This article was published as a part of the Data Science Blogathon
Image Source: Author
Introduction to Fitness Tracker Market
With the advancements in the IT domain, wearable devices have been in great demand in the recent past. A wearable device is simply a device that can be worn by the user and this device is capable of collecting vital information about the activities and health of the user through smart sensors. Fitness trackers are an important type of wearable device. In simple words, a fitness tracker can be worn by the user to collect and monitor data on fitness levels of the user through various activities like daily steps or total distance walked per day, hours slept with sleep stages, type of exercises with calories burnt, heartbeat monitoring, etc. These devices are connected to the internet and are capable of syncing the recorded data to a cloud. The user can access this data in the form of a dashboard for their fitness monitoring requirements.
According to researchandmarkets.com, the Global Fitness Trackers Market size has been experiencing significant growth in the recent past and is expected to reach $62,128 million by 2023. This indicates that there is great demand for fitness trackers in the global market. This also means that there might be a similar trend in the Indian market as well. The likely growth of the fitness trackers market could be due to a growing interest in the use of smart devices for fitness needs by the young population. These days, more and more people are interested in a connected lifestyle through the use of smartphones, smart homes (lights and appliances), smart workout accessories like mirrors or workout training equipment syncing with the cloud, etc. Thus, an increase in the availability of IoT devices along with health consciousness among consumers could definitely drive the demand for fitness trackers in the market even further in the coming future.
Using the above information as a reference, it would be interesting to discover if the fitness wearables market in India also supports this hypothesis. We can explore this idea using a dataset that contains information on fitness trackers from different brands. So, in the following section, we will perform a detailed exploratory data analysis (EDA) of the fitness tracker market in Python. We approach this in the following way-
1. Fitness trackers data collection from an e-commerce website
2. Data preprocessing
3. EDA to uncover insights
4. Conclusion
Building a Fitness tracker market dataset
Let us build a dataset that has several attributes on fitness trackers. We will use ‘PyScrappy’, an open-source Python library to scrape the required data from the e-commerce website. This is available for research and education ML requirements. For this tutorial, we will scrape the data from Flipkart.com.
Using Pyscrappy, we can scrape the attributes like Brand and model names, colours, price, display type and so on.
To use Pyscrappy, first install it using the pip command
pip install pyscrappy
Next, import the ecommerce_scrapper() to create an e-commerce scraper object of this class. Enter the number of pages to be scraped along with the keyword
ecommerce_scraper(“fitness tracker”,15)
This will generate the dataset and we can save it as a csv.
Preprocessing Fitness Tracker Market
The scraped dataset csv was cleaned in Excel using Excel functions to format the dataset as described below. Here are the columns in this dataset-
1. Brand Name: This indicates the manufacturer of the product (fitness tracker)
2. Device Type: This has two categories- FitnessBand and Smartwatch
3. Model Name: This indicates the variant/Product Name
4. Color: This includes the colour of the Strap/Body of the fitness tracker
5. Selling Price: This column has the Selling Price or the Discounted Price of the fitness tracker
6. Original Price: This includes the Original Price of the product from the manufacturer.
7. Display: This categorical variable shows the type of display for the fitness tracker. eg: AMOLED, LCD,OLED, etc.
8. Rating (Out of 5): Average customer ratings on a scale of 5.
9. Strap Material: Details of the material used for the strap of the fitness tracker.
10. Average Battery Life (in days): Quoted average battery life from the manufacturer based on the individual product pages. (It is not the scraped data).
11. Reviews: count of product reviews received.
In the colour column, for some rows, there are multiple colours. It is possible to create some additional columns based on colors like basic colour or premium colours if the manufacturer offers fancy colours like gold or rose gold. Similarly, for price or battery life columns, we can also have a new column to group price segments or the battery life. Such data preprocessing can be adjusted as per the user requirements from the EDA. Since EDA is the main objective here, we are not replacing any missing values or converting any categorical variables.
EDA of Fitness Tracker Market Data
We start with understanding the collected data first. Let us import all the necessary libraries for data visualization.
import pandas as pd import numpy as np import altair as alt import seaborn as sns import matplotlib.pyplot as plt import missingno as msno
Next, we will import the created dataset for fitness trackers.
df=pd.read_csv('/content/FitnessBands.csv',thousands=',')
df.head()

df.shape
>>(565, 11)
This fitness trackers dataset contains 565 samples with 11 attributes and some missing values.
