This article was published as a part of the Data Science Blogathon.
There is a wide variety of data available on the internet. Data can be numbers, images, text, audio, and son. The vast amount of data available online and generated is vast. The vast amount of text data can be overwhelming to analyze and understand. Text data generated can be blogs, articles, amazon reviews, and so on. The problem with text data is that we cannot add or subtract it like numerical data. There are a lot of ways to analyze numeric data, but the ways to process and analyze text data are limited.

( Image: https://www.pexels.com/photo/business-charts-commerce-computer-265087/ )
What is NLP?
The method used to analyze and process text data is known as Natural Language Processing. Natural Language Processing can be used to derive meaning and sentiment from raw text data. These can be used to create text-based use cases and other data-driven applications. These text analysis methods can be very useful in large-scale text mining and text classification applications.
There are various libraries for NLP, which are open source and are free for everyone to use. They are Spacy, NLTK, Pattern, TextBlob, etc.
What is Pattern Library?
Pattern is an extremely useful library in Python, that can be used to implement Natural Language processing tasks. The pattern is an open source, and free for anyone to use. It can be used for Text Mining, NLP, and Machine Learning.
We can install Pattern using the following command.
pip install pattern
Let us now get started.
Parsing using Pattern
We can use parsing to understand the different words in a sentence and differentiate them as a noun, verbs, etc. We can also apply various parameters and customize the function.
We can also retrieve the tokens by setting the lemma parameter to True. Now, let us implement the parse function.
from pattern.en import parse
from pattern.en import pprint
pprint(parse('Hello I am John, I work at the bank.', relations=True, lemmata=True))
Output:
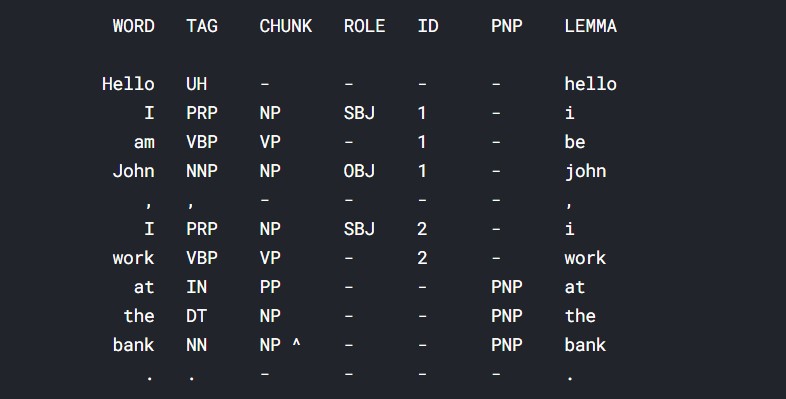
We can see that all the words have been tokenized and they have been identified. For example, “am” is tagged as a verb and its lemma is “be”. “Bank” is a noun and its lemma is unchanged, as “bank”. The role of “I” as a subject is also identified. The next “I” and “John” are objects. So, we can see that the parse function really does a great job at identifying the roles of all the tokens of a word.
Now, let us add a parameter and increase the length of the sentence.
pprint(parse('Enzo Ferrari was not initially interested in the idea of producing road cars when he formed Scuderia Ferrari in 1929, with headquarters in Modena.', relations = True,tokenize= True, lemmata= True))
