Table of Contents
- What is Data Engineering?
- Components of Data Engineering
- Object Storage
- Object Storage MinIO
- Install Object Storage MinIO
- Data Lake with Buckets
- Demo Data Lake Management
- Conclusion
- References
What is Data Engineering?
Initially, we have the definition of Software Engineering, as the branch of engineering capable of specifying, developing, executing, and maintaining programs, systems, and applications. That solves corporate business problems, helping companies to increase their competitiveness.
Within Software Engineering we have several specializations, such as social networks, ERP, Project Management, Mobile Apps, Networking Management, and Data Science, among others. We can understand Data Engineering as a subset of Data Science, which receives data from Big Data and prepares them to be used in a Machine Learning Model.
Data Engineering
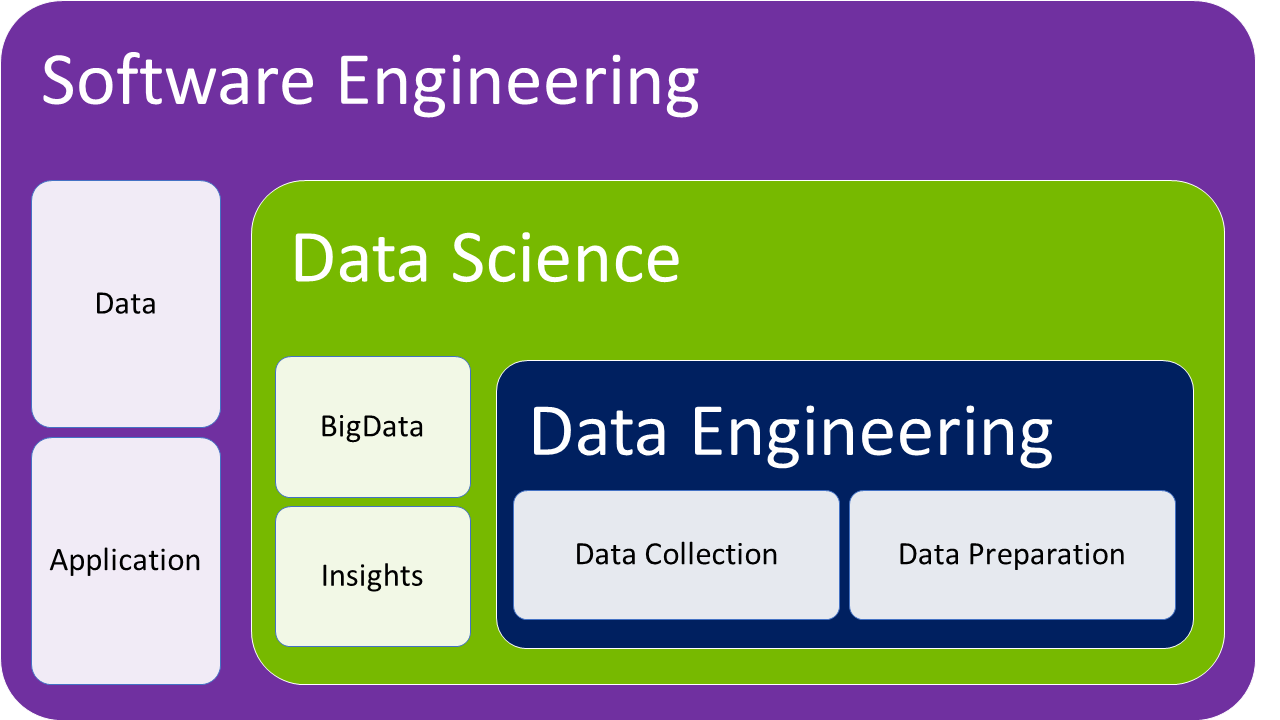
Image Source: GitHub
Data Engineering Components

Image Source:GitHub
Data Engineering is formed by a wide range of software, which is executed from a flow, created by the Data Scientist.
- Data Discovery
- Observability
- Governance
- MLOps
- Workflow
- Notebooks
- Formats
- Data Lifecycle
- Virtualization
- Compute
- Object Storage
- Meta stores
- Orchestration
- Analytics Engine
- Ingest – Data
- Ingest – Application
In this article, we will implement Data Engineering, applying an Object Storage component, with data storage functionalities after extracting an external Big Data, later after data manipulation and processing, the data is stored in this Object component. Storage is already in a structured form to be consumed by a Machine Learning model.
Components of Data Engineering
Data Engineering can be classified by several components, which can be executed in isolation, or integrated into a data flow pipeline. These components can be run on cloud infrastructure or on-premises servers.
