This article was published as a part of the Data Science Blogathon
Introduction
In this article, We will develop an End to End project which will be based on Pure Deep Learning. I’m using Pure term here, the reason you’ll come to know in my further articles. The reason behind building this project is to detect or identify potato leaf diseases, having a variety of illnesses. Because our naked eyes can’t classify them, but Convolutional Neural Network can easily. You won’t believe it when I tell you that the error of some pre-trained Neural Network Architectures is approximately 3%, which is even less than the top 5% error of human vision. On large-scale images, the human top-5 error has been reported to be 5.1%, which is higher than pre-trained networks.
Problem Statement for Potato Leaf Disease Prediction
Farmers who grow potatoes suffer from serious financial standpoint losses each year which cause several diseases that affect potato plants. The diseases Early Blight and Late Blight are the most frequent. Early blight is caused by fungus and late blight is caused by specific micro-organisms and if farmers detect this disease early and apply appropriate treatment then it can save a lot of waste and prevent economical loss. The treatments for early blight and late blight are a little different so it’s important that you accurately identify what kind of disease is there in that potato plant. Behind the scene, we are going to use Convolutional Neural Network – Deep Learning to diagnose plant diseases.
Potato Leaf Disease Prediction Project Description
Here, we’ll develop an end-to-end Deep Learning project in the field of agriculture. We will create a simple Image Classification Model that will categorize Potato Leaf Disease using a simple and classic Convolutional Neural Network Architecture. We’ll start with collecting the data, then model building, and finally, we’ll use Streamlit to build a web-based application and deploy it on Heroku.
Let’s fire🔥
Potato Leaf Disease Prediction Data Collection
Any Data Science project start’s with the process of acquiring the data. First, we need to collect data. We have 3 options for collecting data first we can use readymade data we can either buy it from a third-party vendor or get it from Kaggle etc. The second option is we can have a team of Data Anatator whose job is to collect these images from farmers and annotate those images either healthy potato leaves or having early or late blight diseases. So this team of annotators works with farmers, go to the fields and they can ask farmers to take a photograph of leaves or they can take photographs themselves and they can classify them with the help of experts from agriculture field. So they can manually collect the data. But this process will be time-consuming. The third option is writing a web-scraping script to go through different websites which has potato images and collect those images and use different tools to annotate the data. In this project, I am using readymade data that I got from Kaggle.
Dataset Link: https://www.kaggle.com/abdallahalidev/plantvillage-dataset
Potato Leaf Disease Prediction Data Loading
Our dataset must be in the following format.
Potato Leaf Dataset –> main folder
—-| train
—-| Potato_Healthy
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| Potato_Early_Blight
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| Potato_Late_Blight
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| test
—-| Potato_Healthy
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| Potato_Early_Blight
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| Potato_Late_Blight
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| valid
—-| Potato_Healthy
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| Potato_Early_Blight
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
—-| Potato_Late_Blight
—-| img1.jpg
—-| img2.jpg
—-| img3.jpg
In this project, we are going to use only 900 images to train our model and 300 images for validation. As we all know, training a deep learning model requires a lot of data. To overcome this problem we will use one of the simple and effective methods, called Data Augmentation. Let’s first see what is data augmentation.
Data Augmentation: Data Augmentation is a process that generates several realistic variants of each training sample, to artificially expand the size of the training dataset. This aids in the reduction of overfitting. In data augmentation, we will slightly shift, rotate, and resize each image in the training set by different percentages, and then add all of the resulting photos to the training set. This allows the model to be more forgiving of changes in the object’s orientation, position, and size in the image. The contrast and lighting settings of the photographs can be changed. The images can be flipped horizontally and vertically. We may expand the size of our training set by merging all of the modifications.
Let’s begin the coding section
Installing the necessary libraries.
import numpy as np import matplotlib.pyplot as plt import glob import cv2 import os import matplotlib.image as mpimg import random from sklearn import preprocessing import tensorflow.keras as keras import tensorflow as tf from keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.utils import to_categorical
Let’s now add some static variables to aid us in our progress.