Output:
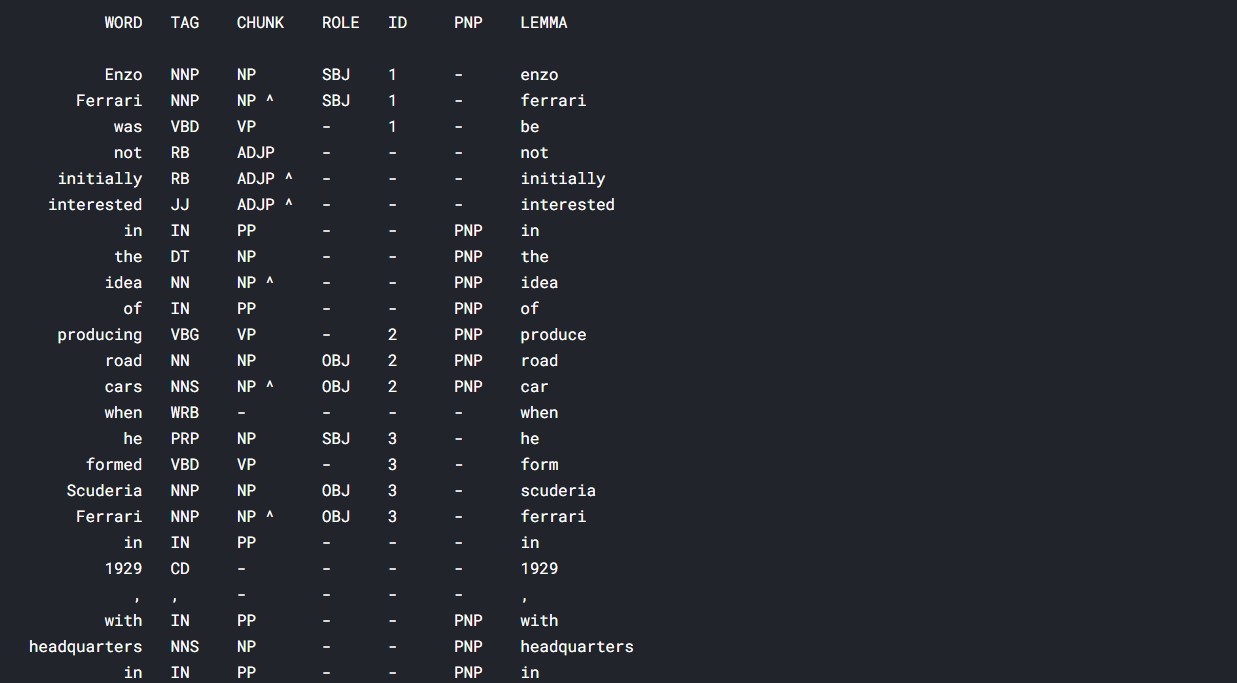
It might be a bit difficult to see the output here, but I will share the link to the notebook in the end, have a look.
So, all the words have been identified, and we can understand the role of all the tokens. The lemmatization is also nicely done, for example, “producing” got lemmatized to “produce”, and “formed” got lemmatized to “form”.
N-Grams using Pattern
N-Grams are a constant sequence of words/ tokens, from a given text or document. They are a probabilistic language model used for predicting the next word in a sequence of tokens/ words. So, the “N” is basically the number of words in the N-gram. Let us now implement N-Grams using Python. First, we try with N=3.
from pattern.en import ngrams
#n grams
print(ngrams("There is nothing either good or bad, but thinking makes it so.", n=3))
Output:
[('There', 'is', 'nothing'), ('is', 'nothing', 'either'), ('nothing', 'either', 'good'), ('either', 'good', 'or'), ('good', 'or', 'bad'), ('or', 'bad', 'but'), ('bad', 'but', 'thinking'), ('but', 'thinking', 'makes'), ('thinking', 'makes', 'it'), ('makes', 'it', 'so')]
So, we can see that the group of tokens is 3.
Now, let us take n=5.
#n grams
print(ngrams("There is nothing either good or bad, but thinking makes it so.", n=5))
Output:
[('There', 'is', 'nothing', 'either', 'good'), ('is', 'nothing', 'either', 'good', 'or'), ('nothing', 'either', 'good', 'or', 'bad'), ('either', 'good', 'or', 'bad', 'but'), ('good', 'or', 'bad', 'but', 'thinking'), ('or', 'bad', 'but', 'thinking', 'makes'), ('bad', 'but', 'thinking', 'makes', 'it'), ('but', 'thinking', 'makes', 'it', 'so')]
Now, let us take it as 7.
#n grams
print(ngrams("There is nothing either good or bad, but thinking makes it so.", n=7))
Output:
[('There', 'is', 'nothing', 'either', 'good', 'or', 'bad'), ('is', 'nothing', 'either', 'good', 'or', 'bad', 'but'), ('nothing', 'either', 'good', 'or', 'bad', 'but', 'thinking'), ('either', 'good', 'or', 'bad', 'but', 'thinking', 'makes'), ('good', 'or', 'bad', 'but', 'thinking', 'makes', 'it'), ('or', 'bad', 'but', 'thinking', 'makes', 'it', 'so')]
Here, the tokens are grouped as 7.
Sentiment Analysis with Pattern Library
Sentiment Analysis is the application of Text Analytics that deals with understanding emotions and human sentiment from text data. It can be used to understand opinions or views expressed by a particular text. The function in Pattern returns polarity and the subjectivity of a given text.
The Polarity result ranges from highly Positive to highly negative (1 to -1)
The subjectivity ranges from 0(Objective) to 1(Subjective).
