What is ETL?
ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
It’s easy to believe that building a Data warehouse is as simple as pulling data from numerous sources and feeding it into a Data warehouse database. This is far from the case, and a complicated ETL procedure is required. The ETL process, which is technically complex, involves active participation from a variety of stakeholders, including developers, analysts, testers, and senior executives.
To preserve its value as a decision-making tool, the data warehouse system must develop in sync with business developments. ETL is a regular (daily, weekly, monthly) process of a data warehouse system that must be agile, automated, and properly documented.
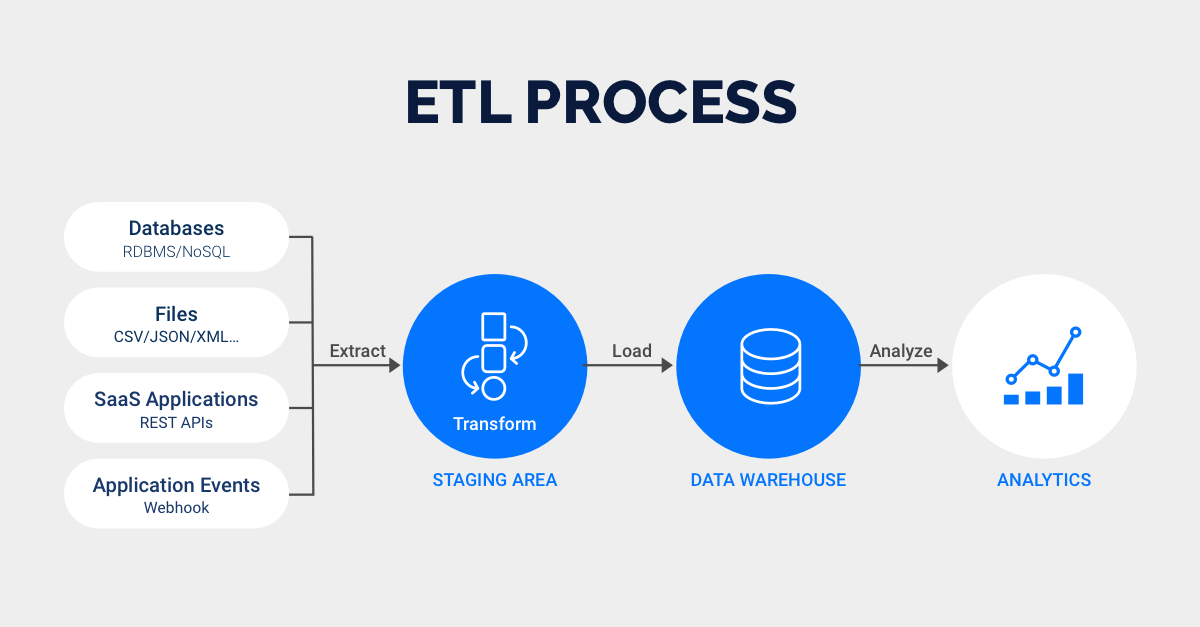
How Does ETL Work?
Here we will learn how the ETL process works step by step:
Step 1) Extraction
Data is extracted from the source system and placed in the staging area during extraction. If any transformations are required, they are performed in the staging area so that the performance of the source system is not harmed. Rollback will be difficult if damaged data is transferred directly from the source into the Data warehouse database. Before moving extracted data into the Data warehouse, it can be validated in the staging area.
Data warehouses can combine systems with different hardware, database management systems, operating systems, and communication protocols. Data warehouses must combine systems with disparate DBMS, hardware, operating systems, and communication protocols. Sources might include legacy programs such as mainframes, customized applications, point-of-contact devices such as ATMs and call switches, text files, spreadsheets, ERP, data from vendors and partners, and so on.
Thus, before extracting data and loading it physically, a logical data map is required. The connection between sources and target data is shown in this data map.
Three Data Extraction methods:
- Partial Extraction – If the source system alerts you when a record is modified, that is the simplest way to obtain the data.
