This article was published as a part of the Data Science Blogathon.
” The only way to test the hypothesis is to look for all the information that disagrees with it – Karl Popper“
Hypothesis Testing comes under a broader subject of Inferential Statistics where we use data samples to draw inferences on the population parameters. The hypothesis testing can be used to compare a population parameter to a particular value, compare two populations and check whether a population follows a probability distribution, etc. The topic of hypothesis testing is quite detailed and it would not be possible to full justice to the study in a short article. However, let’s do a sincere attempt to get an overall view of the hypothesis process through an end-to-end case study. I have focused more on the practical implementation and requisite basic theory has been highlighted as required.
Hypothesis Testing- An Overview
The overall flow process involved in hypothesis testing is as follows :
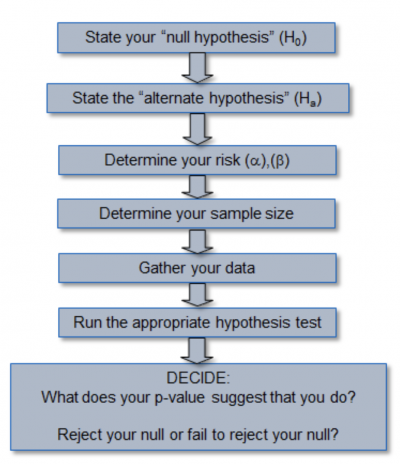
The hypothesis testing involves a statement about the population parameter called Null Hypothesis Ho, and an Alternate hypothesis denoted by Ha is stated as opposite of Null Hypothesis. We collect data and carry out testing and based on the evidence emerging from the analysis, we reject Ho or fail to reject Ho. We are using sample data to draw inference on the population and there is a risk involved in our decision. We can choose the level of risk based on the use case (how much are you willing to accept this risk ?). The confidence level chosen is usually 99%,95%, and 90%, the associated term involved is the Level of significance which is 0.01,0.05 or 0.1 corresponding to the above confidence level. The errors are called Type I Error (you reject Ho when it is True ) and Type II Error (you fail to reject Ho when you should have ! ). We get test statistic and p-value based on our testing and these values form our metrics for rejecting Ho or failing to reject Ho. The p-value tells us what is the likelihood of our sample results if we assume Ho to be true. P-value also called the observed level of significance, if found to be less than our chosen level of significance(called alpha), we reject Ho else we fail to reject Ho.
Another aspect we note in the hypothesis testing is Independent and Dependent samples. The two samples may be independent if they are not related to each other and they can be dependent if one sample can be used to estimate other samples. The hypothesis testing has multiple approaches considering whether we are dealing with dependent or independent samples or on the number of samples available(z-test or t-test), etc. The example of a dependent samples hypothesis testing may be analyzing the weight of a group before and after a weight loss program or a corn, flake manufacturer want to test whether the average weight of packets being manufactured is equal to a specified value of say,500 gms.
In our end to the end case study, we shall take independent samples to study the methodology of hypothesis testing. We will make use of python code to make our life easier rather than go through the grind to do the testing part ( please feel free to trace back method through classical statistics process . It will strengthen your understanding).
Problem Definition for Hypothesis Testing
While having a casual talk with your friend, he mentions that the average cost of iPhones at an eCommerce website A is not equal to eCommerce website B. As a Data Scientist, you trust in evidence provided by data and gets on to analyze the problem scientifically. Let’s define Ho and Ha,
H0: µ1 = µ2 (the two population means are equal)
HA: µ1 ≠µ2 (the two population means are not equal)
Data Analysis and Hypothesis Testing
Of course, we need data to test the above hypothesis and we choose a level of significance of 0.05 for our test. For our case study we have chosen amazon.co.in and flipkart.com, two eCommerce websites in India(just a random choice). At the cost of keeping the code simple, I have collected the prices of iPhones shown on the first search page on both websites for testing. This has limitations in respect of data collected but let’s try and keep things simple. Let’s dive into the code,
from bs4 import BeautifulSoup import requests import pandas as pd import numpy as np HEADERS = ({'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36','Accept-Language': 'en-US, en;q=0.5'}) def get_data(URL,tag,attrs): ''' This function takes in an url , tag and attrs for scraping from a website''' webpage = requests.get(URL, headers=HEADERS) soup = BeautifulSoup(webpage.content, "html.parser") price = soup.find_all(tag, attrs=attrs) price_list =[] for p in price: price_list.append(p.text) return price_list
We take the help of requests and the BeautifulSoup library to scrape the data from the website, use Pandas to present the data, and use scipy and numpy to do the hypothesis testing. Many websites have protocols in place for blocking access by robots. To extract data we need to create a user agent which carries information about the host sending request to the server. We have created a function to retrieve the price data from the website. The URL of our website is passed to ‘get method’ from the requests library and the response is passed to BautifulSoup along with an HTML parser to construct a soup object. One of the difficult tasks is to identify HTML tags and ids where the price information is stored. We can go to the website page and hover the mouse on top of the price and right-click to navigate to inspect the webpage and retrieve HTML tags.
