This article was published as a part of the Data Science Blogathon
Hello Siri!, what the time.
This sound will sound familiar to most of us as we practically use mobile phones 24*7. I don’t really remember the last time I typed any query on the google search engine I just simply ask Google to do that for me. It just saves a ton of time and also I am lazy to type that long so google does that for me it’s like a win-win situation!
Let’s see a scenario where speech recognition is used. The overwhelming responses getting from people for speech-enabled products is crazy like from Amazon Alexa, Apple Siri, and even Fridges has the speech-enabled products that can play valuable support in household tech in the present and also in the near future. Even speech recognition allows physically disabled people, visually impaired or small children to interact with them and the main benefit it doesn’t require any GUI.
Okay so let’s check the amount of speech recognition we used in our day-to-day activity.
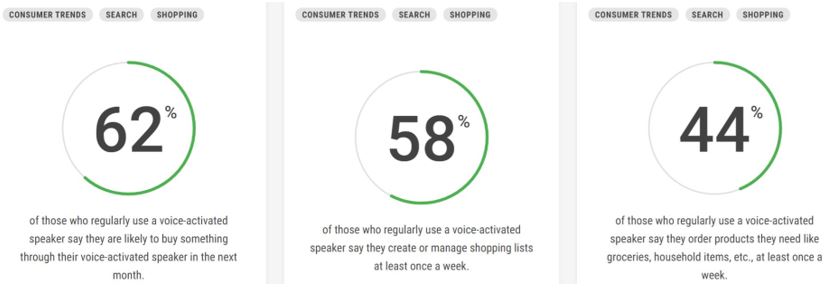
Image Source: Google
Seeing the speech recognition system, everywhere why not make one for our own. Did you know that you can vault past 1,000 words per day by using speech-to-text software? There are numerous open-source API’s that have been published by the top tech giants Google, Facebook. These companies have trained their model on various data in all the possible scenarios to give an accurate response.
Table of contents
How speech recognition works?
Before going deep dive into speech recognition let’s understand how it works. If you directly want to go into the code feel free to skip this part but it is good to understand the history.
Well, speech recognition was found in the early 1950s in the bell labs. Did you know that these systems go way back to the 1950s? Well, yes it’s quite surprising. Let’s look at the picture of the evolution of Speech Recognition systems over the decades:

Image Credits: Clark Boyd
If we look back at history systems were limited to single speakers and had limited vocabs but as technological advancements came into the picture. Now, the modern speech recognition system has the vocabulary for a plethora of languages.
I know it will be boring if I give information about the evolution of speech recognition so I will warp it up in short. Speech recognition basic step is to convert speech to an electrical signal with a microphone and then convert it to digital data. Once the digitalization process is completed several models can be used to transcript the audio data to text data.
The modern speech recognition systems Alexa, Siri rely on Hidden Markov Model (HMM) approach. This approach works on the assumption that a speech signal when viewed on a brief enough timescale (say, ten milliseconds), is often reasonably approximated as a stationary process—that is, a process in which statistical properties do not change over time.
Fortunately, as a Python programmer, you don’t have to worry unnecessarily about the whole process. Numerous speech recognition services are available for online users through an API, and many of these services also offer Python SDKs.
Wouldn’t it be interesting if we can work on this uses cases using Machine Learning skills? So let’s see how it is done.
Different Speech Recognition Packages
There are many packages available for speech recognition exist on PyPI. A few of them include:
- SpeechRecognition
- watson-developer-cloud
- google-cloud-speech
- apiai
- assemblyai
- pocketsphinx
- wit
- CMU Sphnix
The most common and best package which helps in the speech recognition process is SpeechRecognition.
Some of the packages like wit and apiai offer an additional functionality natural language processing NLP for identifying the intent of the speaker which goes way beyond speech recognition.
CMU Sphix tools are specially designed for low-resource platforms which focus mainly on practical application development and not on the research side. Others packages, like google-cloud-speech, mainly focus on speech-to-text conversion.
The audio input is given for the process of Speech Recognition; here in SpeechRecognition you don’t have to build or create scripts from scratch for accessing the microphones and processing the audio files; SpeechRecognition will do it for you in a few minutes.
Implementation of speech recognition with SpeechRecognition package
Installing
Installing the SpeechRecognition
Installation of the SpeechRecognition library with pip, run the following command
!pip install SpeechRecognitionInstalling PyAudio
PyAudio will allow microphone access from the laptop or computer or any device.
Installation of the PyAudio library with pip, run the following command
!pip install pyaudioAfter installing let’s check which version of SpeechRecognition is it
import speech_recognition as sr
print(sr.__version__)
'3.8.1'Recognizer Class
For APIs, the SpeechRecognition library acts as a wrapper and it is extremely flexible and compatible. The SpeechRecognition library has several libraries but we will only be focusing on the Recognizer class. The Recognizer class will help us to convert the audio data into text files. So, now let’s try out the SpeechRecognition library, and the next step is simple we just need to install it in your environment.
let the magic start with Recognizer class in the SpeechRecognition library. The main purpose of a Recognizer class is of course to recognize speech. Creating an Recognizer instance is easy we just need to type:
recognizer = sr.Recognizer()
After completing the installation process let’s set the energy threshold value. You can view the energy threshold value as the loudness of the audio files the ideal energy threshold value is 300. The documentation of SpeechRecognition recommended 300 values as a threshold and it works best with various audio files.
Using the energy threshold will improve the recognition of speech while working with audio data. If the values are higher than the energy threshold = 300 then are considered as speech but if the values are lower then they are considered as silent.
recognizer.energy_threshold = 300Speech Recognition Functions
For recognizing speech from audio data using different APIs there is a recognizer class that does all the work.
recognize_houndify(): Houndify by SoundHoundrecognize_ibm(): IBM Speech to Textrecognize_sphinx(): CMU Sphinx – requires installing PocketSphinxrecognize_google(): Google Web Speech APIrecognize_google_cloud(): Google Cloud Speech – requires installation of the google-cloud-speech package
The recognize_sphinx() has benefits as it can work offline with the CMU Sphinx engine. The other requires a stable internet connection.
Google offers it is own API recognize_google() which is free and it also does not require any API key for use. Well, there is one drawback about google speech recognition that is limiting you went you try to process the audio data which have a longer time period.
Audio Preprocessing
While passing the audio data if you get an error it is due to the wrong data type format for the audio file. To avoid this kind of situation preprocessing of audio data is a must there is a class especially for preprocessing the audio file which is called AudioFile.
For this example, you can download any audio file. But if you want to use your own voice for the audio files you just need to run the below code.
import speech_recognition as sr
# obtain audio from the microphone
r = sr.Recognizer()
with sr.Microphone() as source:
print("Say something!")
audio = r.listen(source)
# write audio to a WAV file
with open("microphone-results.wav", "wb") as f:
f.write(audio.get_wav_data())
Now you can download your own data in the audio format or if you don’t want to do this you can just download any audio file from the web.
Audio processing code
import speech_recognition as sr
recognizer = sr.Recognizer()
audio_file_ = sr.AudioFile("audio_demo.wav")
type(audio_file)
If you see right now the file is an audio file and not audio data. So to convert it to an audio data type there is a recognizer class called a record.
Record
So, let’s convert it into audio to audio data with the help of a record.
with audio_file as source:
audio_file = recognizer.record(source)
recognizer.recognize_google(audio_data=audio_file)
type(audio_file)
The recording method has 2 parameters duration and offsets that we can use.
The definition for:
Duration: Duration is used when you want specific audio from the audio data to let’s say you want only the first 5 seconds of the entire audio data, so now we have to set the duration parameter to 0.5.
with audio_file_ as source:
audio_file = recognizer.record(source, duration = 5.0)
result = recognizer.recognize_google(audio_data=audio_file)
result
# Output
'have a nice day'
Offset: Offset is mainly used when we need to cut off some seconds at the starting of the audio data. Let’s see if you don’t want to listen or need the first 5 seconds of the audio then you have to set the offset parameter to 5
with audio_file_ as source:
audio_file = recognizer.record(source, offset = 1.0)
result = recognizer.recognize_google(audio_data=audio_file)
result
# Output
'now get ready for the exam'
Here we have clear sound from the audio data so there is no need of pre-processing the data but there are some cases when we don’t have audio that has clear sound or some noise interference is there. At that time what to do let’s find out.
The Effect of Noise on Speech Recognition
We won’t get noise-free data every time. All audio files have some degree of noise in them from the start and this un-handled noise will affect the accuracy of the Speech Recognition system.
Let’s see an example where we will see how a noise audio file affects the accuracy of the Speech Recognition system. You can download the audio file “jackhammer.wav” file here. Don’t forget to download the audio file into your current working directory.
First, let’s run the code and see what output is seen
recognizer = sr.Recognizer()
jackhammer = sr.AudioFile('audio_files_jackhammer.wav')
with jackhammer as source:
audio = recognizer.record(source)
recognizer.recognize_google(audio)
# Outout
snail smell of oil gear vendors
Ohh hell no this won’t work but we have the solution we can use the adjust_for_ambient_noise method of the Recognizer class. Let’s re-run it.
with jackhammer as source:
recognizer.adjust_for_ambient_noise(source, duration=0.5)
audio = recognizer.record(source)
recognizer.recognize_google(audio)
# Output
still smell of old beer vendors
adjust_for_ambient_noise methods work for this audio and we got a closer output but it is not correct for cases like this we need to pre-process the audio file which can be done with audio editing software or a Python package (such as SciPy).
If you don’t want to use the audio file you can also use your voice and the speech_recognition will write down what you speak.
The code for the voice coming through the microphone for that we will use pyaudio library.
#import library
import speech_recognition as sr
# Initialize recognizer class (for recognizing the speech)
recognizer = sr.Recognizer()
# Reading Microphone as source
# listening the speech and store in audio_text variable
with sr.Microphone() as source:
print("Start Talking")
audio_text = recognizer.listen(source)
print("Time over, thank you")
try:
# using google speech recognition
print("Text: "+recognizer.recognize_google(audio_text))
except:
print("Sorry, I did not get that")
Top 5 open source projects for speech-to-text recognition
1. DeepSpeech