- Partial Extraction (without update notification) – Not all systems can deliver a notification when an update occurs; but, they can indicate to the records that have been changed and provide extraction of those records.
- Full extract – Certain systems are incapable of determining which data has been changed at all. In this scenario, the only way to get the data out of the system is to perform a full extract. This approach requires having a backup of the previous extract in the
same format on hand in order to identify the changes that have been done.
Regardless of the method adopted, extraction should not have an impact on the performance or response time of the source systems. These are real-time production databases. Any slowdown or locking might have an impact on the company’s bottom line.
Step 2) Transformation
The data retrieved from the source server is raw and unusable in its original state. As a result, it must be cleaned, mapped, and transformed. In reality, this is the key step in where the ETL process adds value and transforms data in order to produce meaningful BI reports.
It is a key ETL concept in which you apply a collection of functions to extracted data. Direct move or pass through data is the type of data that does not require any transformation.
You can execute customized operations on data during the transformation step. For example, suppose the client wants a sum-of-sales revenue that does not exist in the database. or if the first and last names in a table are in separate columns. Before loading, they can be concatenated.
The following are some examples of data integrity issues:
- Different spellings of the same individual, such as Prashant, Parshant, and etc.
- There are many ways to represent a company name, such as Google, Google Inc.
- Various names, such as Cleaveland and Cleveland, are used.
- It is possible that multiple account numbers are produced by different applications for the same client.
- Some data needed files are left blank.
Step 3) Loading
The final stage in the ETL process is to load data into the target data warehouse database. A large volume of data is loaded in a relatively short period of time in a typical data warehouse. As a result, the load process should be optimized for performance.
In the occurrence of a load failure, recovery procedures should be put in place so that operations can restart from the point of failure without compromising data integrity. Data Warehouse administrators must monitor, continue, and stop loads based on server performance.
Types of Loading:
- Initial Load — filling all of
the Data Warehouse tables - Incremental Load — implementing ongoing
modifications as needed on a regular basis - Full Refresh — clearing the contents
of one or more tables and reloading them with fresh data
Load verification
- Check that the key field data is not missing or null.
- Modelling views based on target tables should be tested.
- Examine the combined values3 and computed measures.
- Data checks in the dimension and history tables.
- Examine the BI reports on the loaded fact and dimension table.
Setting Up ETL Using PythonScript
As a result, you must execute basic Extract Transform Load (ETL) from several databases to a data warehouse in order to do data aggregation for business intelligence. There are several ETL packages available that you believed were excessive for your basic use case.
I’ll show you how to extract data from MySQL, SQL-server, and firebird in this article. Using Python 3.6, transform the data and load it into SQL-server (data warehouse).
First of all, we have to create a directory for our project:
python_etl
|__main.py
|__db_credentials.py
|__variables.py
|__sql_queries.py
|__etl.py
To set up ETL using Python, you’ll need to generate the following files in your project directory.
- db_credentials.py: Should have all of the information needed to connect to all databases. such as Database Password, Port Number, etc.
- sql_queries.py: All commonly used database queries for extracting and loading data in String format should be available.
- etl.py: Connect to the database and conduct the needed queries by performing all necessary procedures.
- main.py: Responsible for managing the flow of operations and executing the essential operations in a specified order.
In this section of sql_queries.py, this is the place where we are going to store all of our sql queries for extracting from source databases and importing into our target database (data warehouse)
- Python to MySQL Connector: MySQL-connector-python
- Python to Microsoft SQL Server Connector: pyodbc
- Python to Firebird Connector: fdb
Setup Database Credentials and Variables
In variables.py, create a variable to record the name of the data warehouse database.
datawarehouse_name = 'your_datawarehouse_name'
Configure all of your source and target database connection strings and credentials in db_credentials.py as shown below. Save the configuration as a list so that we can iterate it whenever required through many databases later.
