This article was published as a part of the Data Science Blogathon.
Table of Contents
- Chatbot – Introduction
- Chatbot – Types
- Application of Chatbot
- Architecture of Chatbot
- How does Chatbot work
- Python implementation of Chatbot
Introduction to Chatbot
In this article, we’ll look at some exciting chatbot topics. What a chatbot is, is that when you open any website, whether it’s an education portal or an e-commerce site, you’ll see an option called “chat with us,” and if you click on it, you’ll be taken to a conversation. So, a chatbot is a simulator that is used to interact with humans (in this case, customers) to understand their doubts or any queries in particular, because we cannot always have customer support, so sometimes, instead of customer support representatives, we will have a chatbot that understands the customer’s queries and professionally responds to them. This concept did not emerge recently; it first appeared in the 1950s. Alan Turing had the idea that what if a computer could communicate with other people without realizing it was a computer (Chatbot) responding? This idea became known as the “Tuning test,” which is where chatbots got their start. In 1966, Joseph Weizenbaum introduced the first-ever Chatbot, which he named E.L.I.Z.A….. In summary, the Chatbot can be linked to the equation below:
Chatbot = Artificial Intelligence + Human Computer Interaction
Still, for a better understanding, most people who use Apple phones have a term called S.I.R.I….., which we refer to as a chatbot, while Microsoft users have Cortana, Google Assistant, and so on. Chatbots are the technical term for these digital assistants.
History of Chatbot
Many chatbots exist, but still, some forms the trending among the rest, and those chatbots are as follows:
- Eliza in 1966
- Parry in 1972
- A.L.I.C.E.. in 1995
- Smart Child in 2001
- S.I.R.I….. in 2010
- Google Now in 2012
- Alexa in 2018
Types of Chatbot
- Depending on the application, chatbots are classified as:
- Text-based Chatbot
- Voice-based Chatbot
- Depending based on design, again chatbots are classified as
- Rule-based Chatbot
- Self-learning chatbot
Applications of Chatbot
There are numerous ways these chatbots are used in and around the world, but still, some critical applications where these chatbots can be used are:
- Helpdesk assistant
- Email distributor
- Home assistant
- Operation assistant
- Phone assistant
- Entertainment assistant
- Healthcare
- Education
- Retail and marketing
Architecture of Chatbots
For all concepts, the central core of the idea is architecture, so we’ll look at the architecture behind the chatbot concept in this topic. Let’s start with the front end and work our way back to the back end to clarify.
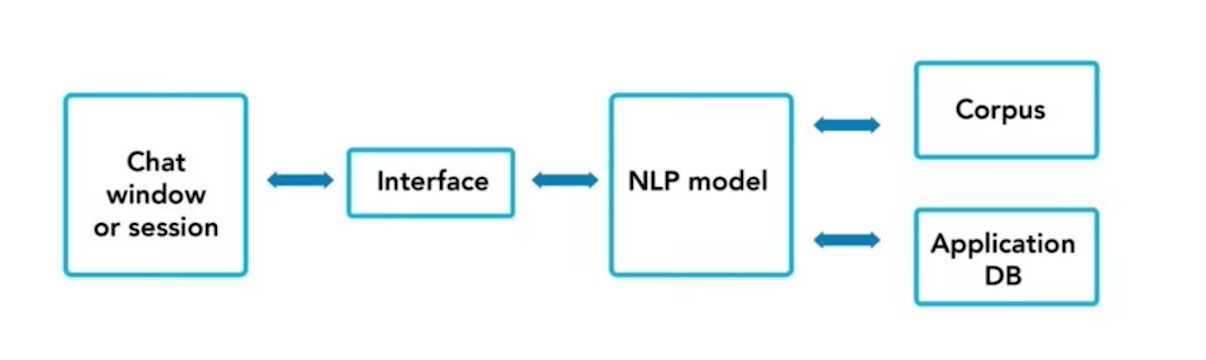
Image Source: Authors image
So, in our busy schedules, most of them use Swiggy, Zomato, even A.C.T…. the internet, or any other basic day-to-day daily usage app to meet our needs. Here I am considering A.C.T…. internet connection for our better understanding, as this is a pandemic, and we all know how important the internet is in our lives. If the internet goes down during our peak hours, we will open the A.C.T…. app and file a complaint, and it looks like this.
