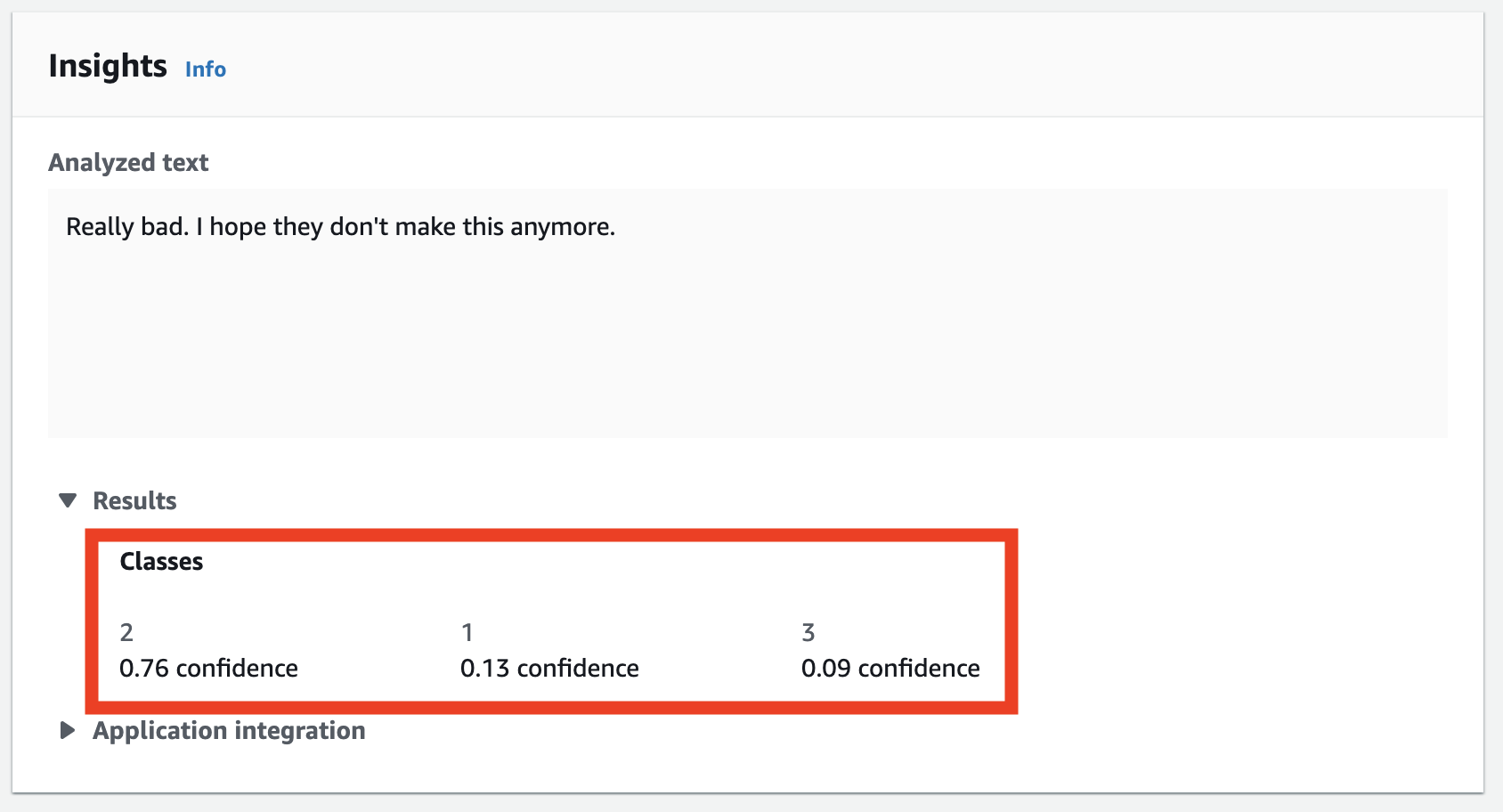
This model shows 76% confidence that the review is 2 Star rated.
Amazon Athena
Amazon Athena is an AWS service that provides an interactive querying service that makes it easier to analyse the data in S3 Storage using standard SQL (Structured Query Language).
Amazon Athena is a serverless architecture.
What is Serverless architecture in AWS?
Serverless architecture is an architecture to build and run applications & services. But we don’t need to manage infrastructure. Application runs on the servers but all the server management is done by AWS.