from variables import datawarehouse_name
datawarehouse_name = 'your_datawarehouse_name'
# sql-server (target db, datawarehouse)
datawarehouse_db_config = {
'Trusted_Connection': 'yes',
'driver': '{SQL Server}',
'server': 'datawarehouse_sql_server',
'database': '{}'.format(datawarehouse_name),
'user': 'your_db_username',
'password': 'your_db_password',
'autocommit': True,
}
# sql-server (source db)
sqlserver_db_config = [
{
'Trusted_Connection': 'yes',
'driver': '{SQL Server}',
'server': 'your_sql_server',
'database': 'db1',
'user': 'your_db_username',
'password': 'your_db_password',
'autocommit': True,
}
]
# mysql (source db)
mysql_db_config = [
{
'user': 'your_user_1',
'password': 'your_password_1',
'host': 'db_connection_string_1',
'database': 'db_1',
},
{
'user': 'your_user_2',
'password': 'your_password_2',
'host': 'db_connection_string_2',
'database': 'db_2',
},
]
# firebird (source db)
fdb_db_config = [
{
'dsn': "/your/path/to/source.db",
'user': "your_username",
'password': "your_password",
}
]
SQL Queries
In this section of sql_queries.py, this is the place where we are going to store all of our sql queries for extracting from source databases and importing into our target database (data warehouse).
We have to implement various syntaxes for every database because we are working with multiple data platforms. We can do this by separating the queries based on the database type.
# example queries, will be different across different db platform
firebird_extract = ('''
SELECT fbd_column_1, fbd_column_2, fbd_column_3
FROM fbd_table;
''')
firebird_insert = ('''
INSERT INTO table (column_1, column_2, column_3)
VALUES (?, ?, ?)
''')
firebird_extract_2 = ('''
SELECT fbd_column_1, fbd_column_2, fbd_column_3
FROM fbd_table_2;
''')
firebird_insert_2 = ('''
INSERT INTO table_2 (column_1, column_2, column_3)
VALUES (?, ?, ?)
''')
sqlserver_extract = ('''
SELECT sqlserver_column_1, sqlserver_column_2, sqlserver_column_3
FROM sqlserver_table
''')
sqlserver_insert = ('''
INSERT INTO table (column_1, column_2, column_3)
VALUES (?, ?, ?)
''')
mysql_extract = ('''
SELECT mysql_column_1, mysql_column_2, mysql_column_3
FROM mysql_table
''')
mysql_insert = ('''
INSERT INTO table (column_1, column_2, column_3)
VALUES (?, ?, ?)
''')
# exporting queries
class SqlQuery:
def __init__(self, extract_query, load_query):
self.extract_query = extract_query
self.load_query = load_query
# create instances for SqlQuery class
fbd_query = SqlQuery(firebird_extract, firebird_insert)
fbd_query_2 = SqlQuery(firebird_extract_2, firebird_insert_2)
sqlserver_query = SqlQuery(sqlserver_extract, sqlserver_insert)
mysql_query = SqlQuery(mysql_extract, mysql_insert)
# store as list for iteration
fbd_queries = [fbdquery, fbd_query_2]
sqlserver_queries = [sqlserver_query]
mysql_queries = [mysql_query]
Extract Transform Load
To set up ETL using Python for the above-mentioned data sources, you’ll need the following modules:
# python modules import mysql.connector import pyodbc import fdb # variables from variables import datawarehouse_name
We can use two techniques in this: etl() and etl_process().
etl_process() is the procedure for establishing a database source connection and calling the etl() method based on the database platform.
And in the second method which is etl() method, it runs the extract query first, then stores the SQL data in the variable data and inserts it into the targeted database, which is our data warehouse. Data transformation may be accomplished by altering the data variable of the type tuple.