Let us analyze some texts and see the result.
from pattern.en import sentiment
print(sentiment("The course of true love never did run smooth."))
Output:

Let us try with some other sentences.
print(sentiment("The food is bad and disgusting, I donot like it."))
Output:

print(sentiment("Hell is empty and all the devils are here."))
Output:

print(sentiment("I love you."))
Output:

print(sentiment("Kolkata is very beautiful."))
Output:

print(sentiment("This is an excellent movie, I really love it"))
Output:

So, we can understand that the function is able to analyze and tell the sentiment scores.
For sentences having bad or negative sentiments, the function gave negative polarity scores.
Word Corrections using Pattern
Pattern library also has inbuilt functions which can assist in spelling corrections. The function “suggest” gives a list of words that may be the correct usage word. Let us try out the function.
#suggest
from pattern.en import suggest
print(suggest("Aerplane"))
Output:
[('Airplane', 1.0)]
We see that the function returns with full confidence that Airplane will be the correct word.
Let us try with a different word.
print(suggest("Ambulnce"))
Output:
[('Ambulance', 1.0)]
So, here the function confidently states that the word is “ambulance”.
Let us try a different case.
print(suggest("Cmputer"))
Output:
[('Computer', 0.75), ('Imputed', 0.125), ('Muter', 0.0625), ('Impute', 0.0625)]
Here, the function was not sure which is the correct word, so it returned a list of words that might be the correct word.
print(suggest("Entertanment"))
Output:
[('Entertainment', 1.0)]
Now, let us try a different case.
print(suggest("Almnd"))
Output:
[('Land', 0.7380952380952381), ('Gland', 0.13756613756613756), ('Blind', 0.06084656084656084),
('Lend', 0.0291005291005291), ('Bland', 0.015873015873015872), ('Blend', 0.010582010582010581), ('Almond', 0.007936507936507936)]
In this case, also, the function returned a list of words that might be the actual word. This type of function can perform really great and can be used in various NLP operations.
Quantify
This function gives a word count estimation of the words given. Let us see the implementation.
#Quantify from pattern.en import quantify a = quantify(['Car', 'Car', 'Bus', 'Truck', 'Train', 'Car', 'Bus', 'Truck']) print(a)
Output:
several Cars, a pair of Trucks, a pair of Buss and a Train
So, here we see that the words have been quantified, and estimation on their numbers have been provided.
Let us try with different words now.
b = quantify(['Car', 'Car', 'Bus', 'Ambulance','Bus', 'Truck','Bus','Bus', 'Truck','FireTruck']) print(b)
Output:
several Buss, a pair of Trucks, a pair of Cars, a FireTruck and a Ambulance
Now, let us add numbers and see the result.
print(quantify({'Bus': 100, 'Car': 1500,'Truck': 700}))
print(quantify('People', amount=60000))
Output:
thousands of Cars, hundreds of Trucks and dozens of Buss tens of thousands of Peoples
When we added the numbers, we can see that the values of estimation increased.
print(quantify({'Truck': 11, 'Car': 57808,'Bicycle': 564658}))
Output:
hundreds of thousands of Bicycles, tens of thousands of Cars and a number of Trucks
Other numeric functions:
Let us try the function number and numerals which can convert numbers to words and vice versa. They are a good word to deal with numeric data in text. For example, if we have a lot of numeric data in the form of words, we can use this function to get this data as numbers.
from pattern.en import number, numerals
print(number("ten thousand five hundred seventy one"))
print(numerals(567.79585, round=3))
Output:
10571 five hundred and sixty-seven point seven hundred and ninety-six
So, we got the output as desired.
In the case of the ‘numerals’ function, we can use the “round” parameters to round off the numbers.
Singular and Plural in Pattern
The name of these functions explains what they do. Let us try them out.
from pattern.en import pluralize, singularize
print(pluralize('car'))
print(singularize('BUSES'))
Output:
cars BUS
So, the words got changed accordingly.
Let us try with some different words.
print(pluralize('Student'))
print(singularize('chocolates'))
Output:
Students chocolate
So, the function is working properly.
Converting the Adjective to Comparative and Superlative Degrees
We can find out comparative and superlatives of words using the Pattern library. This is an interesting function, which can be used to make changes to words.
from pattern.en import comparative, superlative
print(comparative('bad'))
print(superlative('bad'))
Output:
worse worst
The output is as desired. Let us try a different word.
print(comparative('beautiful'))
print(superlative('beautiful'))
Output:
more beautiful most beautiful
The function gives the desired output.
print(comparative('good'))
print(superlative('good'))
Output:
better best
So, we can see that the pattern library has many uses and applications.