SIZE = 256 SEED_TRAINING = 121 SEED_TESTING = 197 SEED_VALIDATION = 164 CHANNELS = 3 n_classes = 3 EPOCHS = 50 BATCH_SIZE = 16 input_shape = (SIZE, SIZE, CHANNELS)
To begin, we must first establish the setup for augmentation that we will use on our training dataset.
train_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 30,
shear_range = 0.2,
zoom_range = 0.2,
width_shift_range=0.05,
height_shift_range=0.05,
horizontal_flip = True,
fill_mode = 'nearest')
Here is one thing we need to care that, on validation and test dataset we will not use the same augmentation that we have used on the training dataset, because the validation and testing dataset will only test the performance of our model, and based on it, our model parameters or weights will get tunned. Our objective is to create a generalized and robust model, which we can achieve by training our model on a very large amount of dataset. That’s why here we are only applying data augmentation on the training dataset and artificially increasing the size of the training dataset.
validation_datagen = ImageDataGenerator(rescale=1./255) test_datagen = ImageDataGenerator(rescale = 1./255)
Let’s now load the training, testing, and validation datasets from the directory and perform data augmentation on them.
Note that our data must be in the above-mentioned format. Otherwise, we might be able to get an error or our model’s performance may suffer. It will load our dataset from the directory first, then resize all of the images to the same dimension, make batches, and then choose RGB as the color mode.
train_generator = train_datagen.flow_from_directory(
directory = '/content/Potato/Train/', # this is the input directory
target_size = (256, 256), # all images will be resized to 64x64
batch_size = BATCH_SIZE,
class_mode = 'categorical',
color_mode="rgb")
validation_generator = validation_datagen.flow_from_directory(
'/content/Potato/Valid/',
target_size = (256, 256),
batch_size = BATCH_SIZE,
class_mode='categorical',
color_mode="rgb")
test_generator = test_datagen.flow_from_directory(
'/content/Potato/Test/',
target_size = (256, 256),
batch_size = BATCH_SIZE,
class_mode = 'categorical',
color_mode = "rgb"
)
Let’s build a simple and classical Convolutional Neural Network Architecture now.
Our dataset is preprocessed and now we are ready to build our model. We are going to use a Convolutional Neural Network which is one of the famous types of Neural Network Architecture if you are solving Image Classification Problems. Here we are creating simple and classical Neural Network Architecture. Here we are using Keras Sequential API to create our model architecture, it only contains a stack of convolutional and pooling layers. There is approx n number of layers and then at the end, there is a dense layer where we just flatten our feature maps. In the end, we are using a dense layer with a softmax activation function, which will return the likelihood of each class.
model = keras.models.Sequential([
keras.layers.Conv2D(32, (3,3), activation = 'relu', input_shape = input_shape),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Dropout(0.5),
keras.layers.Conv2D(64, (3,3), activation = 'relu', padding = 'same'),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Dropout(0.5),
keras.layers.Conv2D(64, (3,3), activation = 'relu', padding = 'same'),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Conv2D(64, (3,3), activation = 'relu', padding = 'same'),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Conv2D(64, (3,3), activation = 'relu', padding = 'same'),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Conv2D(64, (3,3), activation = 'relu', padding = 'same'),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Flatten(),
keras.layers.Dense(32, activation ='relu'),
keras.layers.Dense(n_classes, activation='softmax')
])
I hope you are familiar that how the convolutional and Max pooling is working behind the scene. This architecture is hit & trial, you can try your architectures. You can experiment with different architecture by removing a few layers, adding more layers, and using dropouts. Now our model architecture is ready.
The next step is to investigate model architecture.