For the identification of new data, we have the Data Discovery component, for the capture and processing of logs we have the Observability component, for data management we have the governance components.
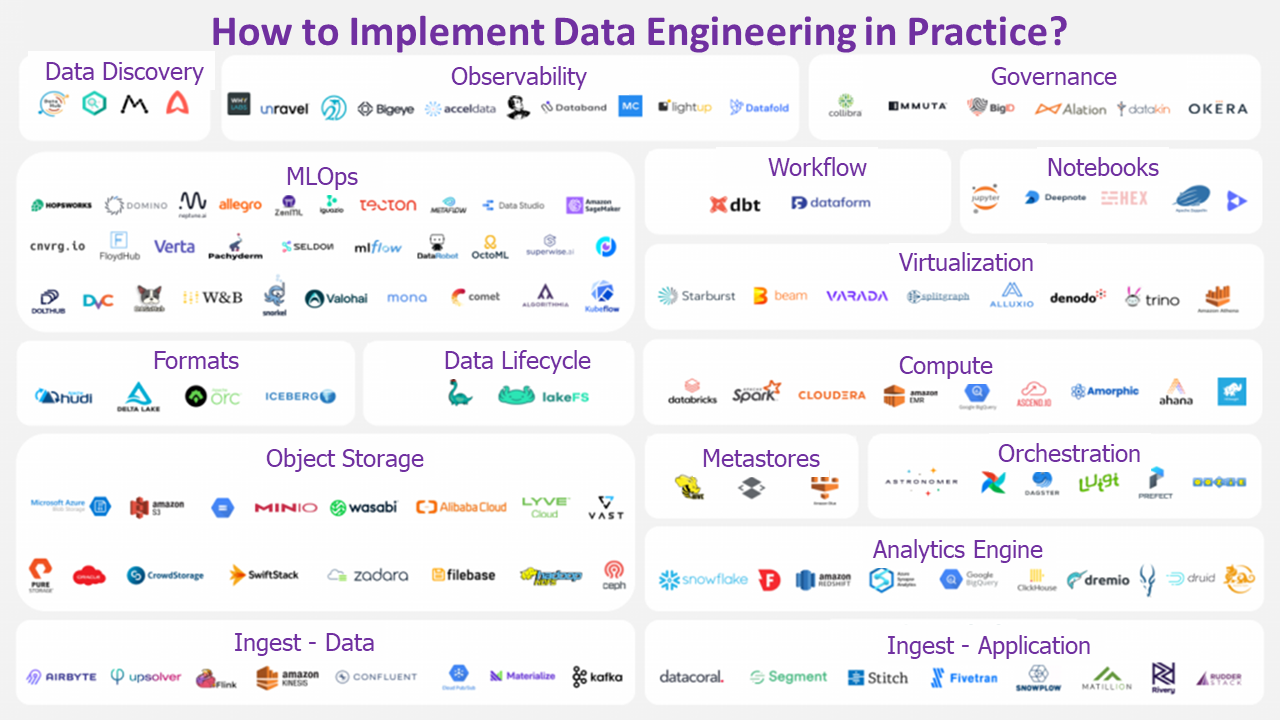
Image Source: GitHub
We can understand MLOps as an extension of DevOps applied to Data Science applications, where we can visualize two flow layers, the first the Data layer and the second the Machine Learning layer.
In the Data Layer, the Data Scientist executes the deployment process, through a continuous and cyclic pipeline, which starts with the Data Collection, which can be understood by the Classic ETL Extraction process. Then, we have the Data Ingestion job, which loads the data and indexes the pipeline, the Data Analysis job curates and selects the data, Data Labeling adds a tag to the data, to facilitate the future classification process, the job Data Validation checks the usability of the data, to finally be prepared for the Machine Learning layer.
In the figure below, we can see the flow of the Machine Learning layer, which receives the data prepared from the previous layer and starts the machine learning training. In the validation of the machine learning model, the model with the highest performance is adopted for use in the dataset. In Machine Learning validation, the validation is done with test data, after this last verification the Machine Learning model is exported to a cloud infrastructure, such as Google Cloud Platform, Microsoft Azure Machine Learning, or AWS Machine Learning Sage Marker.

Image Source: GitHub
As a result of MLOps, after executing the Data layer and Machine Learning layer flows, the Data Scientist offers the user, business specialist, a customizable dashboard, with the insights and predictions generated by the MLOps architecture.