#check for data types df.dtypes

#distribution of data df.describe().T

Missing values
Let us find details about the missing values in this dataset.
color=['#4895ef','#4895ef','#a5a58d','#a5a58d','#a5a58d','#a5a58d','#a5a58d','#a5a58d','#a5a58d','#a5a58d','#a5a58d'] msno.bar(df,figsize=(10,4), color=color,fontsize=12,sort="ascending")
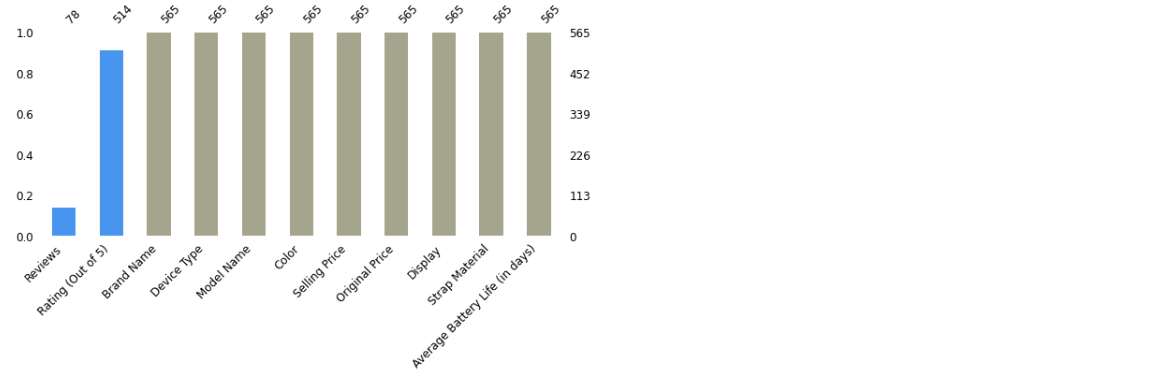
From the above bar chart, we can visualize that there are missing values in two columns – Reviews and Rating (Out of 5)
Now, it would be interesting to see if we can answer these interesting questions based on the dataset through an EDA.
1. Is there a clear demand for fitness trackers in the Indian market?
2. How many types of trackers and Players are there for fitness trackers?
3. Which are the top 5 brands for fitness bands and smartwatches?
4. Which brand has the highest number of products?
5. Are fitness trackers with higher ratings more expensive?
6. Do expensive fitness trackers have better battery performance?
7. Are mid-priced trackers mostly available at discounted prices?
8. Which is the most commonly available colour for trackers?
9. Which is the most commonly available strap material for trackers?
10. What are the Average Selling Prices by Brands?
Assume these answers appear in a business report, then by looking at the above questions from a business perspective, we can understand that each of these questions is realistic in generating insight for a business decision. For example, if there are multiple players with strong demand for the product, a company can decide to enter the market for a specific type of fitness tracker. Looking at the average selling prices, a company can smartly position their product in a particular price segment. Even, the company can decide on how many features, colours or strap materials they want to offer the customers based on their competitors. It is important to note that companies do have access to a lot of additional data based on sales and customer feedback for making informed business decisions. Such data cannot be made available even for educational or research purposes. Hence, the aim of this tutorial is to highlight the use of Python as a tool for Market analysis in generating insights for a certain product.
Analyse Demand for fitness trackers in the market
To see if there is a clear demand in the market, there would be multiple products offered by several manufacturers. So, we perform a count() of the products grouped by type using the panda’s command.
# count of products df['Brand Name'].groupby(df['Device Type']).count().sort_values(ascending=False)
>>Device Type
>>Smartwatch 490
>>FitnessBand 75
>>Name: Brand Name, dtype: int64
It is obvious that there are multiple fitness trackers for sale on this e-commerce website. The same information can also be presented using a pie chart using matplotlib.
# Device Type distribution
labels = 'Smart watches', 'Fitness bands'
sizes = [490,75]
fig1, ax1 = plt.subplots()
fig1.set_facecolor('black')
ax1.pie(sizes, labels=labels, colors=["#4361EE",'#b5179e'],autopct='%1.1f%%', startangle=90,textprops={'color':'w','weight':'bold','fontsize':12.5})
ax1.axis('equal')
plt.show()

Apparently, there is greater demand for smartwatches looking at the proportions in the pie chart. Next, we check how many companies are currently in the market offering these products.
