This article was published as a part of the Data Science Blogathon
INTRODUCTION
Investing is an important part of one’s life because Investing helps in making the present and future safety, it allows you to grow financially. Also, investing is a process of compounding profits. Investing money at the right place and right time helps in increasing the money, for example, one has invested Rs. 100/- and after two days Rs.100/- becomes Rs.120/- now if the person still wants the same money to be invested then the profits will be on Rs.120/- and not on Rs.100/- that’s why it is also known as a process of compounding.
But now the question is how to determine where to invest in? Let’s take the example of the stock market… in which type of stock one should invest. After choosing the stock, which company one should invest?
if you want to know this, then you are in the right place….
Suppose that you are a financial investor that likes to put resources into various stocks/items/commodities and so on. The reality behind being an investor is that you need to explore a great deal. You need to explore every single market for the top-performing organizations, so that, you can put resources into and have an assurance that day’s end you will acquire something.

Click here to view the source of this image
If we take into consideration all the traditional factors for trading like – one has to understand all the industries, then one has to research about a particular industry, then google about the different companies after that, using NSE or BSE website analyze the stock by going to different tabs & links.

Click here to view the source of this image
Imagine having the power to speed up this process by analyzing BSE/NSE website in a few seconds. I am sure now you surely have thought of it, so let me help you with it.
This can be done using the WEB SCRAPING technique, in this technique, one can extract useful data from any website or any
online source.
Click here to view the source of this image
WHAT IS WEB SCRAPING?
Web scraping is a process of extracting information from the web. This can be done using various software and can be used in extracting any type of information. It is a very feasible process as it can be done anywhere and anytime the only condition of web scraping is that it requires an internet connection.
Web scratching is an important method since it licenses quickly and is capable of extracting online data. Such data would then have the option to be taken care of to assemble bits of knowledge as required. In this manner, it furthermore makes it possible to screen the brand and reputation of an association.
How To Perform Web Scraping?
After understanding web-scraping, the most common question is – How do I learn web scraping?
The process of web-scraping is really simple. To extract data using web scraping with python, you need to follow these basic steps:
1. Find the URL that you want to scrape.
2. Inspecting the Page.
3. Find the data you want to extract.
4. Write the code.
5. Run the code and extract the data.
6. Store the data in the desired format
All the steps mentioned above as shown below by performing actual web-scraping that will help in investing.
Let’s begin with the Art of Web Scraping
Now, we would be extracting the data from the official NSE website i.e., https://www.nseindia.com/“Be fearful when others are greedy. Be greedy when others are fearful.” — Warren Buffett
With the help of web scraping one can understand – when people are scared and in which stock one can invest and earn more even in the bearish market.
For performing the above-mentioned process of extracting data from the web i.e., web scraping, first we need to install some necessary libraries like:
· Pandas
· Bs4
· BeautifulSoup
· Webdriver_manager.chrome
· ChromeDriveManager
The code for importing the same is:
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://www.nseindia.com/")
html=driver.page_source
soup = BeautifulSoup(html,'html.parser')
OUTPUT:https://docs.google.com/document/d/1x-M-AoeQbibmudqKa6cXSHkSt2S0mdqRXf-vol7VRPM/edit?usp=sharing
Now, let’s check whether we are on the correct website or not…..
For checking, we will be using Beautiful Soup Library
The code for the same is:
print("Title of the website is : ")
for title in soup.find_all('title'):
print(title.get_text())
OUTPUT: Title of the website is : NSE - National Stock Exchange of India Ltd: Live Share/Stock Market News & Updates, Quotes- Nseindia.com
Now, we have to open the NSE site on the other tab, let’s look at it for a second and try to observe different tags. To look for the tag names that are used in the actual website one needs to open inspect element.
