This article was published as a part of the Data Science Blogathon
Hey Folks!
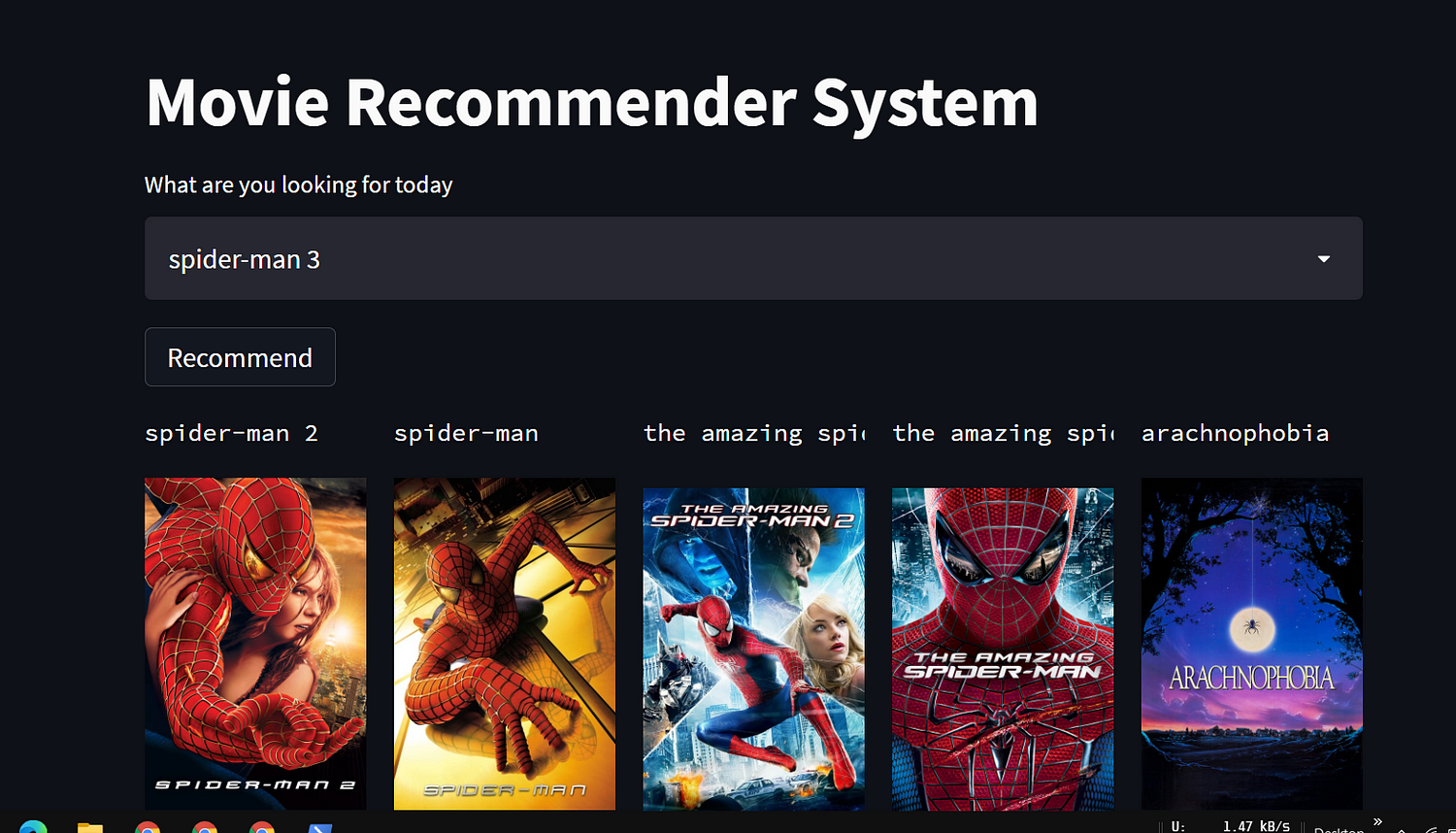
In this article, we are going to start an end-to-end project where we will build a movie Recommender system using Machine learning and host it over the internet as a Movie Recommender website.
Project Difficulty Level : Easy
So if you want to build an End-to-End ML-based project you can follow along with me and I’ll guide you through the project.
What will you learn from this article?
