This article was published as a part of the Data Science Blogathon
About Streamlit
Streamlit is an open-source Python library that assists developers in creating interactive graphical user interfaces for their systems. It was designed especially for Machine Learning and Data Scientist team. Using Streamlit, we can quickly create interactive web apps and deploy them. Frontend work is not much important for Data Scientists, and they only want a small interactive place for users to complete their job without worrying about modelling algorithms and parameters. Streamlit makes it easy to serve ML models to other users and view prediction in the web app.
Getting Started With Streamlit
First, you have to make sure you have python installed in your system. You can download and install it from official python documentation.
Now install Streamlit using the pip command. You can find more about installation on the official documentation of Streamlit.
Let’s see how to run the Streamlit App.
Use your favorite python editor and create a new python file. Now import Streamlit library and set page layout using the below command.
import streamlit as st
st.set_page_config(page_title='ML Hyperparameter Optimization App',layout='wide') #Setting Page layout, Page expands to full width
To run the Streamlit App in your local system, run the following command in your console to ensure you are in the same directory where you have the above file.
streamlit run your_app_name.py
You will see a link in the terminal; open that link to redirect you to your Streamlit App. You will see the rerun option in the top left corner when you change your source file. Click that so it will update your App according to your new code.
Now we know how to run Streamlit. Let’s build a classification model.
Preprocessing steps for our Classification Model
We are going to build a heart disease classification. You can download the dataset from here.
First, we have to import necessary libraries to help us build a Random forest classification model.
import streamlit as st #streamlit to build app import numpy as np #to do array manipulation import pandas as pd #to load dataset and to perform preprocessing steps
#scikit learn to build random forest model from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score from sklearn.model_selection import GridSearchCV from sklearn.metrics import accuracy_score,classification_report,plot_confusion_matrix
import plotly.graph_objects as go #to plot visualization
Load the CSV file into a pandas data frame using the panda’s library and display some of the rows of the dataset into our App. Do not forget to rename the CSV file to the dataset.
st.write("""
# Machine Learning Hyperparameter Optimization App
### **(Heart Disease Claasification)**""")
df = pd.read_csv('dataset.csv')#loading dataset into pandas dataframe
#Displays the dataset
st.subheader('Dataset')
st.markdown('The **Heart Disease** dataset is used as the example.')
st.write(df.head(5)) #displays the first five-row of dataset.
The write function writes input string into your App; you can create different heading using multiple ‘#’ and write words in bold using **()**. Rerun Streamlit in your browser; you should see your web app as below image.

We will create a button that triggers the build function, which will build the classification model on given input hyper-parameters.
if st.button('Build Model'):
#some preprocessing steps
dataset = pd.get_dummies(df, columns = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal'])
model(dataset)
When the build model is valid (means you click that button), it will perform some basic preprocessing steps, such as creating dummy columns for categorical data of our dataset. After that, it will call the model function.
def model(df):
Y = dataset['target']
X = dataset.drop(['target'], axis = 1)
# Data splitting
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=split_size)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
This function takes a pandas data frame as input. Y is the target variable, and it has 0(no disease) and 1(has heart disease). X consists of all independent variables in the data frame. Let’s split our data into two parts train and test. Here, the user will define test size, which is stored in split_size. In the following line, we have initialized the standard scaler and train data; test data is scaled on train data to ensure no data leakage.
Creating Sidebar
Now let’s make a sidebar that will take values from users for our hyperparameters of random forest classifier. The below code we will write outside our function.
st.sidebar.header('Set HyperParameters For Grid SearchCV') #to create header in sidebar
split_size = st.sidebar.slider('Data split ratio (% for Training Set)', 50, 90, 80, 5)
To append the Streamlit component into the sidebar, we have to use the sidebar in our code. Slider in Streamlit allows you to render a range or single integer. In the above code, 50 is min, 90 is max, 80 is the default, and 5 is a step value.
st.sidebar.subheader('Learning Parameters')
parameter_n_estimators = st.sidebar.slider('Number of estimators for Random Forest (n_estimators)', 0, 500, (10,50), 50)
parameter_n_estimators_step = st.sidebar.number_input('Step size for n_estimators', 10)
n_estimator is means the number of trees in a random forest. Using the slider, we can get the range for several trees we can use in gridsearchcv and (10,50) is the default range.