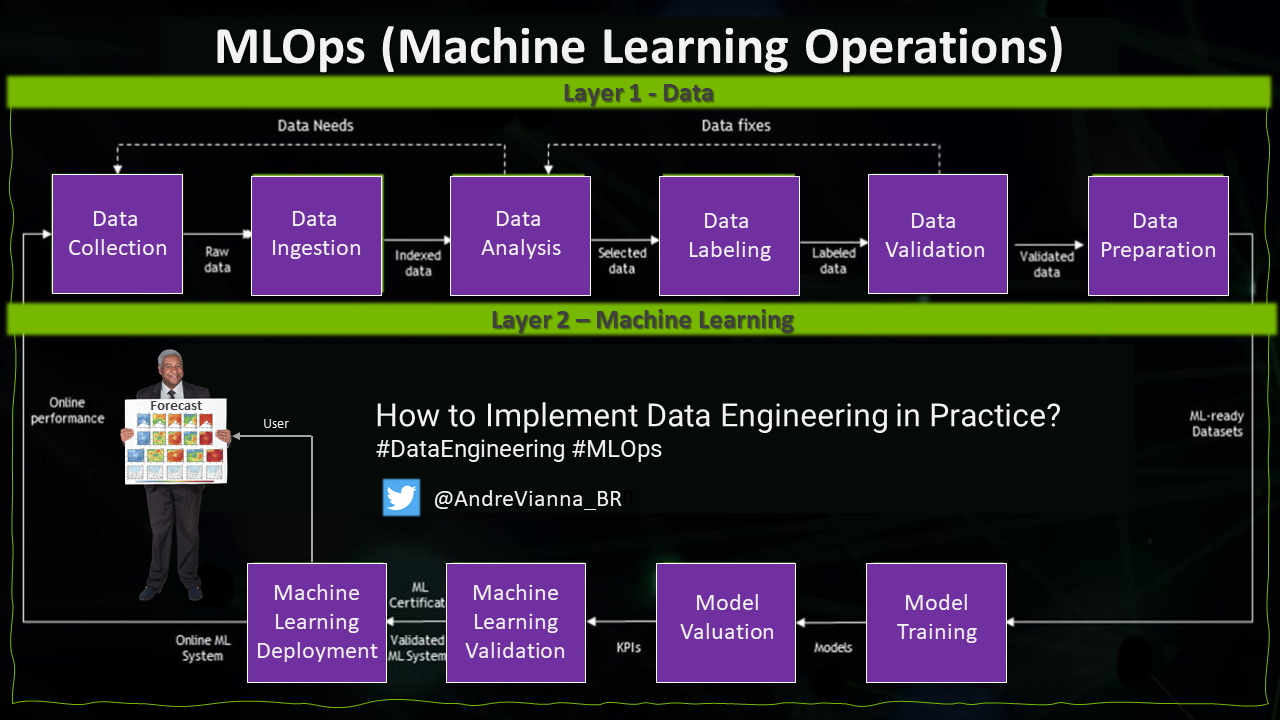
Image Source: GitHub
Object Storage in Data Engineering
Object Storage is a fundamental component in Data Engineering, with unlimited data storage capacity, guaranteed to Big Data, flexible and highly scalable data storage.
Currently, we have AWS S3 as the main Object Storage available in the Cloud, having a large number of companies, which host data from various applications.
We have services with equivalent functionality in Oracle Cloud, Google Cloud Platform, Microsoft Azure, and IBM Cloud.
In this article, we will detail the open-source Minio software, which can be run on an on-premise server, or a virtual cloud server like AWS EC2.
Below we have the main features of the object storage software:
- Directed to Big Data
- Complete Data Lifecycle
- Data Durability
- Data Availability
- Unlimited Scalability
- High Transfer Fee
- Integrated with Identity Management
- Autocorrect
- data protection
- Server-Side Encryption
- elastic sizing
- Flexible Connectivity Options
- Easy Integration
- Fault Tolerance
Object Storage – MinIO for Data Engineering
Object Storage MinIO is an Open Source Software, a good alternative to AWS S3, it can be easily installed on a Linux server, and customized similarly to AWS S3.
We have a complete dashboard where we create Buckets, grant access authorization per user, create groups, define IAM policies, view logs, and monitor access. These features are available in the free version.