def etl(query, source_cnx, target_cnx):
# extract data from source db
source_cursor = source_cnx.cursor()
source_cursor.execute(query.extract_query)
data = source_cursor.fetchall()
source_cursor.close()
# load data into warehouse db
if data:
target_cursor = target_cnx.cursor()
target_cursor.execute("USE {}".format(datawarehouse_name))
target_cursor.executemany(query.load_query, data)
print('data loaded to warehouse db')
target_cursor.close()
else:
print('data is empty')
def etl_process(queries, target_cnx, source_db_config, db_platform):
# establish source db connection
if db_platform == 'mysql':
source_cnx = mysql.connector.connect(**source_db_config)
elif db_platform == 'sqlserver':
source_cnx = pyodbc.connect(**source_db_config)
elif db_platform == 'firebird':
source_cnx = fdb.connect(**source_db_config)
else:
return 'Error! unrecognised db platform'
# loop through sql queries
for query in queries:
etl(query, source_cnx, target_cnx)
# close the source db connection
source_cnx.close()
Putting Everything Together
Now, in the next step, We can loop over all credentials in main.py and execute the etl for all databases.
For that we have to Import all required variables and methods:
# variables from db_credentials import datawarehouse_db_config, sqlserver_db_config, mysql_db_config, fbd_db_config from sql_queries import fbd_queries, sqlserver_queries, mysql_queries from variables import * # methods from etl import etl_process
The code in this file is responsible for iterating over credentials in order to connect to the database and execute the necessary ETL Using Python operations.
def main():
print('starting etl')
# establish connection for target database (sql-server)
target_cnx = pyodbc.connect(**datawarehouse_db_config)
# loop through credentials
# mysql
for config in mysql_db_config:
try:
print("loading db: " + config['database'])
etl_process(mysql_queries, target_cnx, config, 'mysql')
except Exception as error:
print("etl for {} has error".format(config['database']))
print('error message: {}'.format(error))
continue
# sql-server
for config in sqlserver_db_config:
try:
print("loading db: " + config['database'])
etl_process(sqlserver_queries, target_cnx, config, 'sqlserver')
except Exception as error:
print("etl for {} has error".format(config['database']))
print('error message: {}'.format(error))
continue
# firebird
for config in fbd_db_config:
try:
print("loading db: " + config['database'])
etl_process(fbd_queries, target_cnx, config, 'firebird')
except Exception as error:
print("etl for {} has error".format(config['database']))
print('error message: {}'.format(error))
continue
target_cnx.close()
if __name__ == "__main__":
main()
In your terminal, type python main.py and you’ve just created an ETL using a pure python script.
ETL Tools
There are several Data Warehousing tools on the market. Here are some of the most famous examples:
1. MarkLogic:
MarkLogic is a data warehousing system that uses an array of business capabilities to make data integration easier and faster. It can query many sorts of data, such as documents, relationships, and metadata.
https://www.marklogic.com/product/getting-started/
2. Oracle:
Oracle is the industry’s most popular database. It offers a vast variety of Data Warehouse solutions for both on-premises and cloud services. It helps in better client experiences by boosting operational efficiency.
https://www.oracle.com/index.html
3. Amazon RedShift:
Redshift is a data warehousing solution from Amazon. It’s a simple and cost-effective solution for analyzing various sorts of data with standard SQL and existing business intelligence tools. It also enables the execution of complex queries on petabytes of structured data.
https://aws.amazon.com/redshift/?nc2=h_m1
Conclusion
This article gave you a deep understanding of what ETL is, as well as a step-by-step tutorial on how to set up your ETL in Python. It also gave you a list of the finest tools that most organizations nowadays use to build up their ETL data pipelines.
Most organizations nowadays, on the other hand, have a massive amount of data with a highly dynamic structure. Creating an ETL pipeline from scratch for such data is a hard procedure since organizations will have to use a large number of resources in order to create this pipeline and then ensure that it can keep up with the high data volume and Schema changes.
About The Author
Prashant Sharma
Currently, I Am pursuing my Bachelors of Technology( B.Tech) from Vellore Institute of Technology. I am very enthusiastic about programming and its real applications including software development, machine learning, Deep Learning, and data science.
I hope you like the article. If you want to connect with me then you can connect on:
or for any other doubts, you can send a mail to me also
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!






Can this ETL Tool be used with unstructured data also? Unstructured data like video, audio or image files, as well as log files, sensor or social media posts etc.