st.sidebar.write('---')
parameter_max_features =st.sidebar.multiselect('Max Features (You can select multiple options)',['auto', 'sqrt', 'log2'],['auto'])
In the above line, multi-select allows multiple values from given options, and auto is the default value for the max_feature hyperparameter.
parameter_max_depth = st.sidebar.slider('Maximum depth', 5, 15, (5,8), 2)
parameter_max_depth_step=st.sidebar.number_input('Step size for max depht',1,3)
max_depth is the longest path possible between root to the leaf node of a tree in Random Forest. Here we get a range of max_depth using the slider.
st.sidebar.write('---')
parameter_criterion = st.sidebar.selectbox('criterion',('gini', 'entropy'))
The above code gives one of the criteria for a split of nodes.
The below line also returns one value between 2 to 10 used for the number of folds in cross-validation.
st.sidebar.write('---')
parameter_cross_validation=st.sidebar.slider('Number of Cross validation split', 2, 10)
Now, let’s also define some other hyperparameters too.
st.sidebar.subheader('Other Parameters')
parameter_random_state = st.sidebar.slider('Seed number (random_state)', 0, 1000, 42, 1)
parameter_bootstrap = st.sidebar.select_slider('Bootstrap samples when building trees (bootstrap)', options=[True, False])
parameter_n_jobs = st.sidebar.select_slider('Number of jobs to run in parallel (n_jobs)', options=[1, -1])
We have to create a numpy array for several estimators and max_depth. We can do it with the below lines of code. Define param_grid (dictionary of parameters value which you won’t use for grid search).
n_estimators_range = np.arange(parameter_n_estimators[0], parameter_n_estimators[1]+parameter_n_estimators_step, parameter_n_estimators_step) """ if parameter_n_estimators[0] is 5 and parameter_n_estimators[1] 25 and parameter_n_estimators_step is 5 then array will be [5,10,15,20,25] """ max_depth_range =np.arange(parameter_max_depth[0],parameter_max_depth[1]+parameter_max_depth_step, parameter_max_depth_step) param_grid = dict(max_features=parameter_max_features, n_estimators=n_estimators_range,max_depth=max_depth_range)
Now our App should look like the below image.
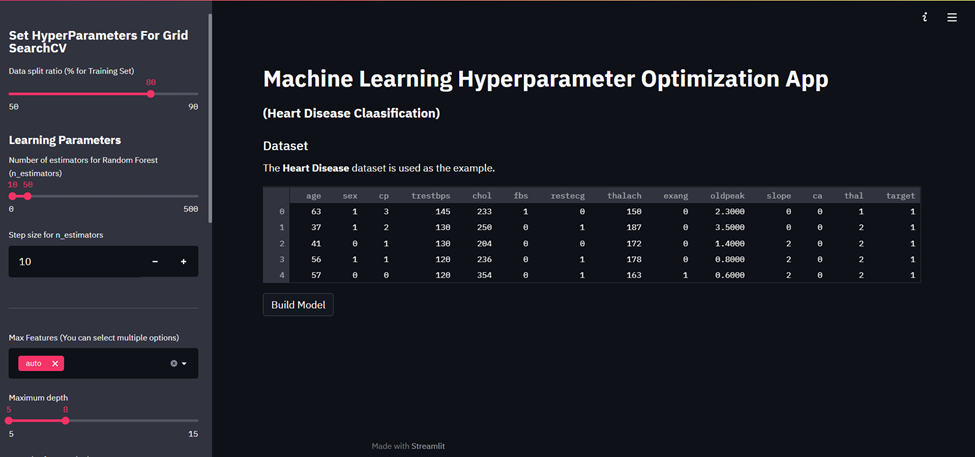
Random Forest Classifier
Let’s complete our model function, which we have defined above. After the X_test line, all the below code snippets will go under the model function.