Let’s have a look at the brief summary of our model. We have a total of 185,667 trainable parameters. These are the weights we’ll be working with.
model.summary()
#-----------------------------Output-----------------------------
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 254, 254, 32) 896
max_pooling2d (MaxPooling2D (None, 127, 127, 32) 0
)
dropout (Dropout) (None, 127, 127, 32) 0
conv2d_1 (Conv2D) (None, 127, 127, 64) 18496
max_pooling2d_1 (MaxPooling (None, 63, 63, 64) 0
2D)
dropout_1 (Dropout) (None, 63, 63, 64) 0
conv2d_2 (Conv2D) (None, 63, 63, 64) 36928
max_pooling2d_2 (MaxPooling (None, 31, 31, 64) 0
2D)
conv2d_3 (Conv2D) (None, 31, 31, 64) 36928
max_pooling2d_3 (MaxPooling (None, 15, 15, 64) 0
2D)
conv2d_4 (Conv2D) (None, 15, 15, 64) 36928
max_pooling2d_4 (MaxPooling (None, 7, 7, 64) 0
2D)
conv2d_5 (Conv2D) (None, 7, 7, 64) 36928
max_pooling2d_5 (MaxPooling (None, 3, 3, 64) 0
2D)
flatten (Flatten) (None, 576) 0
dense (Dense) (None, 32) 18464
dense_1 (Dense) (None, 3) 99
=================================================================
Total params: 185,667
Trainable params: 185,667
Non-trainable params: 0
_________________________________________________________________
Compile the Potato Leaf Disease Prediction model
model.compile(
optimizer = 'adam',
loss = tf.keras.losses.CategoricalCrossentropy(),
metrics = ['accuracy']
)
We’re using Adam Optimizer, which is one of the most common optimizers, but you can also check out other optimizers. We’re using categorical cross-entropy in the loss because we’re dealing with a Multi-Class Classification problem. We’re using accuracy measures to track our model’s training performance
Train the network
history = model.fit_generator(
train_generator,
steps_per_epoch = train_generator.n // train_generator.batch_size, #The 2 slashes division return rounded integer
epochs = EPOCHS,
validation_data = validation_generator,
validation_steps = validation_generator.n // validation_generator.batch_size
)
In the history parameter, we’re recording the history of each epoch so that we can create some charts to compare our model’s performance on the training and validation sets.
Let’s see how well the model performs on the test data.
Let’s test our model on the test dataset. Before putting our model into production, we must first test it on a test dataset to see how it performs.
score = model.evaluate_generator(test_generator)
print(‘Test loss : ‘, score[0])
print(‘Test accuracy : ‘, score[1])
————–OUTPUT—————–
Test Loss : 0.10339429974555969
Test Accuracy : 0.9733333587646484
On the test set, we have a 97% accuracy rate, which is rather good. Let’s start with some performance graphs.
Let’s have a look at the history parameter.
Actually, history is a Keras callback that keeps all epoch history as a list; let’s utilize it to plot some intriguing plots. Let’s start by putting all of these parameters into variables.
acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(range(EPOCHS), acc, label='Training Accuracy')
plt.plot(range(EPOCHS), val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(range(EPOCHS), loss, label='Training Loss')
plt.plot(range(EPOCHS), val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
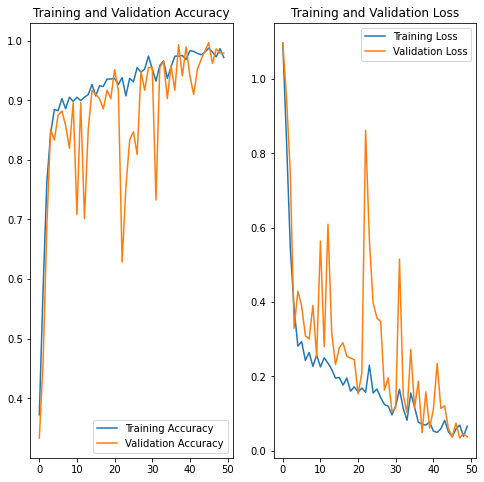
This graph shows the accuracy of training vs validation. Epochs are on the x-axis, and accuracy and loss are on the y-axis.
Let's save our model
# it will save the model
model.save('final_model.h5')
Our model will be saved in HDF5 format since we need to save all learned parameters in deep learning, which might take up a lot of space, and HDF5 can easily hold a lot of data.
Streamlit – The Boom!