Data Mining
Pattern library can also be used for data mining operations. Let us try Data mining from Google search and Twitter. Such applications can be used to retrieve text data and information and make a certain process automated.
Let us first get started with data mining from Google.
from pattern.web import Google
google = Google()
for results in google.search('Ferrari'):
print(results.url)
print(results.text)
Output:
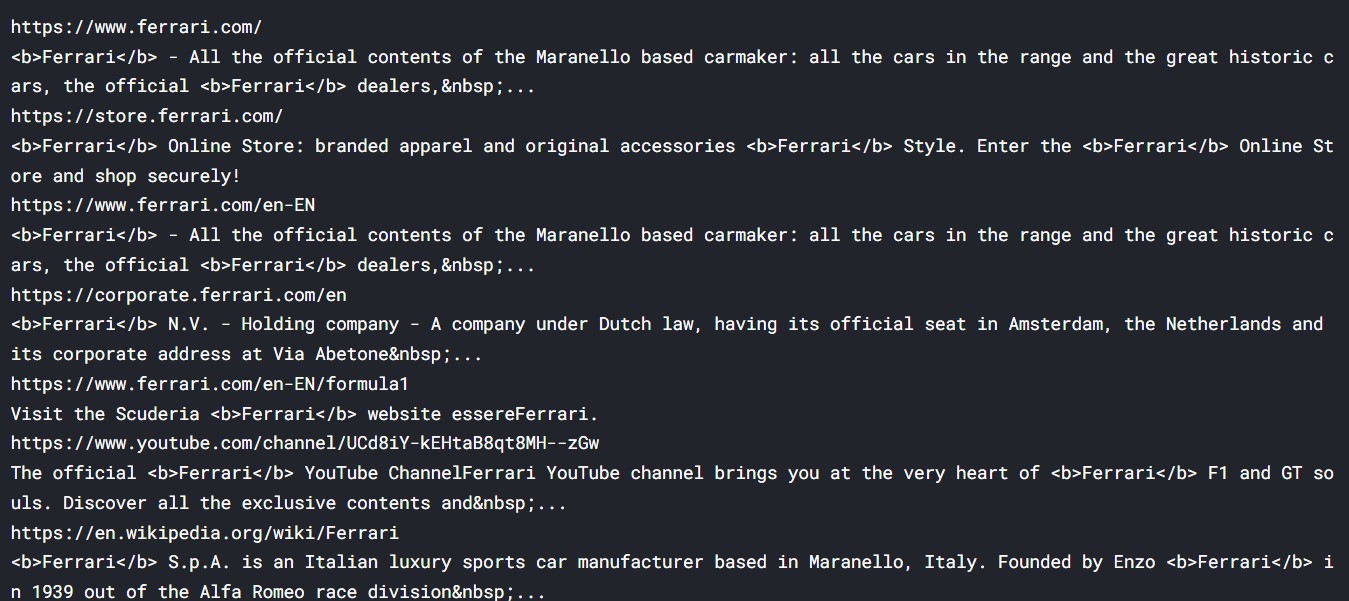
So, the output basically has the links and the text in the google search results. This type of result makes it easy to understand the webpage rankings and search nature. The output here is limited, please do check out the notebook link.
Let us try with a different search query.