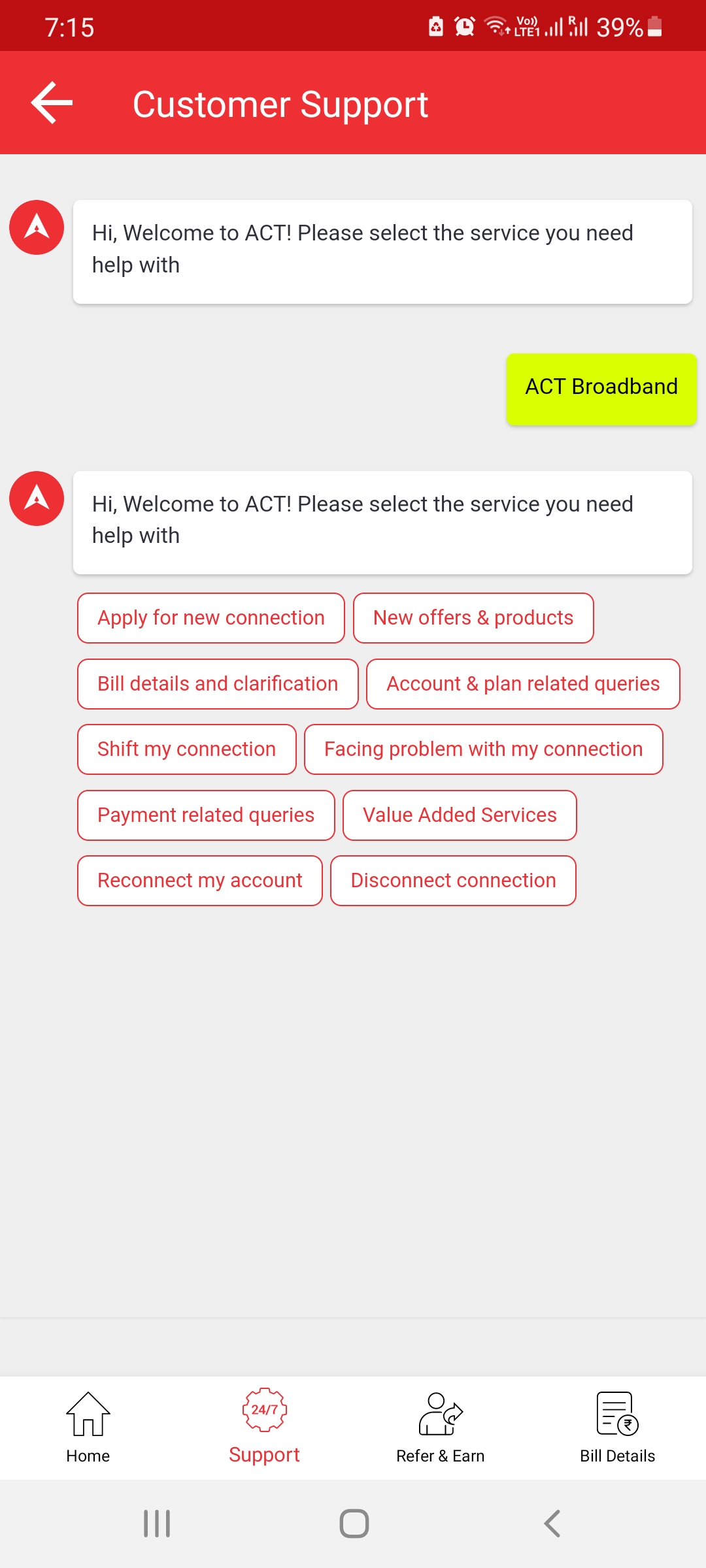
Image Source: Authors image
So, in the chat window, we see the screen above. Then there are a few options based on Natural Language Processing (N.L.P….) technology, which means a system that can read and understand human communication and then generate language in a human-like manner. So, based on our choices, the system will respond to our questions, and most people will find a solution through this conversation, either by booking tickets or by relying on expert advice. These options are referred to as information or data. They are technically referred to as a corpus, followed by application D.B…, which stands for database, and interface, which stands for Chatbot if we are not responding to the bot’s question. Then it will prompt us to respond with questions like, “Is that solution satisfactory?” or “Please wait for a moment.” This is the way the chatbot architecture works.
How does Chatbot Work?
Some most essential steps for the Chatbot to work from scratch are:
Corpus importing this is the exact steps that need to be processed first, so we need to give our bot some basic phrases or statements or even words to be learned for the queries sent by the customers, so without corpus or data, chatbot concepts will look nothing, because we cannot be able to respond to the queries asked by customers by understanding the corpus (data) and responding with proper solutions or reply. Example: If a customer is asking about some information or problem, the system must understand, and it should answer sensibly; otherwise, there is no use of chat or customer service, right! It’s almost like a person with zero knowledge in Python, Machine learning, or any technology related to data science but attending the interview for the job. Will, they will be selected? No, right, because the concerned person has no answers for the questions asked by the interviewer.