If you wanted to build a Machine Learning web application in the past, you had to use flask, Django, or hire a full stack developer, but when streamlit came along, it changed the entire ecosystem, allowing anyone to build a Machine Learning web application, Data Science web application, Data Science dashboard, or Data Analytics dashboard. Streamlit is a python library and a startup that allows you to construct web applications for free. It also offers Streamlit Cloud Services, where we can deploy our apps at different prices.
Streamlit is a free, open-source Python Framework, that allows us to quickly develop a Web Application without the requirement of a backend server and without having to write HTML, CSS, or Javascript. We can start building a really good Web Application simply by using our existing python skills. I’ve created a simple web application that accepts images as input and requires the same preprocessing steps on the input image as we did on our training dataset during training because when we save our model, it only saves model trained parameters, and we must preprocess our input manually, so this is something we must keep in mind when building any web application or using a pre-trained model.
Web App
# For potato leaf disease prediction
import streamlit as st
from PIL import Image
import numpy as np
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import tensorflow_hub as hub
hide_streamlit_style = """
#MainMenu {visibility: hidden;}
footer {visibility: hidden;}
"""
st.markdown(hide_streamlit_style, unsafe_allow_html = True)
st.title('Potato Leaf Disease Prediction')
def main() :
file_uploaded = st.file_uploader('Choose an image...', type = 'jpg')
if file_uploaded is not None :
image = Image.open(file_uploaded)
st.write("Uploaded Image.")
figure = plt.figure()
plt.imshow(image)
plt.axis('off')
st.pyplot(figure)
result, confidence = predict_class(image)
st.write('Prediction : {}'.format(result))
st.write('Confidence : {}%'.format(confidence))
def predict_class(image) :
with st.spinner('Loading Model...'):