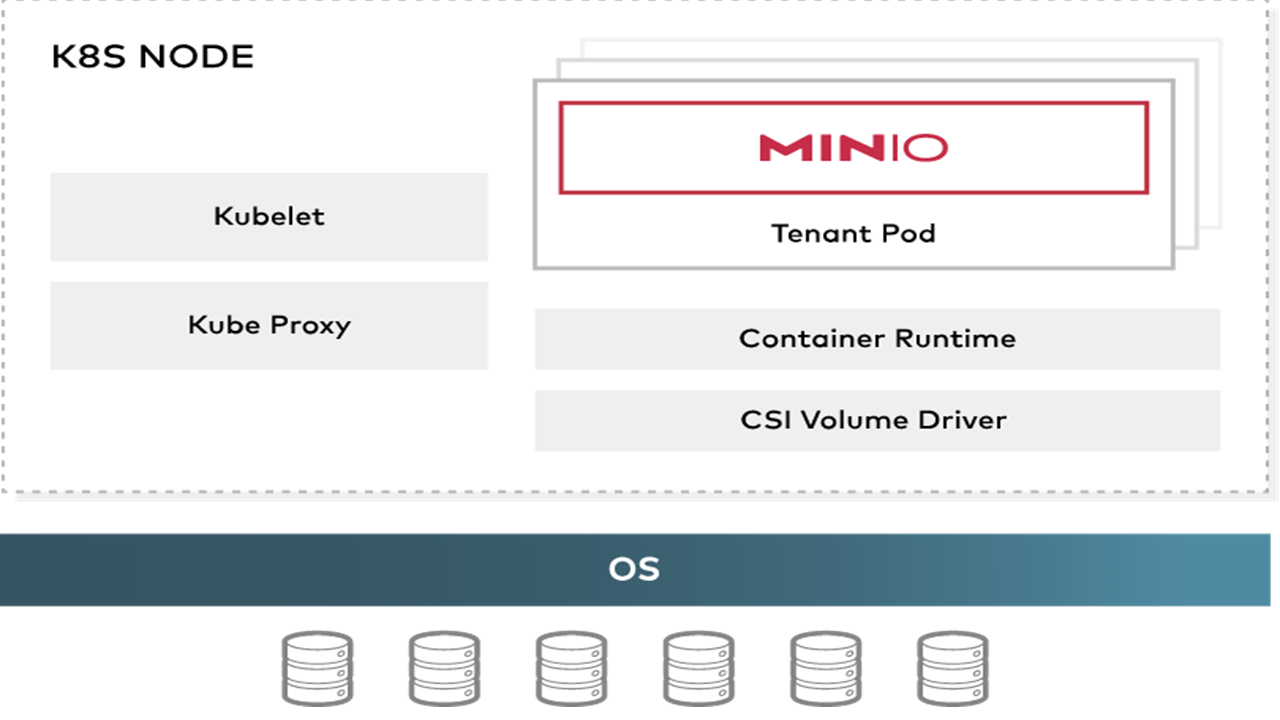
Image Source: Minio
Install Object Storage – MinIO
- Installing and Configuring Data Lake with Minio Server
- Inside the DataScience directory create the data lake directory.
- If you are using Windows open the Powershell terminal and run the command:
docker run -d -p 9000:9000 -p 9001:9001 -v "$PWD/datalake:/data" minio/minio server /data --console-address ":9001" --name minio
http://localhost:9001/login [username]: minioadmin [password]: minioadmin
Data Lake in Data Engineering
We implement Data Lake, through the Object Storage MinIO installed, in the ingest data stream from data extraction from an external source, the data is stored in the first bucket named Curated Bucket, later we have the second Bucket named Processing Bucket, and ending we have the third Bucket called Landing Bucket, in which the Machine Learning Model will access the data sets, for training and testing the model.