What is Inspect Element?
Inspect element is one of the designer devices consolidated into Google Chrome, Firefox, Safari, and Internet Explorer internet browsers. By getting this instrument, one can really see — and even alter — the HTML and CSS source code behind the web content.
Inspect Element is a source that helps in viewing the source code of the website. There are two ways to open inspect element:
1. Right-click on the web page and select inspect element
2. Use shortcut key – Ctrl + Shift + I
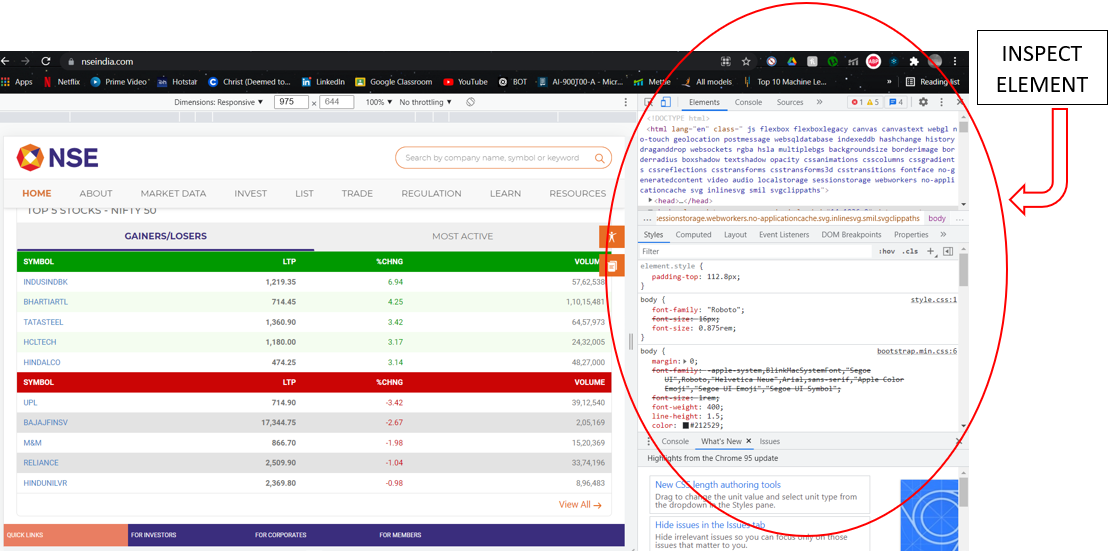
Source – It is a screenshot from my Laptop
After opening Inspect Element, search for the market/Index for which you want to extract data. Generally, all these types of information are known as a class and all classes are at the ‘P’ tag. Hence to extract information that is on the ‘P’ tag we will use the code:
para=soup.select('p')
para
OUTPUT:
[<p class="greenTxt">Debt Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt" id="capMarStat">Normal Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt">Currency Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt">Commodity Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt">Debt Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt" id="">Normal Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt">Currency Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt">Commodity Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p class="greenTxt">Debt Market is Open</p>, <p class="next_date">Current Trading Date - 01-Nov-2021</p>, <p>Find everything about the leading stock exchange of India</p>, <p>Check NSE's group of the companies</p>, <p>Browse a comprehensive and innovative product and service offerings by NSE</p>, <p>Live Analysis of top gainers/losers, most active securities/contracts, price band hitters, overview of the market.</p>, <p>View Option chain for the exchange</p>,
Now, it can be observed that we got all the information about different markets with dates + timings but this is not very readable/understandable. To make it easy to understand we will use code:
para = soup.findAll('p')
for p in para:
print(p.get_text())
OUTPUT:
https://docs.google.com/document/d/1-YoeGDLMbpdUBQKRdYOqTfMy-fAWU_KPCnJnHFajdd0/edit?usp=sharing
Finally, we can now read it and understand it.
Now, let’s deep-dive into the same and now let us search for Index – I will choose NIFTY index, you can choose according to your own desire.
To get the NIFTY Index information we will use the code:
Nifty = soup.findAll('p', {'class':'tb_name'})
for name in Nifty:
print(name.get_text())
OUTPUT:
NIFTY 50 NIFTY NEXT 50 NIFTY MIDCAP 50 NIFTY BANK NIFTY FINANCIAL SERVICES
Now let’s find out the value of each NIFTY Index for the same, we’ll use code:
Nifty = soup.findAll('p', {'class':'tb_name'})
value = soup.findAll('p', {'class':'tb_val'})
for Nifty_name in Nifty:
print(Nifty_name.get_text())
for Nifty_value in value:
print(Nifty_value.get_text())
OUTPUT:
NIFTY 50 NIFTY NEXT 50 NIFTY MIDCAP 50 NIFTY BANK NIFTY FINANCIAL SERVICES 17,802.00 42,443.10 8,606.30 39,400.55 18,829.70
Therefore, we got all the information we need to understand today’s Index for options trading.
In this article, we extracted a few pieces of information, but you can use the same technique to extract more data.
Another example for web scraping can be:
Let’s use the “DIV” tag now,
For this let’s use the code:
div=soup.find_all("div")
div
OUTPUT:
(The output for this is also not readable and understandable)
https://docs.google.com/document/d/1pNmTNJXFzslTnrxBA1IOoNUAraoKqr2i13o4_fT6gE8/edit?usp=sharing
Let’s make it easy to understand
For this we’ll use the code:
t = soup.body
for T in t.find_all('div'):
print(T.text)
OUTPUT:
https://docs.google.com/document/d/1KWpBqoGNYwi1r6ZRdDd0NpJ4BkBJhpUMYfOXlm0mE2U/edit?usp=sharing
Now, It can be observed that everything is readable and easy to understand…..
By this one can perform the art of the Web – Scraping.
ABOUT THE AUTHOR

A 3rd-year (5th Semester) Student at CHRIST University, Lavasa, Pune Campus. Currently Pursuing BBA (BUSINESS ANALYTICS).
Website – acumenfinalysis.com (CHECK THIS OUT)
Contacts:
If you have any questions or suggestions on what my next article should be about, please leave a comment below or write to me at [email protected].
If you want to keep updated with my latest articles and projects, follow me on Medium.






Investors art of web scraping is good to learn and provide traders idea to grow their business.
As per NSE, web scraping is deemed illegal on their terms and conditions page. Could you let me know if we need to take any consent from them and if yes what is the procedure.