classifier_model = keras.models.load_model(r'final_model.h5', compile = False)
shape = ((256,256,3))
model = keras.Sequential([hub.KerasLayer(classifier_model, input_shape = shape)]) # ye bhi kaam kar raha he
test_image = image.resize((256, 256))
test_image = keras.preprocessing.image.img_to_array(test_image)
test_image /= 255.0
test_image = np.expand_dims(test_image, axis = 0)
class_name = ['Potato__Early_blight', 'Potato__Late_blight', 'Potato__healthy']
prediction = model.predict(test_image)
confidence = round(100 * (np.max(prediction[0])), 2)
final_pred = class_name[np.argmax(prediction)]
return final_pred, confidence
footer = """
a:link , a:visited{
color: white;
background-color: transparent;
text-decoration: None;
}
a:hover, a:active {
color: red;
background-color: transparent;
text-decoration: None;
}
.footer {
position: fixed;
left: 0;
bottom: 0;
width: 100%;
background-color: transparent;
color: black;
text-align: center;
}
“”” st.markdown(footer, unsafe_allow_html = True) if __name__ == ‘__main__’ : main()
Output :
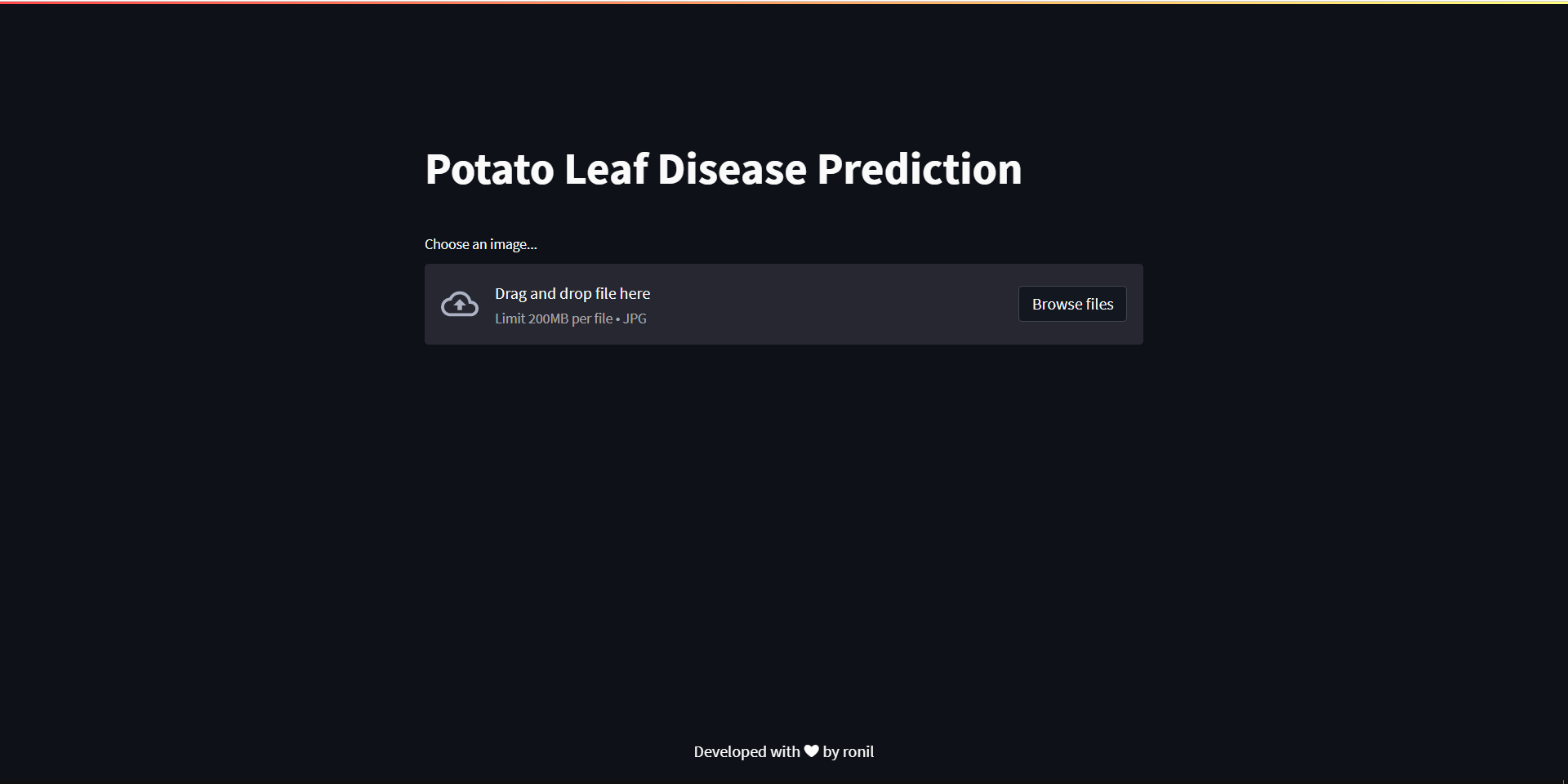
Internally, the web app uses our previously developed deep learning model to detect potato leaf diseases. Let’s go on to the next phase now that you have a better understanding of what’s going on. I’m going to launch it to Heroku, so you’ll need to sign up for Heroku first, then follow the procedures below.
1. Make a GitHub repository and add your model, web application python file, and model building source code to it.
2. Once you’ve completed that, create a requirement.txt file in which you’ll list any libraries, packages, or modules that you’ll be utilizing in this project.
3. Create a Procfile, fill it with the code below, and save it to your project’s GitHub repository.
web: sh setup.sh && streamlit run your_webapp_name.py
4. Create a setup.sh file and paste the code below into it.
mkdir -p ~/.streamlit/ echo " [general]n email = "mention_your_mailid_here"n " > ~/.streamlit/credentials.toml echo " [server]n headless = truen enableCORS=falsen port = $PORTn " > ~/.streamlit/config.toml