Part1. Building a Movie Recommender System from zero:
In the first part, we will understand the basic concept of the recommender system, and how it works and we will build a Movie Recommender System (Content-based Filtering) from zero.
Part 2. Creating a Website and deploying the model:
In the second part, we will create a website using Streamlit and multiple other services including APIs to get the real-time movie banners and deploy the ML model on the website
Part 3. Deploying our Movie Recommender Website on the internet for Free:
in this part, we will talk about various methods for deployment on the internet using free services with a demonstration
Introduction to Recommender System
Recommender System is basically a system that takes the user’s choice as input and predicts all the related movies, or news, books, etc.
you would have seen Recommender System in Action while Scrolling on Youtube, Netflix, etc.
there are majorly 2 types of Recommender System and the 3rd could be a hybrid of these 2 types
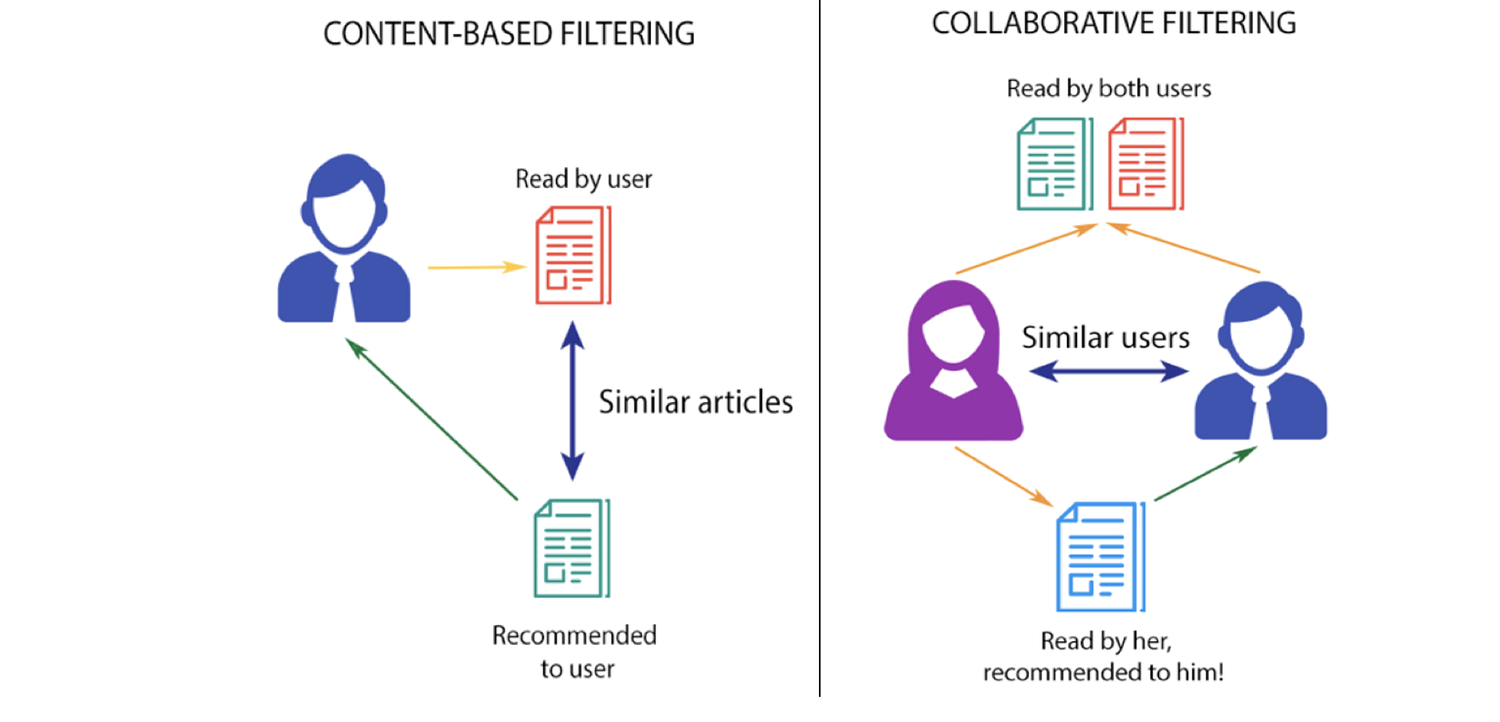
Collaborative filtering
Collaborative filtering basically tries to relate a user with another user who is having the same past behavior (i.e. items purchased or searched by the user) or similar decisions made by other users. once users are related then this model predicts items (or ratings for items) based on other similar users’ interests.