Number of Players in the market
#count of brands df['Brand Name'].nunique()
>>20
Thus, there are currently 490 smartwatches and 75 fitness bands on sale from 20 different brands. This indicates that there is a good demand for Fitness Trackers in the current scenario in the Indian market.
Which are the top 5 brands for fitness tracker bands and smartwatches in the market?
To get this information, we group the data by brands and order it by the count of products. We can visualize this information in a simple horizontal bar chart in seaborn.
df['Brand Name'].groupby(df['Brand Name']).count().sort_values(ascending=False).iloc[:5]
#product counts
sns.set_style('white')
sns.countplot(y="Brand Name", hue="Device Type", data=df, palette=["#560bad","#4361EE"],
order=df["Brand Name"].value_counts().iloc[:5].index)
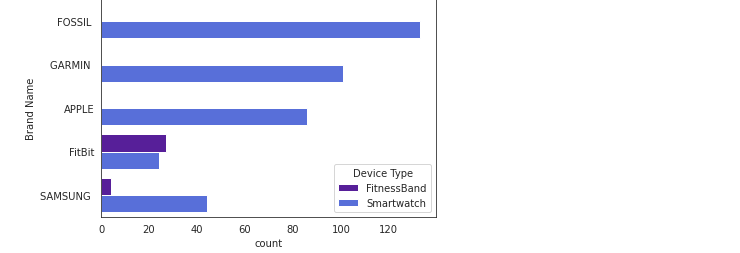
From this bar chart, we can understand that Fossil, Garmin, Apple, Fitbit and Samsung are the top 5 brands offering the most fitness trackers. Fossil, Garmin and Apple seem to offer only smartwatches while FitBit and Samsung offer both fitness bands and smartwatches.
Which fitness tracker brand has the highest number of products in the market?
To find which brand offers the maximum number of products, we group the data by Brand name for the device type column and limit the query result to 1 for the top values.
df['Device Type'].groupby(df['Brand Name']).count().sort_values(ascending=False).iloc[:1]
>>Brand Name
>>FOSSIL 133
>>Name: Device Type, dtype: int64
It is clear that Fossil brand has the most number of products = 133 i.e. Smartwatches
Are fitness trackers with higher ratings more expensive?
Apart from the previous questions, we can try to discover something interesting like ‘is expensive always better in ratings’? For this, we again group the data by Brand name and find out the mean ratings for each brand.
#average ratings by Brand
round(df.groupby('BrandName')['Rating (Out of 5)'].mean().sort_values(ascending=False).iloc[:10],1)
These are the top 10 brands with average ratings out of 5. Let us display this information along with ‘Selling price’ using a strip plot in seaborn.
# Rating vs Selling Price #filter by Brand list = ["APPLE","OnePlus","FOSSIL","SAMSUNG","Honor","FitBit","Xiaomi","Huawei","huami",”realme”] series = df["Brand Name"].isin(list) df_f = df[series] fig, ax = plt.subplots(figsize=(15,6)) ax = sns.stripplot(x="Rating (Out of 5)", y="Selling Price", data=df_f,hue="Brand Name", palette=colors,size=7, marker="o")
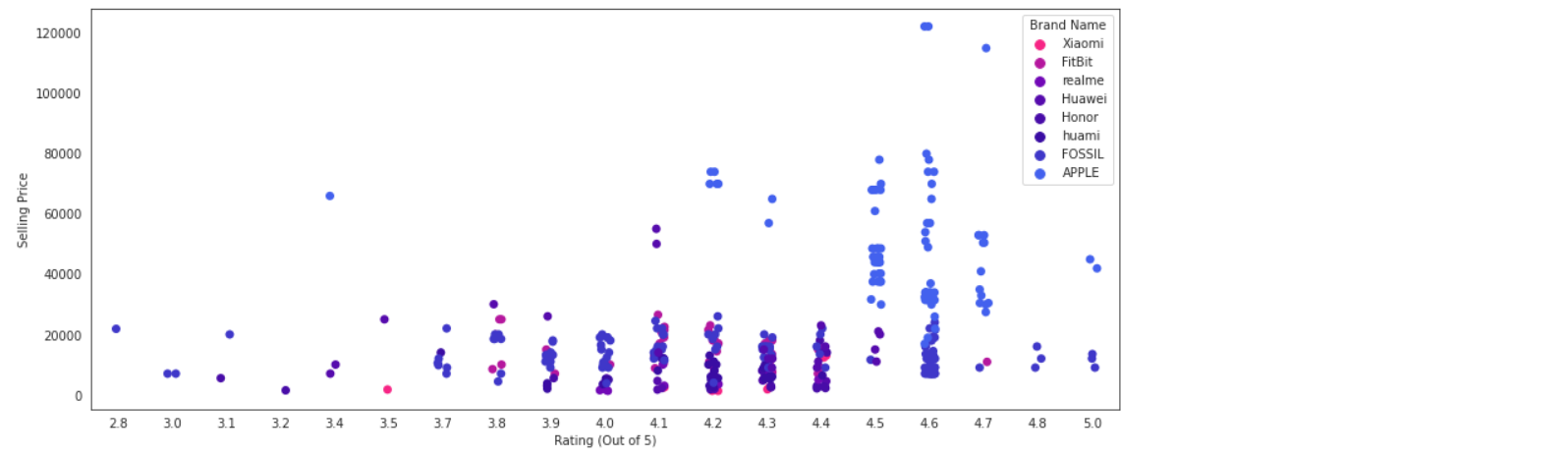
From the above strip plot, it is clear that most of the expensive brands seem to enjoy a higher rating.