5. After you’ve completed all of the procedures, go to Heroku and build a new app, then select Connect to GitHub.
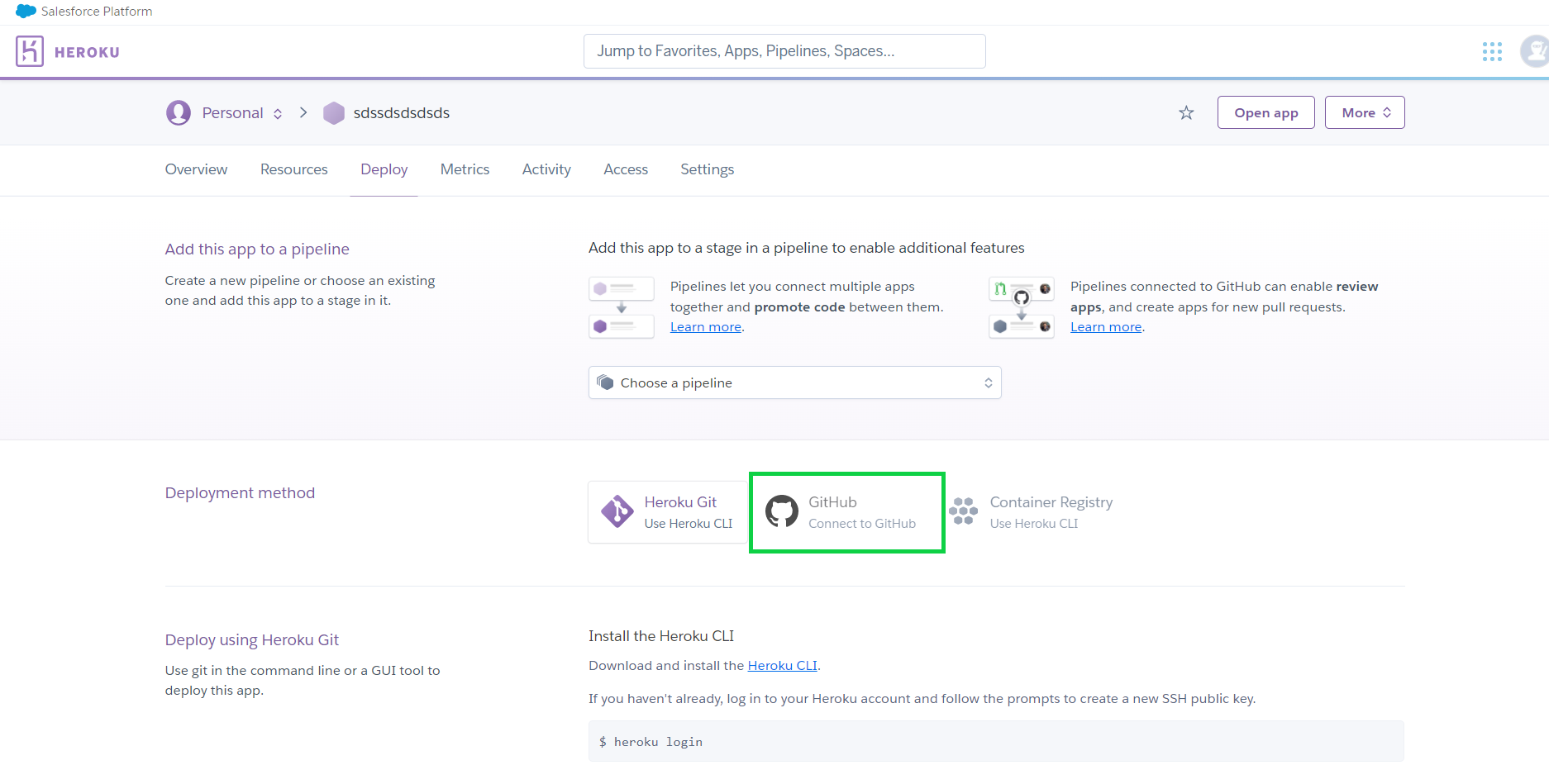
Then choose your project repository from the list of GitHub repositories and click connect.