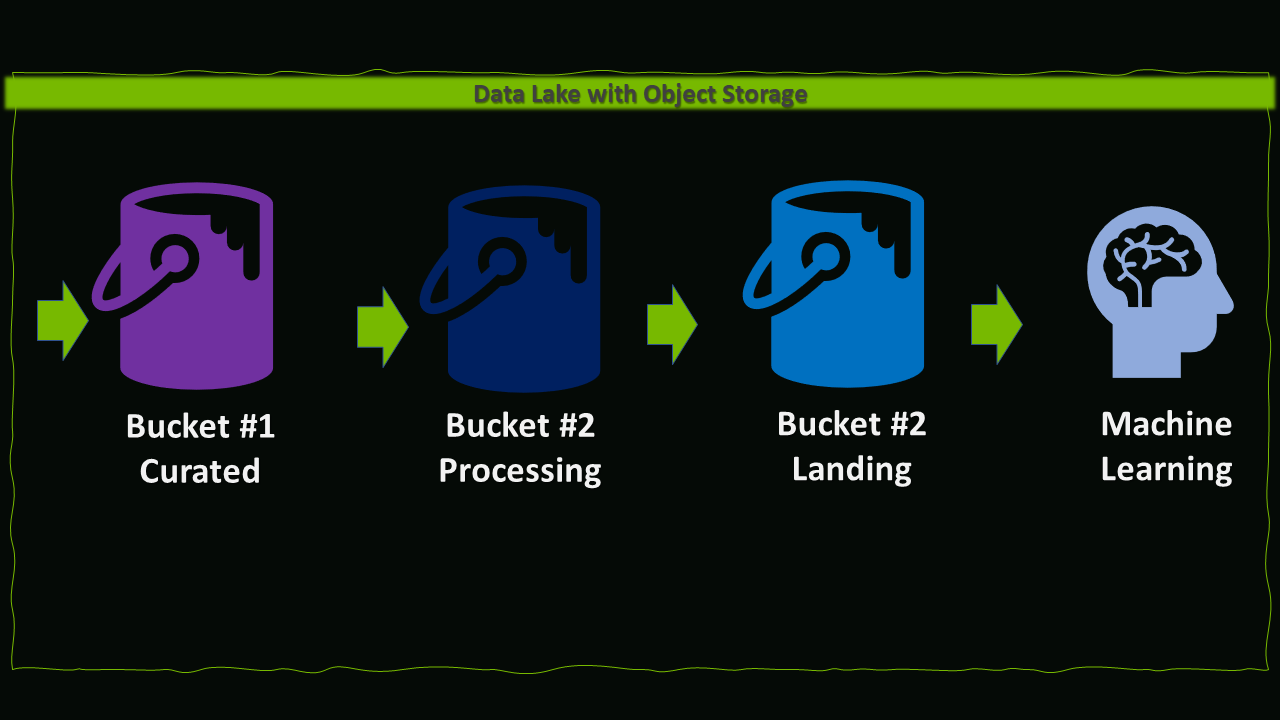
Image Source: GitHub
Bucket Management
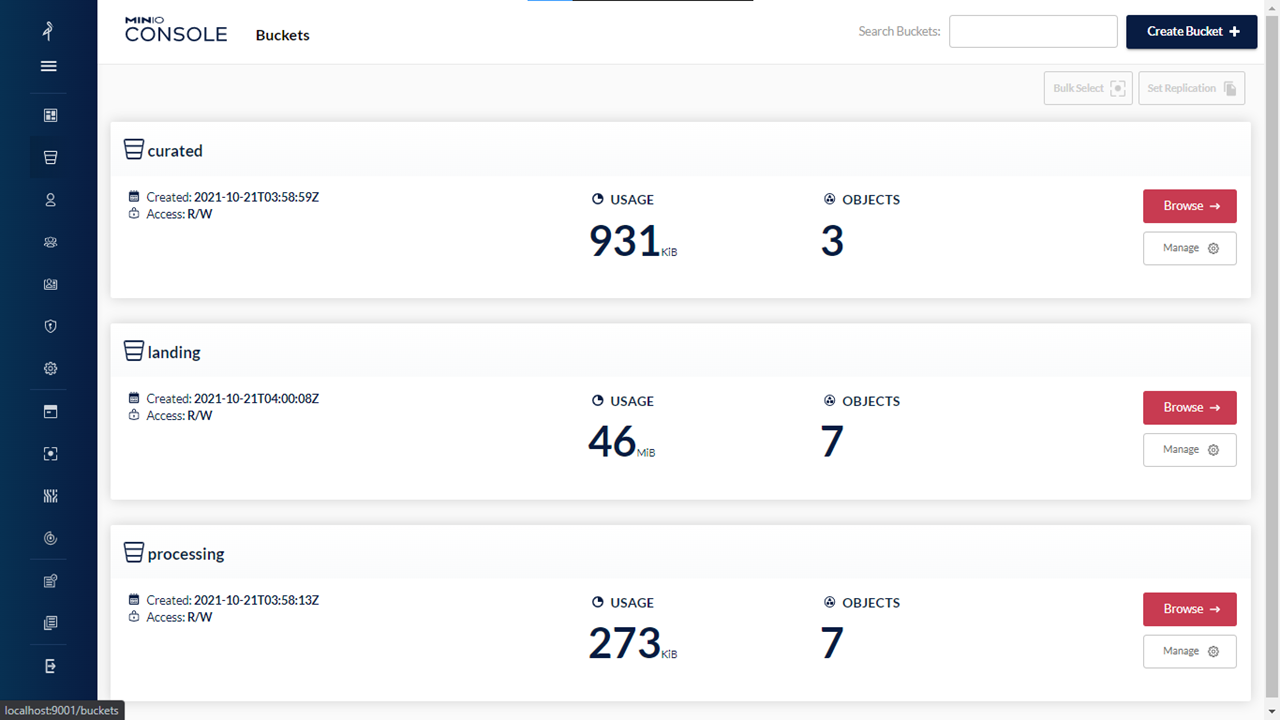
Image Source: GitHub
Below is the Data Lake repository on GitHub:
https://github.com/DataScience-2021/Analytics-Vidhya/tree/main/%23Data-Engineering/datalake
Curated Bucket #1
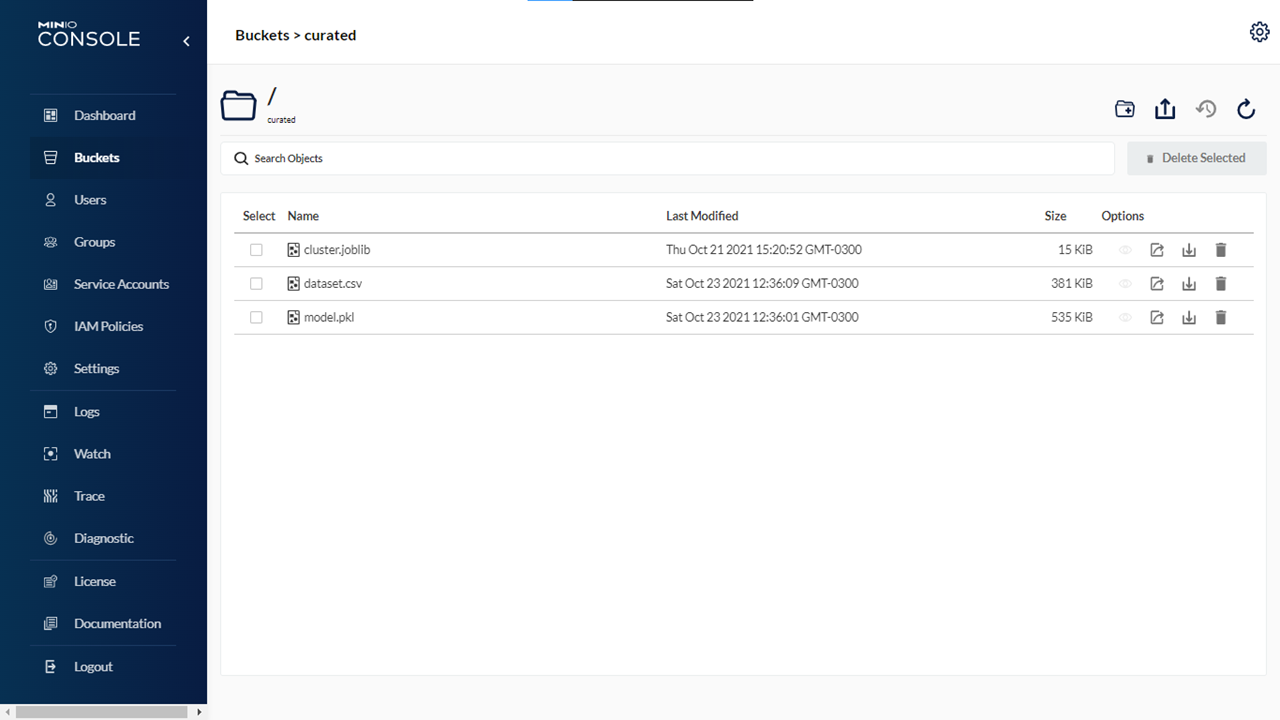