Pre-processing the data (Text case handling), next after importing corpus, even if you have tons and tons of data or information (raw data’s), without cleaning then the output of the model will be inaccurate because without washing mud stuffed clothes we cannot wear it suitable for our office proper? the same way we cannot process the raw data without cleaning. So here in the chatbot process, whatever information or data that we are receiving, either we are converting it into the lower case or upper case, to avoid misinterpretation or misrepresentation, because as we are receiving many data’s, to make it helpful to understand for the system, we need to make this conversion.
From the below picture, tokenization visualizes that tokenization means converting a sentence or paragraph to individual collection words. The primary purpose of converting to terms is chatbots won’t understand the terms like humans; it will give importance to words rather than sentences or anything. For that purpose only, we are converting into individual words,
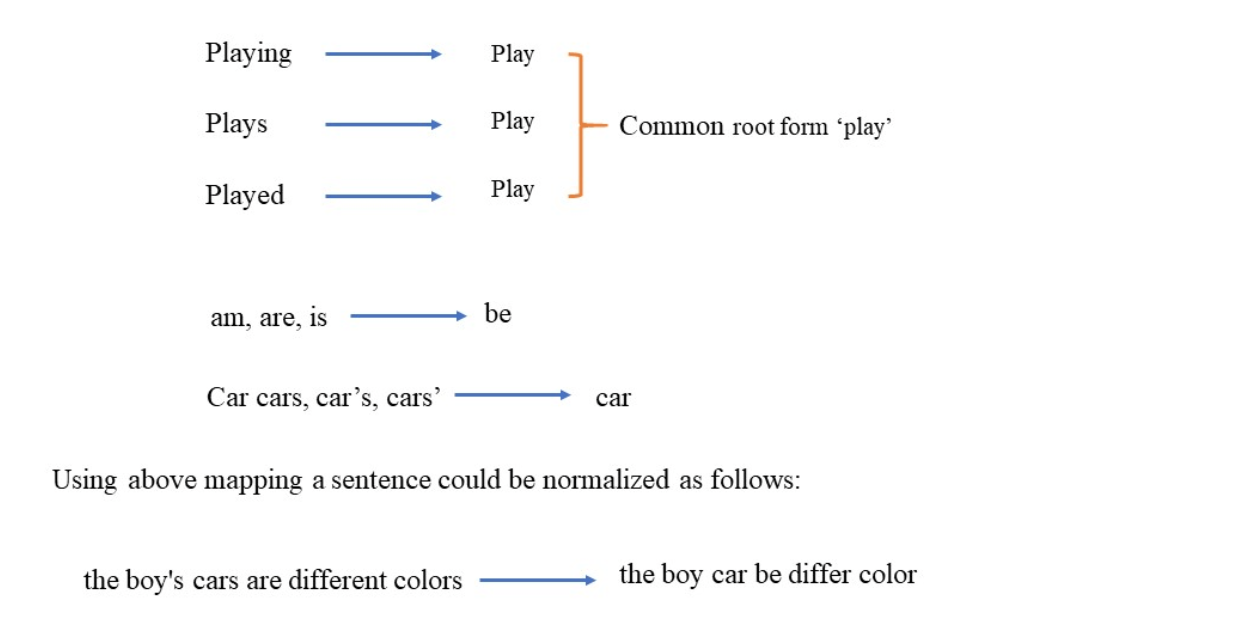
Stemming is the process of reducing inflected (the particular word can be in any tense form) words to their word stem (base form). It’s almost like whatever nicknames we have; our name is our entity, similar to stemming.