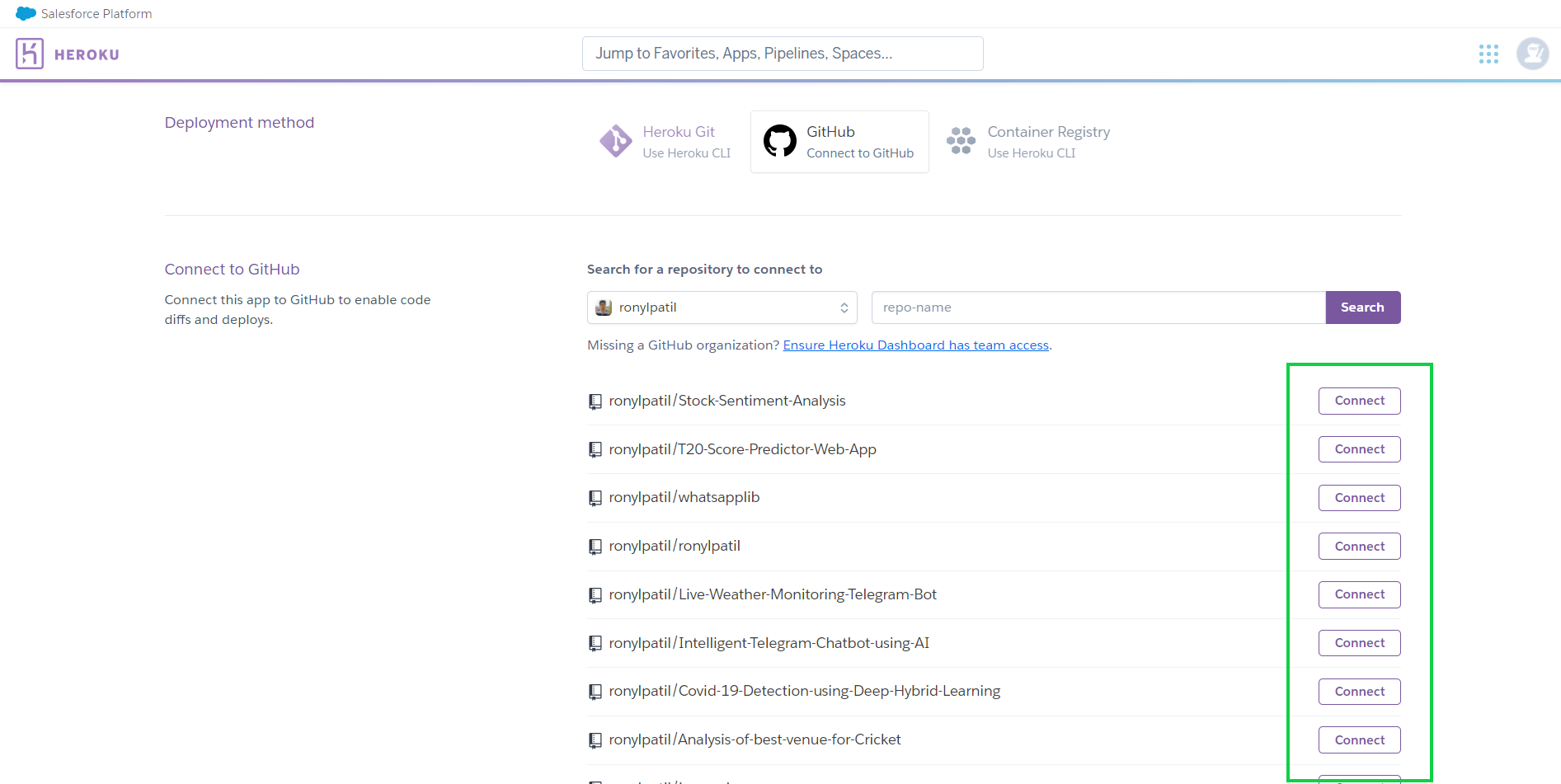
When you click Connect, a new window will appear, and you have to click on Deploy Branch.