So we don’t need to manage infrastructure and we can only pay for the queries that we run.
Athena is easy to use. We just need to specify the data in Amazon s3. Then define the schema. We can write queries using SQL. It delivers the results at a much faster pace. There is no need for complex ETL( Extract, Transform, and Load ) operations. Because ETL takes a huge time for preparing data for analysis. Now with Athena, we can start analysing large datasets with only SQL knowledge.
Benefits of Amazon Athena
Payments per query
- In Amazon Athena, we can pay only for the queries we run.
- Charges = $5 / terabyte scanned by the queries.
Serverless
Amazon Athena is serverless. We can quickly query the data without setting up or managing servers & data warehouses.
Easier Platform
- No need for complex ETL jobs ( Extract, Transfer, Load)
- Allows to trap data from Amazon S3
Faster Interactive Querying
Amazon Athena executes queries in parallel. That makes the results reflect back in seconds.
Parameterized Queries
Recently, they have included parameterized queries functionality. The users can save time and eliminate errors by using frequently modified queries such as date filters or category filters as parameterized queries which will be useful for multiple use cases.
Example: Retail sales uses filters for product category, region, date. This varies for various queries. Instead of manually modifying the filters in SQL, we can pass those values as parameters when executing the query.
S3 Data Lake Query with Amazon Athena
After registering our Athena table with our S3 data, it stores the Table-to-S3 mapping in the Data Catalog. Because the Glue Data Catalog service in AWS is used by Athena
What is AWS Glue Data Catalog?
The AWS Glue Data Catalog is a metadata store. It is a service that lets us store our metadata, annotate, and share metadata in the AWS cloud. Each AWS account has AWS Glue Data Catalog.
Athena is based on the Presto DB. It is an open-source, distributed SQL query engine for fast, ad-hoc data analytics on large datasets. It uses high RAM clusters to perform queries. It also does not require a large amount of disk.
Conclusion
If you liked this article and want to know more, go visit my other articles on Data Science and Machine Learning by clicking on the Link
I hope you enjoyed the article and increased your knowledge. Please feel free to contact me at [email protected] Linkedin
Mohamed Illiyas
Currently, I am pursuing my Bachelor of Engineering (B.E) in Computer Science from the Government College of Engineering, Srirangam, Tamil Nadu. I am very enthusiastic about Statistics, Machine Learning, NLP, and Data Science.
Connect with me on Linkedin
Image Sources
Image 1 – https://d2908q01vomqb2.cloudfront.net/da4b9237bacccdf19c0760cab7aec4a8359010b0/2021/08/02/2021-CIPS-MQ.png
Image 2 –
Image 3 – https://d1.awsstatic.com/SageMaker/SageMaker%20reInvent%202020/Autopilot/Amazon%20SageMaker%20Autopilot%20Automatic%20Data-preprocessing%20and%20Feature%20Engineering.a8acb179b2eee01df2c7611f1e025c56e35c8e21.png
Image 4 – https://d1.awsstatic.com/SageMaker/SageMaker%20reInvent%202020/Autopilot/Amazon%20SageMaker%20Autopilot%20Automatic%20Model%20Selection.dd35f9fbe90c12f02e07a2f855323d39b594d8d2.png
Image 5 – https://d1.awsstatic.com/SageMaker/SageMaker%20reInvent%202020/Autopilot/Amazon%20SageMaker%20Autopilot%20Model%20Leaderboard.fd3fa652dd6bc3c0262ea3393d62c0cd95165fe5.png
Image 6 – https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b103eff4b59/2019/04/03/analyze-twitter-comprehend-sagemaker-1.gif
I am a Machine Learning professional with a strong background in Natural Language Processing (NLP). I am passionate about predictive modeling, data analysis, and deep learning, as they provide unique opportunities to uncover valuable insights from complex datasets.
Recently, my focus has been on Language Models (LLMs), an exciting area within NLP. I have been actively involved in researching, developing, and refining LLMs to enhance their capabilities and applicability in real-world scenarios. Through my work, I strive to advance the field of NLP and contribute to the development of intelligent systems that can understand and generate human-like language.
Sharing knowledge and collaborating with others is an essential part of my professional journey. I find great joy in exchanging ideas, insights, and expertise with fellow professionals and enthusiasts. By sharing my knowledge, I aim to contribute to the growth of the Machine Learning and NLP community, fostering an environment of continuous learning and innovation.