Image Source: GitHub
Below is the Curated Bucket repository on GitHub:
https://github.com/DataScience-2021/Analytics-Vidhya/tree/main/%23Data-Engineering/datalake/curated
Processing Bucket #2
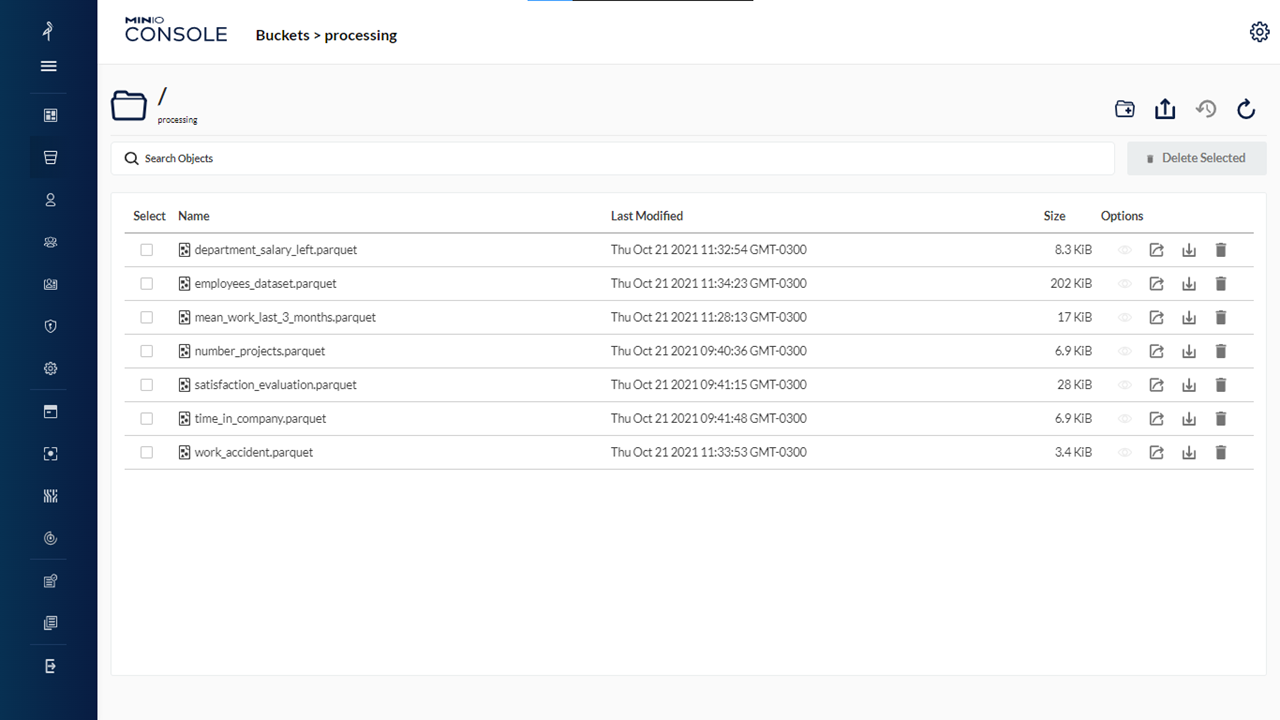
Image Source: GitHub
Below is the Processing Bucket repository on GitHub:
Landing Bucket #3