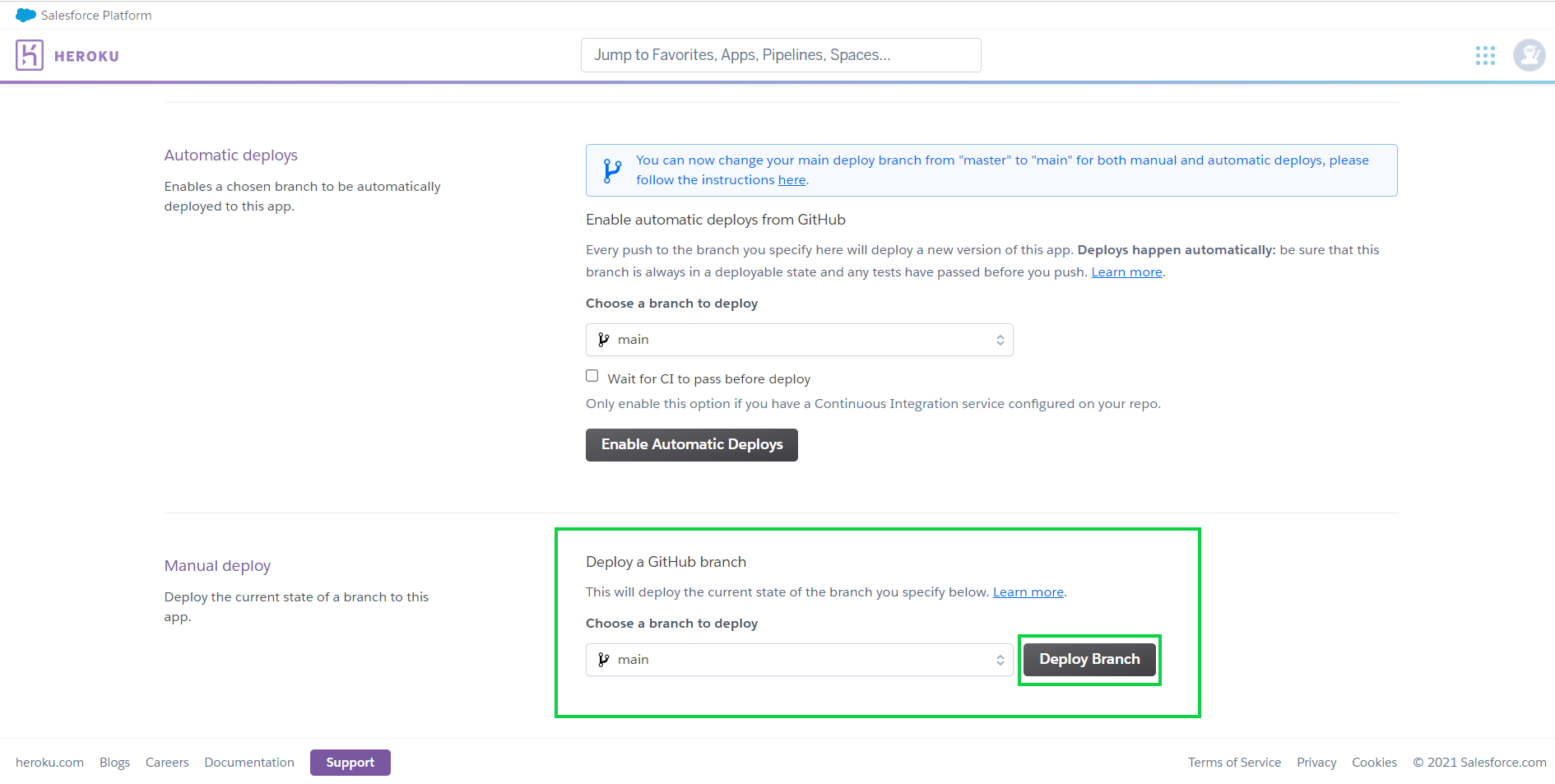
If you run into any problems during deployment, go to my GitHub repository and utilize the same file format that I did. To see my GitHub repository, go here.
If you loved it and learned something new, don’t forget to share it with your friends. If you have any questions, please don’t hesitate to ask them in the comments section below, and I will try my best to answer them. You may connect with me on LinkedIn and also follow me on GitHub, where I post interesting Machine Learning and Deep Learning projects regularly. Last but not least, It doesn’t go without saying…
Stay Classy & Thanks for reading!






What are the challenges u faced and did u overcome them.