Do expensive fitness trackers have better battery performance?
Next, we will check if expensive fitness trackers give a better battery life. Since these devices are continuously collecting data for the user; it is important that they provide quick charging with a longer duration between subsequent recharge. To find this information, let us group the data by Brand Name once again for the mean of ‘Average Battery Life (in days)’.
# Brandwise Mean Selling prices
round(df.groupby('Brand Name')['Average Battery Life (in days)'].mean(),0).sort_values(ascending=False)
This can also be visualized using a bar plot as shown below.
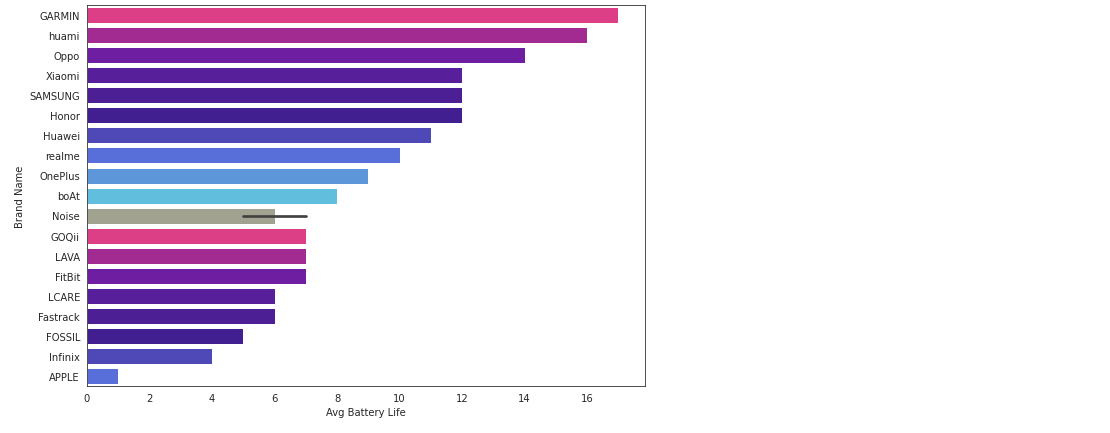
From the above bar plot, Garmin seems to provide the best battery life in days as an expensive brand. Samsung on the other hand gives around 12 days of battery life, a week less than Garmin. Most Apple products provide only a 1-2 days battery life. Similarly, Fossil is an expensive brand but offers a very low battery life of less than a week. Thus, we can infer that both Garmin and Fossil brands are expensive but do not have comparable battery life. Hence, expensive does not always equal better battery life for the fitness tracker.
Are mid-priced trackers mostly available at discounted prices?
This would be interesting to see if prices have an impact on the discount. Since we have only the selling price and original price, we can filter out the data within 10K to 30K INR selling price for the fitness trackers. This filtered data could be visualized as a scatter plot to identify if the mid-priced ones are almost all at discounted prices. We will use Altair scatter plot to build an interactive plot for this visualization.
