What is the need for Hive?
The official description of Hive is-
‘Apache Hive data warehouse software project built on top of Apache Hadoop for providing data query and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.’
Hadoop is used for storing data in a distributed fashion and in smaller chunks for increasing the speed of accessing and processing the data. Hive helps in querying the big data on HDFS (Hadoop Distributed File System, Hadoop’s distributed storage space) with ease. Hive query language (HQL) is very similar to SQL but is meant for handling huge amounts of data. Hence there are differences in the properties of Hive and a Relational DB.
Key differences of Hive from a relational DB-
1) The schema can vary
2) Partitioning exists. It is the key method of storing the data into smaller chunk files for quicker accessing and retrieving
3) The integrity constraints like primary key and foreign key do not exist.
4) Updates and deletes are supported only for ORC format Hive tables. Otherwise, the operations are at partition level – create a new partition, append to a partition, overwrite a partition, delete a partition.
Aim of this blog
There are some more differences that come during implementation. I am highlighting nuances in one such case of handling partitioned tables in Pyspark code, where I faced issues and did not get much help from online content. When we deal with tables in code, it usually involves batch processing.
Normal processing of storing data in a DB is to ‘create’ the table during the first write and ‘insert into’ the created table for consecutive writes. These two steps are explained for a batch job in Spark.
Create Hive table
Let us consider that in the PySpark script, we want to create a Hive table out of the spark dataframe df. The format for the data storage has to be specified. It can be text, ORC, parquet, etc. Here Parquet format (a columnar compressed format) is used. The name of the Hive table also has to be mentioned. With just the table name, the data files will be stored in the default Hive directory along with the metadata. These types of tables are called managed tables. When the directory is mentioned, the data alone is stored in the mentioned path, while the metadata will still be there in the default path. When the directory is provided, then the hive table is called an external table. In this case, deletion of the table will not affect the data files.
Syntax for create script:
df.write.format('parquet').option('path',table_dir).saveAsTable(db_name+'.'+table_name)
- SaveAsTable – is the command to create a Hive table from Spark code. An external table is created and the data files are stored as parquet.
- db_name – a variable with Database schema name
- table_name – a variable with the table name
- This can be enhanced by adding options:
- coalesce – in case the data is spread too much among partitions, we can add coalesce function to restrict the number of partitions.
- mode – can be overwritten or append. Overwrite mode deletes the data files in the given path and creates new files.
- path option – path for storing the table data is specified here
- df – dataframe containing the table for the data
Sample create script with more features:
df.coalesce(10).write.mode('overwrite').format('parquet').option('path',table_dir).saveAsTable(db_name+'.'+table_name)
Insert into Hive table
Insert can only be done on a Hive table that already exists.
Syntax for insert script:
df.coalesce(10).write.format('parquet').insertInto(db_name+'.'+table_name)
insertInto – is the command for inserting into the hive table. The path for the table need not be specified and the table name will suffice
Partitioned table
Partitioning is splitting huge data into multiple smaller chunks for easier querying and faster processing. Partitioning is usually done on columns that have low cardinality, as one partition is created for every unique value in the partitioning column(s).
A sample for partitioned data:
Usually, for batch processing, the load date will be the partitioning column, as every day’s write can be written to a separate folder without disturbing loads of previous days.
Let us consider the instance of retail shop data. The batch processing involves loading the table with the bill details of every branch of the retailer for every day.
This table can be created with 2 partition columns – (1) load_date and (2) branch_id
In this way, every branch will have a partition for every day. The loaded table location will look like this. In the path mentioned for table creation, there will be separate folders created for every partition value for all partition columns in the same hierarchical order.
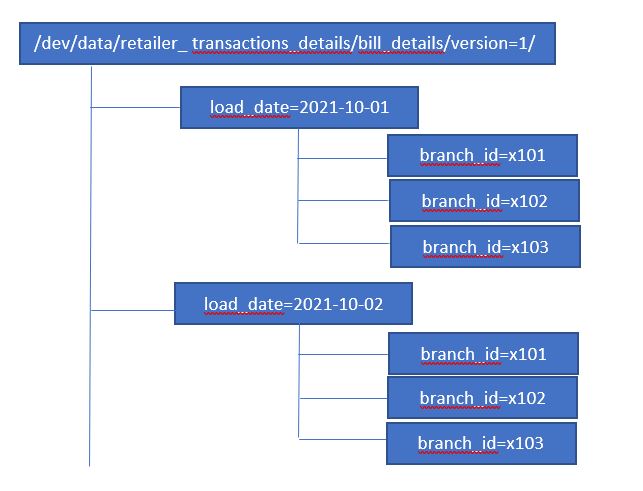
When the partitions are created on hard-coded values passed, then that is static partitioning.