for results in google.search('NASA'):
print(results.url)
print(results.text)
Output:
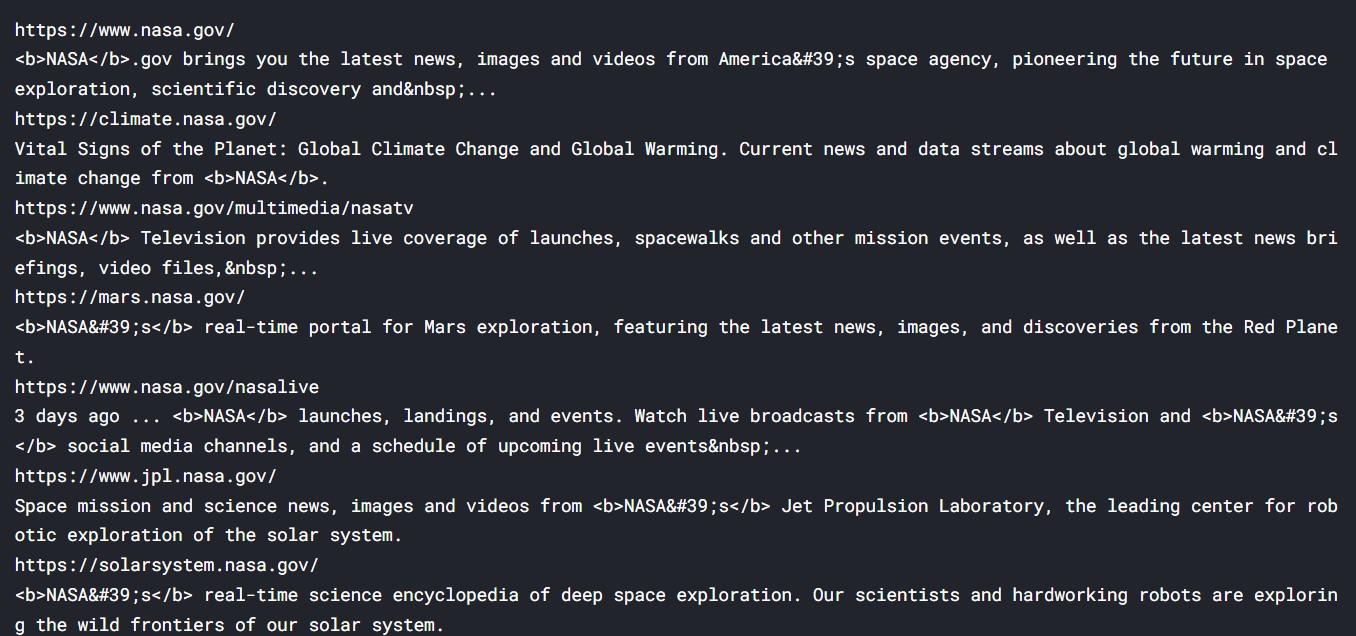
So, the results are fine.
Let us check the type() of these results.
print(type(results.text))
Output:
The text is a standard string.
print(type(results))
Output:
The results are a special object.
Now, let us try extracting data from Twitter.
from pattern.web import Twitter
twitter = Twitter()
for results in twitter.search('Tesla'):
print(results.url)
print(results.text)
Output:
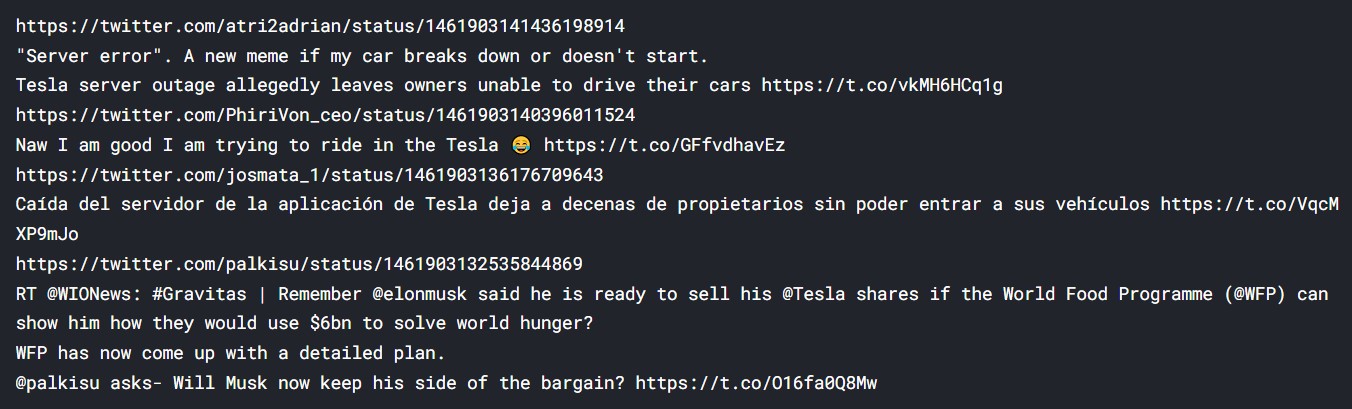
The result is as expected.
Conclusion
The pattern is a really powerful library for NLP and other text-related operations. The community support is not as good as spacy/ NLTK, but it has good functions and uses. The best part about it is that it is free and open source.
The unique features are it has quantifying functions which make it very useful in dealing with numeric data and converting it into usage for text data.
Kaggle Notebook:
https://www.kaggle.com/prateekmaj21/python-for-nlp-using-pattern-library
About me
Prateek Majumder
Analytics | Content Creation
Connect with me on Linkedin.
My other articles on Analytics Vidhya: Link.
Thank You.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.