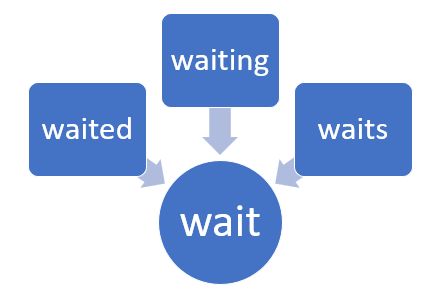
Image Source: https://www.c-sharpcorner.com/blogs/stemming-in-natural-language-processing
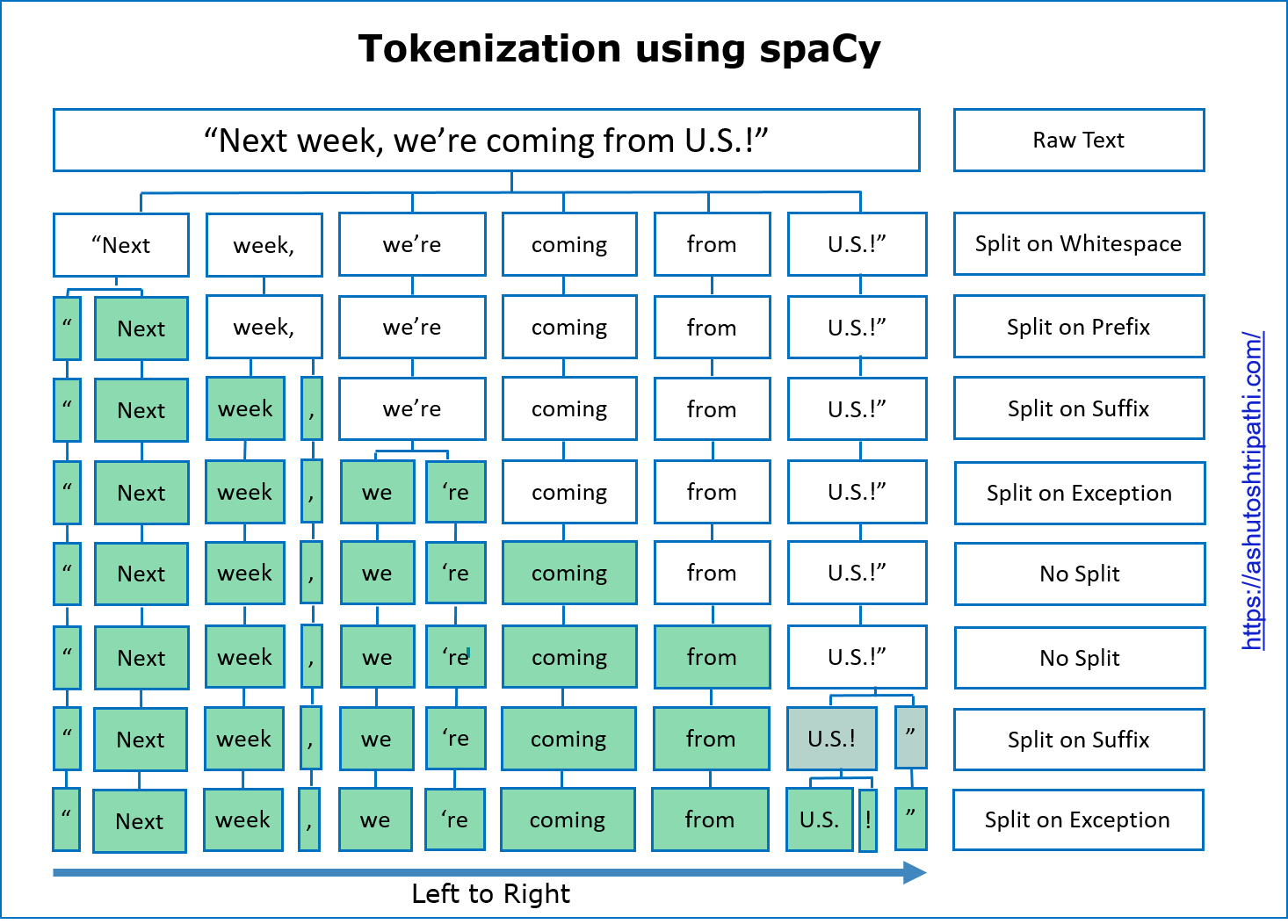
Image Source: https://ashutoshtripathi.com/2020/04/06/guide-to-tokenization-lemmatization-stop-words-and-phrase-matching-using-spacy/
still, if you have confusion, the below picture clarifies the process, so in this process, we are making our Chatbot rather than giving more information; we are making Chatbot understand more intelligently,
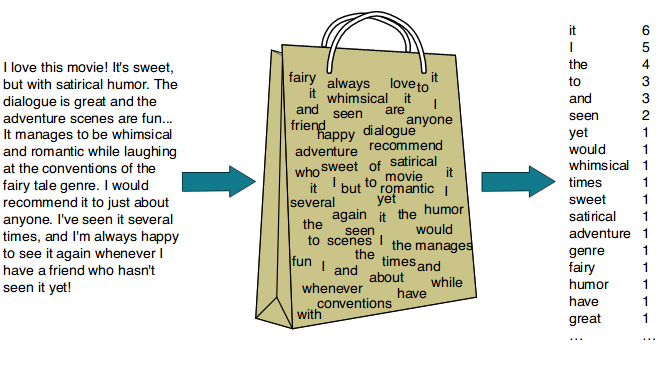
Bag of Words (BoW), so after converting a sentence to words, we go for the steaming process. This particular BoW converts words to numbers by vector embeddings. It simply means how many times a specific word or words got repeated and they put it in hierarchy mode as like shown below,
One hot encoding is the final one in the chatbot process. Here all the categorical variables are converted into a form (vector to numbers/machine level) that machine learning uses to process further.