Content-based filtering
This type of Filtering system recommends you on the basis of what you actually like. Imagine you love to watch comedy movies so a content-based recommender system will recommend you other related comedy movies which belong to your category
In the real world, Recommender systems use a hybrid of content-based and collaborative-based filtering. This improves the accuracy of Recommendations
Enough Theory Let’s Start Building our Recommender System!
Steps Involved
Step 1. Getting the Dataset
Step 2. Data Cleaning and Processing
Step 3. Training our Recommender System
Step 4. Testing and Validation
Step 5. Saving the Trained Model for Deployment
Getting the Dataset to create Movie Recommender
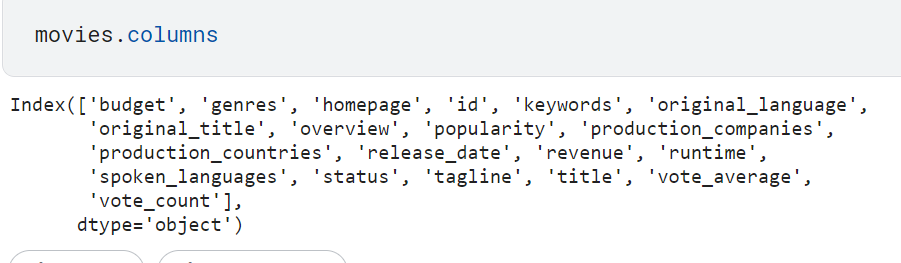
We are going to Use the tmdb-5000 movies dataset for our project. it contains 5000 movies along with their genres, cast, actors, producers, credits, etc.
the dataset contains 2 CSV files one contains movie details, and the second contains the credits of movies(metadata), like the cast, producer, directors, etc.
let’s load the dataset :
import numpy as np
import pandas as pd
movies = pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_movies.csv')
credits = pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_credits.csv')

Merge both data frames on the basis of the movie title name
movies = movies.merge(credits, on = ‘title’)
Data Preprocessing
Feature Selection :
Since we have so many unnecessary columns, so let’s select only those features (columns) which are important for our recommendation.
movies_df = movies[[‘id’, ‘title’,’overview’,’genres’,’cast’,’crew’,’keywords’]]
Removing Null values
in our dataset, we have no duplicates and only some null values so we dropped records having null values
movies_df.dropna(inplace = True)
Data Preprocessing:

genres column is a list of dictionary and key “name” holds the genres. our aim is to convert the list of the dictionary into a list of genres
The same applies with column ‘keywords’
def convert(obj):
import ast # this changes string-list to list
L = []
for i in ast.literal_eval(obj):
L.append(i['name'])
return L
movies_df['genres'] = movies_df.genres.apply(convert)
movies_df['keywords'] = movies_df.keywords.apply(convert)
we have created a function to convert a list of dictionaries into a list of genres and replace them in the genres column

Dealing Movie’s Cast
Cast column contains lists of dictionary of having all cast names. we want to take only the top 4 casts for our recommendations
# now lets deal with cast ( we will only take top 4 casts)
def convert_top4(obj):
counter = 0
import ast # this changes string-list to list
L = []
for i in ast.literal_eval(obj):
if counter != 4:
L.append(i['name'])
counter += 1
else:
break
return L
movies_df['cast'] = movies_df.cast.apply(convert_top4)
crew column contains all the support members including directors, cameramen, stuntmen, etc.
we will only take the director’s name for our prediction.