Image Source: Mycroft AI
One of the best open-source speech-to-text recognition is Deepspeech it can run in real-time using a pre-trained machine learning model which is based on Baidu’s Deep Speech research paper and is implemented using Tensorflow.
It also has the highest ratings on GitHub with 18.6k stars.
The most amazing feature of DeepSpeech is it can run on real-time devices like GPU Servers, Rasberry Pi4. DeepSpeech also supports various platforms for its development such as Windows, macOS, Linux, and Andriod.
Look at the official documentation here
2. SpeechRecognition

Image Source: SpeechRecognition
For performing Speech Recognition, there is SpeechRecognition library which is open source and the best thing is that several engines and APIs provide in both modes online and offline mode. For Speech Recognition is in python.
SpeechRecognition is used highest among the audience and it has many examples. Audio files provided in SpeechRecognition can be in AfIFF-C, AIFF, WAV format, commonly wav format is widely used.
It has ratings on GitHub of 6K stars and for more information look at the documentation here
3. Leon

Image Source: Leon
Leon is also an open-source personal assistant who can live on your server and perform the task when you ask him to perform. Well, you can think of him as the second brain and you can talk to him and he can talk to you.
For privacy matters, Leon is more helpful as you can configure Leon to talk to him offline, and then you can interact with Leon without any third-party service.
It has ratings on GitHub of 8.1k stars.
It can do many things try browsing the packages list and you can then configure Leon on your requirement basis. Leon is mainly built using Python and Node.js and supports Windows, macOS, and Linux.
Look at the official documentation here
4. Wav2letter

Image Source: Wav2letter
Wav2letter++ is made by Facebook AI Reseatchs’s which is end-to-end automatic speech recognition. Wav2letter++ is mainly compared to DeepSpech due to its similarities.
It has ratings on GitHub of 5.9k stars.
Wav2letter++ is entirely written in c++ and it also supports a wide range of models and some learning techniques. wav2letter has been moved and consolidated into Flashlight in the ASR application but if you want to use the old release it is still available.
Look at the official documentation here
5. Annyang
Image Source: Annyang
The Annyang is a javascript speech recognition library that is, of course, open-source and it lets users control the site with your voice commands. Isn’t that amazing! Annyang also supports more than 75 languages that are free to use and can modify easily.
It has ratings on GitHub of 6.2K stars.
One of the amazing features is we can easily add a Graphical User Interface (GUI) and also provide numerous themes with a fully customizable facility. Well, additionally it also gives instruction on how to create your own design.
Look at the official documentation here
Conclusion
After reading this blog you will get the knowledge of what is Speech Recognition and where Speech Recognition is used like Siri, Google, and many more. We also got to know about how it works. Additionally what is the open sources available where you configure according to our need and can make your own Speech Recognition system. And also got to know about the top 5 open sources Speech Recognition which have got the highest rating in Github. Well, there are some paid Speech Recognition APIs that are also available which can ease the process too but that comes at the cost of the pocket.
References:
Open sources speech recognition: here
SpeechRecognition with Python: here
Image References:
- Usage of Speech Recognition: Google
- Evolution of Speech Recognition: Clark Boyd
- DeepSpeech: The image is taken from DeepSpeech
- SpeechRecognition: The image is taken from SpeechRecognition
- Leon: The image is taken from Leon
- Wav2letter++: The image is taken from Wav2letter++
- Annyang: The image is taken from Annyang
About the Author,
you can contact me on any medium.
LinkedIn | Kaggle | Medium | Analytics Vidhya
A student who is learning and sharing with a storyteller to make your life easy.




This end-end guide to speech recognition in Python is very informative and helpful for anyone looking to integrate speech recognition into their projects. It provides an overview of the various libraries available, including the popular SpeechRecognition library, and explains how to use them effectively. The step-by-step instructions make it easy for beginners to get started with speech recognition in Python, while more advanced users will appreciate the detailed explanations of the different techniques and options available. Overall, this guide