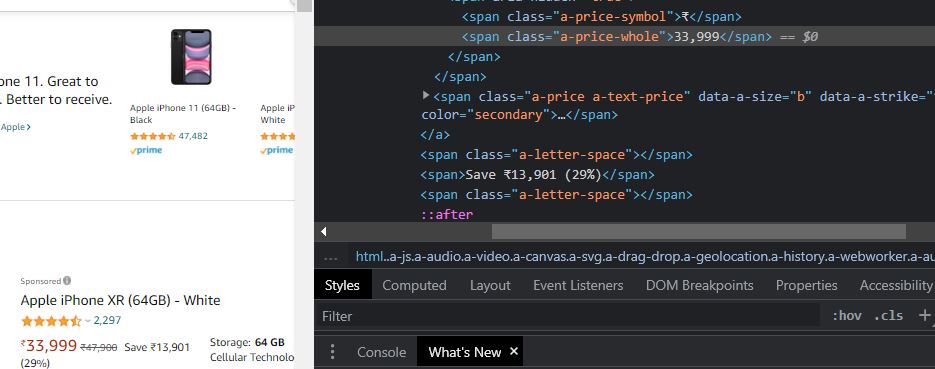
We see that the price information is under the tag and class = ‘a-price-whole’ for the amazon search page for iPhones. We use the find_all() method to get all price data on the page. Similarly, we can get similar information for ‘flipkart.com‘ as well(the URL, tags, and attrs will be different and we get it by inspecting the webpage)
#get iphone price from amazon
amazon_url = "https://www.amazon.in/s?k=iphones&ref=nb_sb_noss_2"
amz_attrs={'class':'a-price-whole'}
amz_tag = "span"
amazon_price = get_data(amazon_url,amz_tag,amz_attrs)
The call of function returns a list containing the price from the amazon website. We can use the same function to retrieve price info from flipkart as well.
#get flipkart prices
flipkart_url = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
flip_attrs={'class':'_30jeq3 _1_WHN1'}
flip_tag = "div"
flipkart_price = get_data(flipkart_url,flip_tag,flip_attrs)
We can create a dataframe to present our data nicely. As length of price obtained from amazon and flipkart is different, we need little tweaking in our code. We use pd.DataFrame_from_dict() function to create a dataframe from dictionary and take Transpose to structure our dataframe and then fill NaN values with value 0(commands have been chained , Feel free to split if you like)
#create a dataframe with these columns
my_dict = {'amazon_rs':amazon_price,'flipkart_rs':flipkart_price}
data = pd.DataFrame.from_dict(my_dict,orient='index').T.fillna(0,axis=1)
print(data.head())
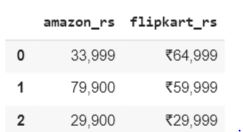
The job of a Data Scientist involves cleaning the data so that we can do further processing. It is to be noted that the data scraped from the website is an object type and needs formatting before we do the hypothesis testing. The rows where data is not available for one website to have been filled with 0 by using the fillna() method. The following code will take care of preprocessing and be ready for hypothesis testing.
#data preprocessing
data['amazon_rs'] = data['amazon_rs'].str.replace(',','').astype(float)
data['flipkart_rs'] = data['flipkart_rs'].str.strip('₹')
data['flipkart_rs'] = data['flipkart_rs'].str.replace(',','').astype(float)
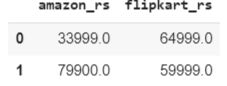
The post-processing of data is shown above and both columns contain float datatypes. We need to check whether both samples follow normal distribution to understand the type of hypothesis test to be performed on the data. If the samples are normal or if the sample size is quite large (n>30) we can go for a t-test from scipy.ttest_ind(). If the samples are normal we need to further test samples for equal variance and generally as a rule of thumb, if the ratio of variances is less than 4:1 we can assume equal variance else we have to test with equal_variance=False. In our case, it is noted that we will use pandas slicing for the shorter data(data with lesser rows) We will test for normality using Shapiro-Wilks Test.
#testing samples for normality import scipy.stats as stats print(stats.shapiro(data['amazon_rs'].iloc[:18])) print(stats.shapiro(data['flipkart_rs']))

The Null hypothesis in the Shapiro-Wilks test assumes normal distribution and we get test statistic and p-value from running the above code. As the p-value is less than a generally used reference value of 0.05, we conclude that the samples do not come from a normal distribution. As we do not have large sample sizes, we can’t use a t-test for this problem. Hence, we go for a non-parametric test like Mann–Whitney U test, which can be applied on unknown distributions and is found to be as efficient as the t-test on normal distributions. If we look at our Ha, we say µ1 ≠µ2, and hence we need to carry out the two-tailed test and if the Ha statement talks about then we limit our test to a one-sided test. We again take help from scipy library to carry out this test,
# perform the two-sided test. You can use 'greater' or 'less' for one-sided test stats.Mann-Whitney U(x=data['amazon_rs'].iloc[:18], y=data['flipkart_rs'], alternative = 'two-sided')

Inference
The results are as shown and it is seen that the test statistic is 153 and the p-value is 0.11. As the p-value is found to be greater than the significance level of 0.05, we fail to reject Null Hypothesis ,Ho . At a 95% confidence level, we do not have the evidence to say that the mean price of iPhones from eCommerce A(amazon) and B(Flipkart) are different. The results of this test vary from one code run to another as the data is dynamic,
Conclusion
The Case Study was used to understand the overview of the hypothesis testing for data analysis on two independent samples. I feel the case study approach can help cement your understanding of hypothesis testing theory and look at real-life problems. As a disclaimer, I would like to highlight that this was purely an academic project and the source of data was chosen at random No practical conclusions can be drawn from above to compare the prices in the shortlisted eCommerce websites, as this is purely a limited academic effort. I would recommend to the readers to explore other facets of the hypothesis testing as statistics is one of the major pillars of Data Science as well as try analysis with more data.
The Author, Subramanian Hariharan is a Marine Engineer with more than 30 Years of Experience and is very passionate about leveraging Data for Business Solutions.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion
A Marine Engineering professional with more than 29 years experience with a passion to leverage data for business solutions. I am a post graduate In Mechanical Engineering with experiences ranging from Operations, Production, Project Management, Quality Management and Data Analytics. I have also completed Advanced Certification in Data Science from Thayer School of Engineering , University of Dartmouth. I strongly believe learning is continuous process for growth in life and sharing knowledge builds a sense of community