def fetch_director(obj):
import ast # this changes string-list to list
L = []
for i in ast.literal_eval(obj):
if i['job'] == 'Director':
L.append(i['name'])
return L
movies_df['crew'] = movies_df.crew.apply(fetch_director)
Overview Column:
overview column contains the basic overview of the movie. split the overview into words and remove all the stop words in order to create tags
movies_df['overview'] = movies_df['overview'].apply(lambda x:x.split())
Creating Tags:
now we need to replace all the white spaces with an underscore so that they can be treated as a single entity
movies_df['genres'] = movies_df['genres'].apply(lambda x:[i.replace(" ","_") for i in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x:[i.replace(" ","_") for i in x])
movies_df['cast'] = movies_df['cast'].apply(lambda x:[i.replace(" ","_") for i in x])
movies_df['crew'] = movies_df['crew'].apply(lambda x:[i.replace(" ","_") for i in x])
movies_df['tags'] = movies_df['overview'] + movies_df['genres'] + movies_df['keywords'] + movies_df['cast'] + movies_df['crew']
tags column is a list of lists containing the summary of movie, cast, crew, genres, keywords
movies_df[‘tags’] = movies_df.tags.apply(lambda x:’ ‘.join(x))

we have summarized all our data into the tags column. now we will work only on the tags column
Applying Stemming on Tags:
Stemming is an NLP technique of reducing a word to its root word. For example:
[‘liked’,’ likes’,’ liking’] will be converted into ‘like’Note: before applying stemming convert text into lowercase
import nltk
from nltk.stem.porter import PorterStemmer
ps = PorterStemmer()
def stem(text):
v = ' '.join([ps.stem(i) for i in text.split()])
return v
new_df = movies_df[['id','title','tags']] new_df[‘tags’] = new_df.tags.apply(lambda x:x.lower()) new_df['title'] = new_df.title.apply(lambda x:x.lower())
new_df['tags'].apply(stem)

new_df is our final processed data frame which will be used for training.
Training Steps
our final data frame is textual data, we need to parse it into numerical or floating values in order to feed as inputs in machine learning algorithms. This process is called feature extraction | vectorization).
from sklearn.feature_extraction.text import CountVectorizer cvect = CountVectorizer(max_features = 5000, stop_words = ‘english’) vectors = cvect.fit_transform(new_df[‘tags’]).toarray()
- Count Vectorizer can handle stop_words
max_features = 5000assuming 5000 unique words in our dataset excluding stopwords
Model Building :
our model should be capable of finding the similarity between movies based on their tags.
Our Recommender model takes a movie title as input and predicts top-n most similar movies based on the tags
here we will use the concept of Cosine distance to calculate the similarity of tags
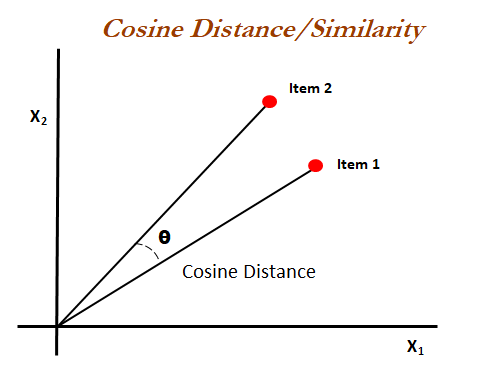
sklearn provides a class for calculating pairwise cosine_similarity.
from sklearn.metrics.pairwise import cosine_similarity similarity = cosine_similarity(vectors)
similarity is a 2D matrix of movies in rows and similarity (confidence) in columns
Testing and Prediction:
Creating a function that takes movie title as input and returns the top-5 most similar movies
def recommend(movie):
movie = movie.lower()
movie_index = new_df[new_df.title == movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)), reverse = True, key = lambda x:x[1])[1:6]
for i in movies_list:
print(new_df.iloc[i[0]].title)
getting prediction:
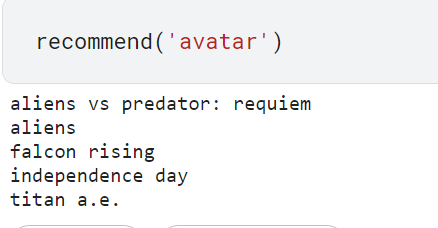
Saving the Model
We need to save the similarity matrix along with the data frame new_df
Using pickle to save model and similarity matrix
import pickle
pickle.dump(new_df, open(‘movies_df.pkl’,’wb’))
pickle.dump(similarity, open('similarity.pkl','wb'))
Conclusion
In this article, you have seen various steps involving data pre-processing, feature extraction of textual data, and using cosine similarity to build our movie recommender system.
In the Next Article, we will create a web app and will use the saved model for prediction. so stay tuned!
If you have something to ask me write me on Linkedin
Source Code: link
A data enthusiast exploring the leading technologies related to the data