Python Implementation of Chatbot
#importing libraries import numpy as np #numerical computations import nltk #natural language processing library import string #strings purpose import random
#reading corpus
#https://www.tango-learning.com/post/programming-a-complicated-world-with-a-simple-understanding
f = open('program.txt','r',errors = 'ignore')
raw_doc = f.read()
raw_doc = raw_doc.lower()
nltk.download('punkt')
nltk.download('wordnet')
sent_tokens = nltk.sent_tokenize(raw_doc)
word_tokens = nltk.word_tokenize(raw_doc)
#sentence tokens sample
sent_tokens[:5]

#word tokens sample word_tokens[:5]

#preprocessing - text
lemmer = nltk.stem.WordNetLemmatizer()
def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punch_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punch_dict)))
#greetings
greet_inputs = ("hey", "hello", "welcome", "vanakkam")
greet_responses = ["vanakkam", "nandrigal", "thanks for the words", "hey thanks man"]
def greet(sentence):
for word in sentence.split():
if word.lower() in greet_inputs:
return random.choice(greet_responses)
#response genearation
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def response(user_response):
robo1_response = ''
TfidVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english')
tfidf = TfidVec.fit_transformer(sent_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat=vals.flatten()
flat.sort()
req_tfidf = float
if(req_tfidf==0):
robo1_response=robo1_response+"I am sorry! I cant understand the query"
return robo1_response
else:
robo1_response = robo1_response+sent_tokens[idx]
return robo1_response
#conversation
flag = True
print("BOT: My name is Premanand. Let's start our conversation!")
while(flag==True):
user_response=input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='nandrigal'):
flag = False
print("BOT: Hey thanks for the conversation.. Anything else?")
else:
if(greet(user_response)!=None):
print("BOT:" +greet(user_response))
else:
sent_tokens.append(user_response)
word_tokens=word_tokens+nltk.word_tokenize(user_response)
final_words=list(set(word_tokens))
print("BOT:", end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("BOT: Have a nice day! It's nice talking to you!")

Conclusion
Hence, from this article, we can get some ideas about what a chatbot is, some history behind it and its types, and then the Chatbot’s architecture. Added, we came across how a chatbot works at each step, and we have seen with layman understanding how a chatbot works with each step from a sentence to the one-hot encoding process. Please leave your thoughts/opinions in the comments area below. Learning from your mistakes is my favorite quote; if you find something incorrect, highlight it; I am eager to learn from learners like you.
Read more articles about chatbots on our blog.
About me, in short, I am Premanand. S, Assistant Professor Jr and a researcher in Data Science.
Technical Hobbies: Learning Python, Machine Learning, and Deep Learning
mail ID: er.anandprem@gmail.com
Linkedin link: https://www.linkedin.com/in/premsanand/
My website: https://www.tango-learning.com
My GitHub: https://github.com/anandprems
Happy Knowledge Sharing and happy learning!
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Premanand S is a dedicated academic with over a decade of research experience specializing in Bio-signal Processing, Machine Learning, and Deep Learning. He earned his B.Tech in 2009 from Amrita Vishwa Vidyapeetham, Bangalore, and completed his M.E. in 2011 from Rajalakshmi Engineering College, Chennai, where his thesis focused on Deep Learning for ECG Signal Processing.
Currently pursuing his Ph.D. at VIT-Chennai, his research, titled "Deep Learning Approaches for Enhanced ECG Signal Processing and Arrhythmia Classification," aims to leverage cutting-edge deep learning techniques to improve the accuracy and efficiency of ECG signal analysis, contributing significantly to advancements in cardiac health monitoring.
A recipient of the prestigious TCS-RSP (Research Scholarship) in 2014, Cycle 9, Premanand has established himself as a recognized figure in the academic community. He has been invited to deliver talks on Data Science, Machine Learning, and Deep Learning at prominent institutions across India, sharing his expertise and insights with researchers and students alike.
As an Assistant Professor at VIT-Chennai, he continues to mentor and inspire the next generation of researchers while pushing the boundaries of knowledge in his field.