rf = RandomForestClassifier(random_state=parameter_random_state,
bootstrap=parameter_bootstrap,
n_jobs=parameter_n_jobs)
grid = GridSearchCV(estimator=rf, param_grid=param_grid, cv=parameter_cross_validation)
grid.fit(X_train, Y_train)
st.subheader('Model Performance')
Y_pred_test = grid.predict(X_test)
We initialized our model using RandomForestClassifier() and passed some hyperparameters to it, given by the user. Below that, we define our search space as a grid of hyperparameter values, and GridSearchCV evaluates every position in the grid. We passed Random Forest as our model; param_grid consists of different parameters and no folds as cv. At last, we have predicted output classes on test data.
st.write('Accuracy score of given model')
st.info( accuracy_score(Y_test, Y_pred_test) )
accuracy_score() returns our model’s accuracy on test data, and we will show that on our App using st.info().
st.write("The best parameters are %s with a score of %0.2f" %(grid.best_params_, grid.best_score_))
Grid.best_params_will return parameters that give the best result from the parameters we used as param_grid.
st.subheader(‘Model Parameters’)
st.write(grid.get_params())
The above function will return all the parameters used in building the model.
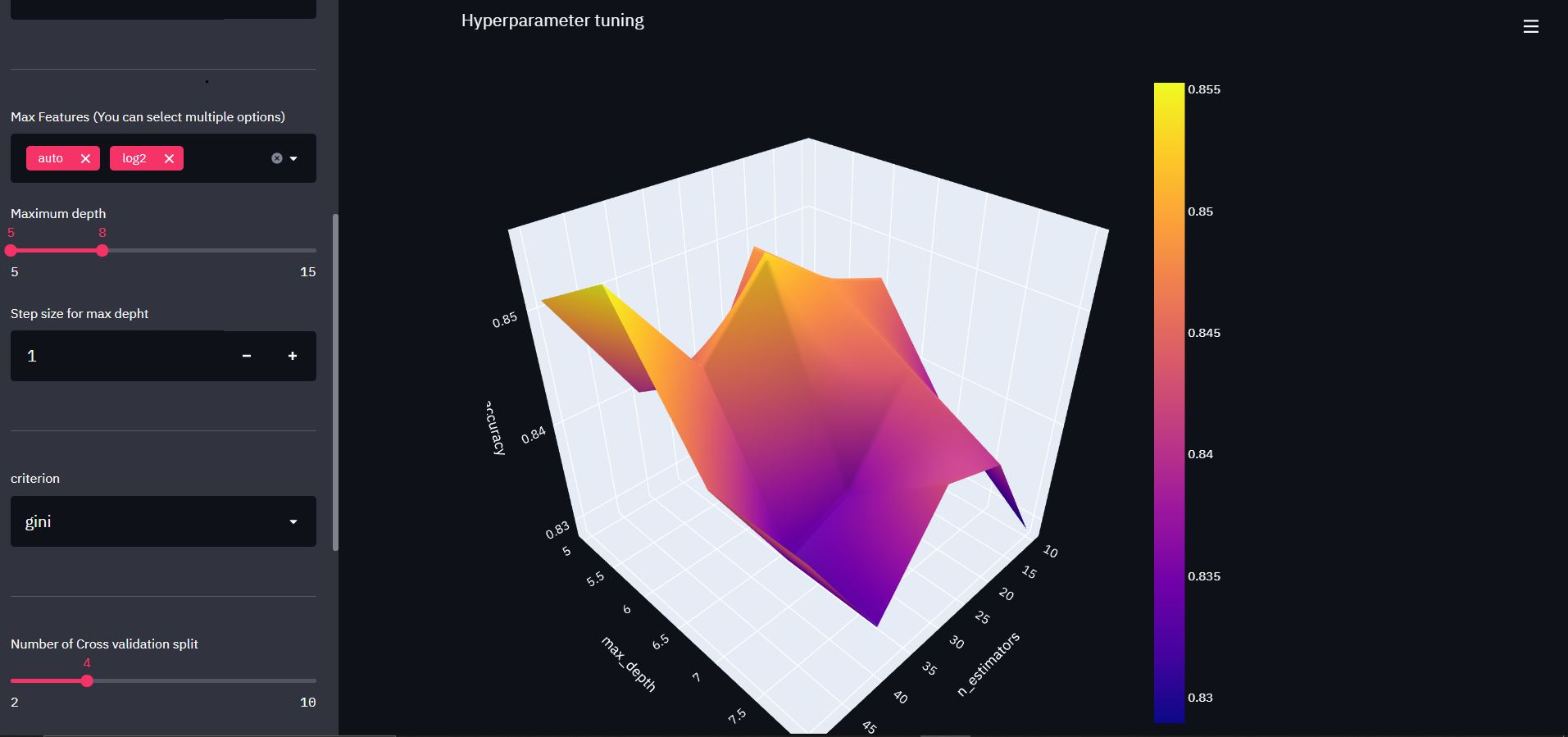
Let’s build a 3D visualizer
#-----Process grid data-----#
grid_results=pd.concat([pd.DataFrame(grid.cv_results_["params"]),pd.DataFrame(grid.cv_results_["mean_test_score"], columns=["accuracy"])],axis=1)
we will create pandas data frames using params and accuracy, concatenate them, and store them in the grid_results variable. We are going to group data using 2 parameters, max_depth and n_estimators. Because we want to develop a 3d plot of these 2 parameters vs accuracy.