When the partitions are created on column values, it is called dynamic partitioning.
When using the feature of dynamic thresholding in the spark job, there are a couple of parameters that have to be set.
spark.conf.set("hive.exec.dynamic.partition", "true")
spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict")
Create partitioned Hive table
df.coalesce(10).write.mode('overwrite').partitionBy('load_date','branch_id').format('parquet').option('path',table_dir).saveAsTable(db_name+'.'+table_name)
partitionBy – option has to be specified with the partition columns in the right order
During batch processing, this SaveAsTable will create a table the first time. During subsequent runs, it will still be able to load the data into new partitions with the same table name. In the case of reloads for the same date, the usage of overwrite mode will overwrite the corresponding reloaded partitions only. To avoid this, the append mode can be used instead.
Key point:
If there are multiple instances of the batch process running in parallel and are trying to write to the table at the same time, there will be an error. As the saveAsTable is meant for creating the table, multiple parallel executions for creating the same table errors, even if we are trying to access different partitions (say every instance of this job is for a different branch_id).
Inserting into partitioned Hive table
That is when we look for the aid of insertInto. As this is purely an insert command, the parallel runs will not affect the table, as long as they are dealing with different partitions.
As the table is already created, the table path and the partition columns need not be specified.
df.coalesce(10).write.mode('overwrite').format('parquet').insertInto(db_name+'.'+table_name)
Ideally, this will be how we will create the insert into the statement.
Key points:
Again there are 3 key points to note here:
Key point-1) During the table creation, the partition columns from the dataframe will be created as the last columns in the table. This will be irrespective of column order in the dataframe.
The insert does not permit the specification of partition columns. Naturally, during the insert into, the column order will not be changed and will be entered into the table as is. The parquet files created will have the same column order as the dataframe df. In case the partition columns are not already the last ones, we will note a swap in the column values loaded to the table.
Even if there are data type clashes in the swap, we will rarely see an error. The parquet file will be loaded with the incorrect order during inserts. In the display of the hive table, the clashes will just be empty.
An example to illustrate this better:
df.printSchema()
root
|– branch_id: string (nullable = true)
|– branch_name: string (nullable = true)
|– bill_id: string (nullable = true)
|– bill_datetime: string (nullable = true)
|– billing_clerk: string (nullable = true)
|– bill_total_value: string (nullable = true)
|– customer_id: string (nullable = true)
|– load_date: date (nullable = true)
saveAsTable command will move the partition columns load_date and branch_id to the last in the table.
InsertInto will not change the order of df and load as-is.
Resultant table entries with swapped data:

To avoid this, the column order has to be swapped in the df for the partition columns to be moved to the last during creation itself.
df.printSchema()
root
|– branch_name: string (nullable = true)
|– bill_id: string (nullable = true)
|– bill_datetime: string (nullable = true)
|– billing_clerk: string (nullable = true)
|– bill_total_value: string (nullable = true)
|– customer_id: string (nullable = true)
|– load_date: date (nullable = true)
|– branch_id: string (nullable = true)
Key point-2) The overwrite mode does not work as expected in the insert into statement. To overcome this, an extra overwrite option has to be specified within the insertInto command.
df.coalesce(10).write.mode('overwrite').format('parquet').insertInto(db_name+'.'+table_name, overwrite=True)
Key point-3) There is also a workaround for this insert. Once the table is created, instead of writing using an insert statement, we can directly write the parquet files to the same directory as the hive table. This way the partitioned files are written to the table directory, and the data will also be part of the table.
Wrap up
This article gives one a better understanding to handle the hive partitioned table in multi-instanced batch processing.
If interested, please check out my other articles.
I am a Big data and cloud professional, with more than a decade of experience in data projects.
If interested, please check out my other articles at https://www.analyticsvidhya.com/blog/author/akilaram/






Hey Akhil, Great content, I couldn't find much on this online. This helped a lot. A quick question, as mentioned in "Key point-3", could you explain or give an example for writing Parquet files to the same directory as Hive table. Thank you.