#filter dataframe
df_p=df[(df["Selling Price"] >= 10000) & (df["Selling Price"] <= 30000)]
df_p.iloc[:2]
alt.Chart(df_p).mark_point(filled=True,size=40).encode(
x='Original Price',
y='Selling Price',
color='Brand Name',
tooltip=['Brand Name', 'Selling Price', 'Original Price']
).interactive()
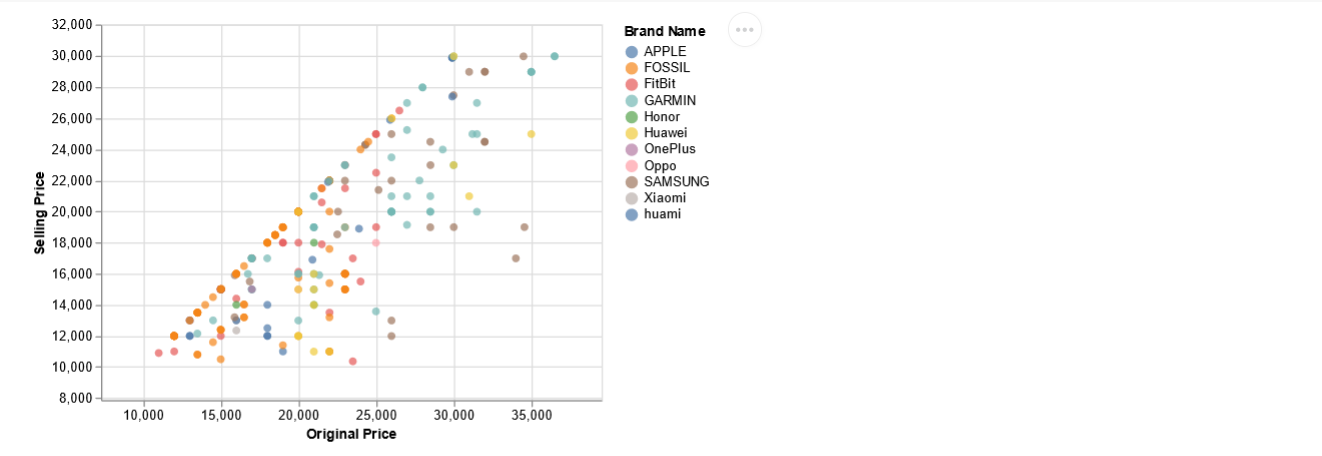
It appears that since more products are available in the mid-price segment, the discounted products are also more in the same segment as well. Hence, we could infer that mid-price segments are available mostly at discounted prices. (This is based on the situation when the data was scraped and is likely to change).
Most commonly available colour for fitness trackers in the market
Now, we look at the colours offered by different manufacturers for fitness trackers. We will perform a count() of the colours for device types. We will build a count plot for this information using seaborn.
#Color counts sns.countplot(y="Color", hue="Device Type", data=df, palette=colors, order=df["Color"].value_counts().iloc[:5].index)

From the count plot, it is obvious that Black colour seems to be the most offered colour in both Smartwatches and fitness bands.
Most commonly available strap material for trackers
For the strap material, we will build a count plot using seaborn similar to the count plot for colour.
#Color counts sns.countplot(y="Strap Material", hue="Device Type", data=df, palette=colors, order=df["Strap Material"].value_counts().iloc[:5].index)
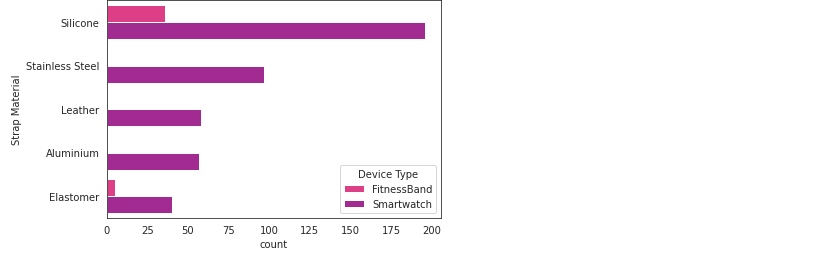
From this count plot, we can clearly see that Silicone and Elastomer are the most common choices for Fitness Bands while Silicone, Stainless Steel, Leather and Aluminium seem to be the top choices for Smart Watches.
Average Selling Price by Brand and Most Expensive Brand
Finally, we look at the average selling prices of these fitness trackers from different brands.
# Brandwise Mean Selling prices
df.groupby('Brand Name')['Selling Price'].mean().sort_values(ascending=False).apply(np.ceil)

We can also use a Boxplot in seaborn to visualize this information.