grid_contour = grid_results.groupby(['max_depth','n_estimators']).mean()
grid_reset = grid_contour.reset_index()
grid_reset.columns = ['max_depth', 'n_estimators', 'accuracy']
grid_pivot = grid_reset.pivot('max_depth', 'n_estimators')
x = grid_pivot.columns.levels[1].values
y = grid_pivot.index.values
z = grid_pivot.values
Create x,y and z index for plots here; x-axes are a number of the estimator, y-axes are the max depth, and z-axes represent the model’s accuracy.
#define Layout and axis
layout = go.Layout(
xaxis=go.layout.XAxis(
title=go.layout.xaxis.Title(
text='n_estimators')
),
yaxis=go.layout.YAxis(
title=go.layout.yaxis.Title(
text='max_depth')
) )
fig = go.Figure(data= [go.Surface(z=z, y=y, x=x)], layout=layout )
fig.update_layout(title='Hyperparameter tuning',
scene = dict(
xaxis_title='n_estimators',
yaxis_title='max_depth',
zaxis_title='accuracy'),
autosize=False,
width=800, height=800,
margin=dict(l=65, r=50, b=65, t=90))
st.plotly_chart(fig)
Here we have used the plotly library to plot 3d plot of our model. plotly can be used with Streamlit using the plotly_chart() function we have to pass fig in this function. Now let’s print precision, recall and f1-score of both the classes using inbuilt scikitlearn function classification_report. We can access each element using class names and different scores, passing them as key. Write them into App using st. write()
st.subheader("Classification Report")
#it will return output in the form of dictionary
clf=classification_report(Y_test, Y_pred_test, labels=[0,1],output_dict=True)
st.write("""
### For Class 0(no disease) :
Precision : %0.2f
Recall : %0.2f
F1-score : %0.2f"""%(clf['0']['precision'],clf['0']['recall'],clf['0']['f1-score']))
st.write("""
### For Class 1(has disease) :
Precision : %0.3f
Recall : %0.3f
F1-score : %0.3f"""%(clf['1']['precision'],clf['1']['recall'],clf['1']['f1-score']))
st.subheader("Confusion Matrix")
plot_confusion_matrix(grid, X_test, Y_test,display_labels=['No disease','Has disease'])
st.pyplot()
With the above lines of code, we have completed our model function. Now our App is ready to use; save all changes and rerun your App; after that, set the range of hyperparameters and click on the build; you should 3D graph as the below image.
Conclusion
By just adding a few lines of code into your machine learning project, you can build such an excellent frontend app with the help of Streamlit.
In a true sense, Streamlit has made life easier for machine learning practitioners.
Play with my App by clicking here.
References:
- Official Documentation of Streamlit:- https://docs.streamlit.io/
- More about Hyperparameter tuning and different techniques to do it https://machinelearningmastery.com/hyperparameter-optimization-with-random-search-and-grid-search/
- Scikit Learn Documentation: https://scikit-learn.org/stable/user_guide.html
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.