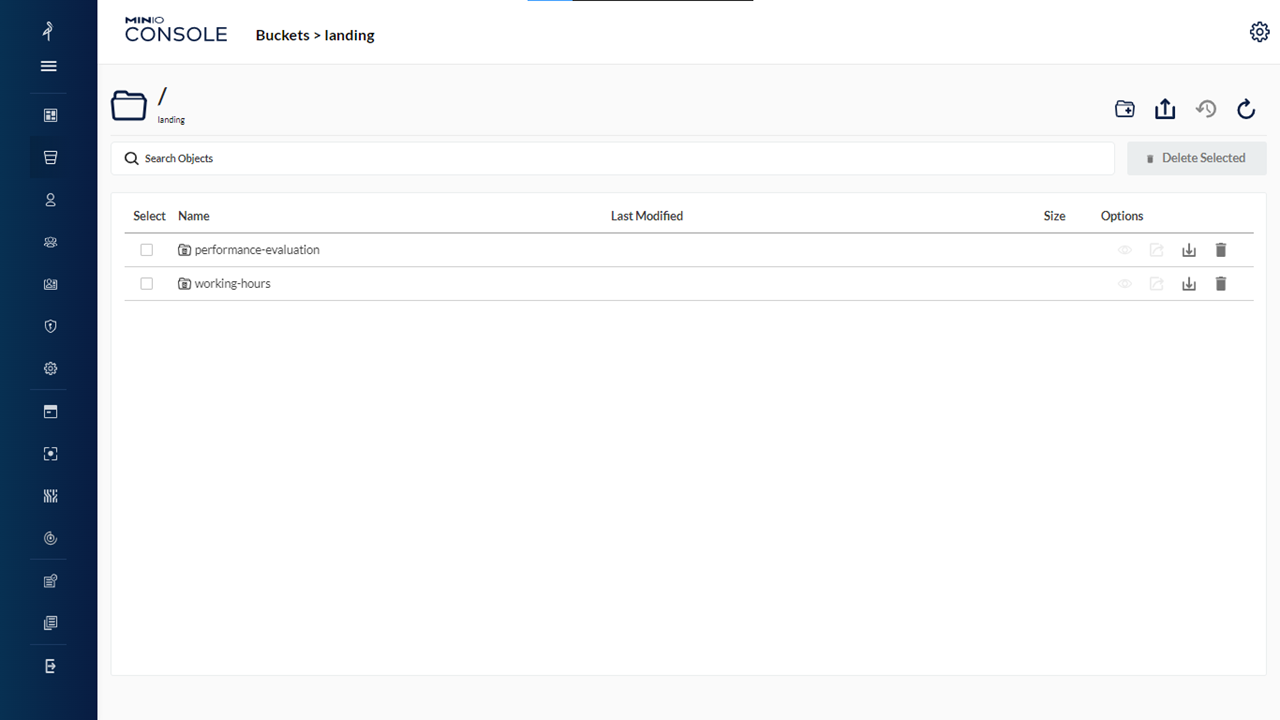
https://github.com/DataScience-2021/Analytics-Vidhya/blob/main/%23Data-Engineering/DataEngineering/Slide22.PNG
Below is the Landing Bucket repository on GitHub:
In Landing Bucket, we have the output of the Machine Learning model, after training, testing, and validation of the model.