#Box plot to denote average selling prices fig, ax = plt.subplots(figsize=(20,5)) ax = sns.boxplot(x="Brand Name", y="Selling Price", data=df,palette=colors)
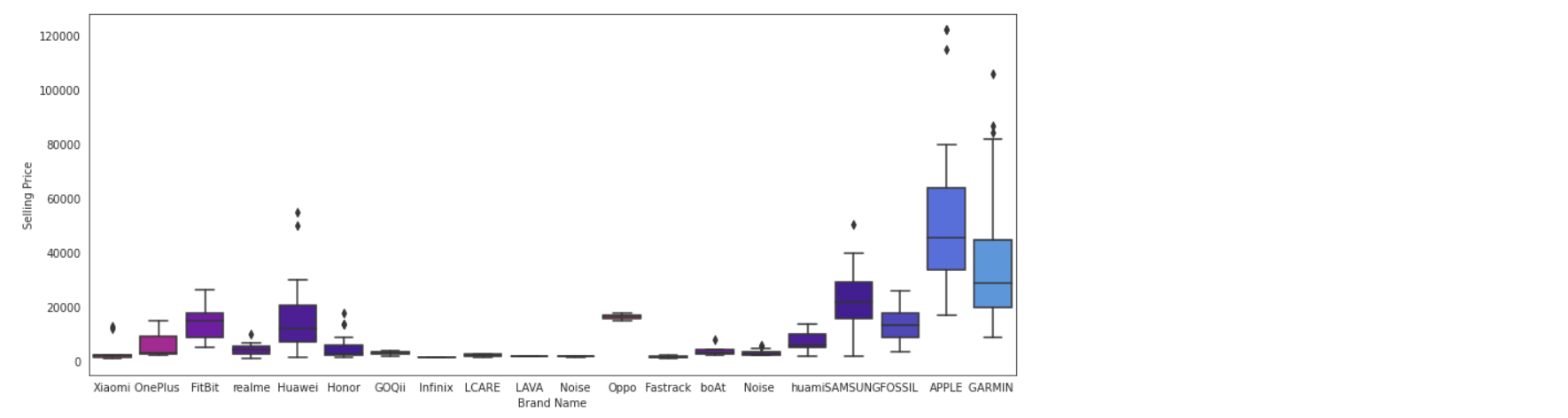
From the boxplot, the average price of a tracker from Apple is around 50K INR while the average price for Garmin trackers is around 35K INR. Fitness Trackers from Samsung are priced at an average of 22K INR. Further, products from Apple are the most expensive while FitBit seems to offer the maximum number of mid-price range products.
Conclusion
It was obvious from this EDA that there are many players in the market offering multiple variants of two types of fitness trackers (smartwatch and fitness band). This implies that there is good demand for these devices in the Indian market. Further, there is a wide choice of prices ranging from low-price segment (up to 10,000 INR), mid-price or budget segment (up to 30,000 INR – since most trackers fall in this range), premium segment (30,000-50,000 INR) and high-end or top-end trackers costing up to even 1 lac INR. Customers can choose from various colours and materials offered by these manufacturers. In summary, we saw a detailed EDA on the fitness tracker market using Python and its open-source data visualization libraries. The list of questions used in this EDA is by no means an exhaustive list. So, feel free to ask some different questions to the dataset and gain interesting insights.
The dataset used in this tutorial is available on Kaggle and GitHub. You could also scrape and create your own dataset using Pyscrappy for the same product or a different product.
The notebook for this EDA is available on my GitHub repository.
Thanks for reading this article.
Author Bio:
Devashree has an M.Eng degree in Information Technology from Germany and a Data Science background. As an Engineer, she enjoys working with numbers and uncovering hidden insights in diverse datasets from different sectors to build beautiful visualizations to try and solve interesting real-world machine learning problems.
In her spare time, she loves to cook, read & write, discover new Python-Machine Learning libraries or participate in coding competitions.
You can follow her on LinkedIn, GitHub, Kaggle, Medium, Twitter.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion
Devashree has an M.Eng degree in Information Technology from Germany and a Data Science background. As an Engineer, she enjoys working with numbers and uncovering hidden insights in diverse datasets from different sectors to build beautiful visualizations to try and solve interesting real-world machine learning problems.
In her spare time, she loves to cook, read & write, discover new Python-Machine Learning libraries or participate in coding competitions.