Follow the output of the model:
https://github.com/DataScience-2021/Analytics-Vidhya/blob/main/%23Data-Engineering/datalake/landing/performance-evaluation/employee_performance_evaluation.json
{"emp_id":10001,"satisfaction_level":38.0,"last_evaluation":53.0}
{"emp_id":10002,"satisfaction_level":80.0,"last_evaluation":86.0}
{"emp_id":10003,"satisfaction_level":11.0,"last_evaluation":88.0}
{"emp_id":10004,"satisfaction_level":72.0,"last_evaluation":87.0}
{"emp_id":10005,"satisfaction_level":37.0,"last_evaluation":52.0}
{"emp_id":10006,"satisfaction_level":41.0,"last_evaluation":50.0}
{"emp_id":10007,"satisfaction_level":10.0,"last_evaluation":77.0}
{"emp_id":10008,"satisfaction_level":92.0,"last_evaluation":85.0}
{"emp_id":10009,"satisfaction_level":89.0,"last_evaluation":100.0}
{"emp_id":10010,"satisfaction_level":42.0,"last_evaluation":53.0}
{"emp_id":10011,"satisfaction_level":45.0,"last_evaluation":54.0}
{"emp_id":10012,"satisfaction_level":11.0,"last_evaluation":81.0}
{"emp_id":10013,"satisfaction_level":84.0,"last_evaluation":92.0}
{"emp_id":10014,"satisfaction_level":41.0,"last_evaluation":55.0}
{"emp_id":10015,"satisfaction_level":36.0,"last_evaluation":56.0}
{"emp_id":10016,"satisfaction_level":38.0,"last_evaluation":54.0}
{"emp_id":10017,"satisfaction_level":45.0,"last_evaluation":47.0}
{"emp_id":10018,"satisfaction_level":78.0,"last_evaluation":99.0}
{"emp_id":10019,"satisfaction_level":45.0,"last_evaluation":51.0}
{"emp_id":10020,"satisfaction_level":76.0,"last_evaluation":89.0}
{"emp_id":10021,"satisfaction_level":11.0,"last_evaluation":83.0}
{"emp_id":10022,"satisfaction_level":38.0,"last_evaluation":55.0}
{"emp_id":10023,"satisfaction_level":9.0,"last_evaluation":95.0}
{"emp_id":10024,"satisfaction_level":46.0,"last_evaluation":57.0}
{"emp_id":10025,"satisfaction_level":40.0,"last_evaluation":53.0}
Demo Data Lake Management
A brief demonstration of our Data Lake created, using the MinIO Object Storage resources, with three Buckets, the last being Landing Bucket will be accessed by the Machine Learning model.
Conclusion
This article aimed to show Data Science professionals how to use Data Engineering components in an agile way, to generate Machine Learning models with good performance and accuracy.
We show several software components, which are part of Data Engineering, with their main functionalities. We detail the Object Storage technically, we implement a Data Lake, with three buckets, which is integrated into a Machine Learning model.
In this way, I believe that it is good, to use the Object Storage MinIO, in the creation of a Data Lake for companies that are starting the journey in Machine Learning.
References
https://blogs.oracle.com/lad-cloud-experts-pt/post/o-que-e-object-storage-como-eu-utilizo
https://min.io/
Author Reference:
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






{kind=link}
Good Article ! Congrats !