This article was published as a part of the Data Science Blogathon.
Introduction
The global market for the usage of Recommendation Engine was valued at USD 2.69 billion in 2021. It is anticipated to surpass USD 15.10 billion by 2026, reporting a CAGR of 37.79% during 2022-2026.
The recommendations that companies give you sometimes use data analysis techniques to identify items that match your taste and preferences. With the rapidly growing data over the internet, it is no surprise to say that Netflix knows which movie you’re going to want to watch next or the top news article you would like to read on your Twitter.
With the recent advances in Artificial Intelligence and the rising competition among multiple enterprises, it is essential to search, map, and provide the users with the relevant chunk of data to improve consumer experience and increase the trend of digitalization.
With that being said, in today’s guide, we will discuss Recommendation engines, their importance, challenges faced, working principles, different techniques, applications, and top companies using them, and lastly, how to build your own recommendation engine in Python.
Table-Of-Contents
- What is Recommendation Engines?
- Why Are Recommendation Engines Important In Machine Learning?
- Different Techniques Of Recommender Engines
- Working Of Recommendation Engines
- Challenges Of Recommendation Engines
- How To Build A Recommendation Engine
- Applications & Top Companies Using Recommendation Engines
- Conclusion

What is a Recommendation Engine?
A recommendation engine is a data filtering system that operates on different machine learning algorithms to recommend products, services, and information to users based on data analysis. It works on the principle of finding patterns in customer behavior data employing a variety of factors such as customer preferences, past transaction history, attributes, or situational context.
The data used for finding insights can be collected implicitly or explicitly. Companies usually use petabytes of data for their recommendation engines to present their views with their experiences, behaviors, preferences, and interests.
In this ever-evolving market of information density and product overload, each company uses recommendations engines for slightly different purposes. Still, all have the same goal of driving more sales, boosting customer engagement and retention, and providing consumers with a piece of personalized knowledge and solutions.
Why are Recommendation Engines important in ML?
There is no doubt that recommendation engines are an extraordinary way to enhance user experience, stimulate demand, boost revenue, increase click-through rates (CTRs), actively engage users, and other crucial metrics. As powerful data filtering tools, recommendation engines work in real-time. They can be beneficial when there is a demand to give users personalized suggestions and advice.
Let us take Netflix as an example.
There are thousands of movies and multiple categories of shows to watch from. Still, Netflix offers you a much more opinionated selection of movies ad shows you are most likely to enjoy. With this strategy, Netflix achieves lower cancellation rates, saves a billion dollars a year, saves your time, and delivers a better user experience.
This is why recommendations engines are essential and exactly how many businesses are boosting engagement opportunities with their products by offering a more significant influx of cross-selling opportunities.
Different Techniques of Recommendation Engines
There are three different types of recommender engines known in machine learning, and they are:
1. Collaborative Filtering
The collaborative filtering method collects and analyzes data on user behavior, online activities, and preferences to predict what they will like based on the similarity with other users. It uses a matrix-style formula to plot and calculates these similarities.
Advantage
One significant advantage of collaborative filtering is that it doesn’t need to analyze or understand the object (products, films, books) to recommend complex items precisely. There is no dependence on analyzable machine content, which means it chooses recommendations based on what it knows about the user.
Example
If user X likes Book A, Book B, and Book C while user Y likes Book A, Book B, and Book D, they have similar interests. So, it is favorably possible that user X would select Book D and user Y would enjoy reading Bood C. This is how collaborative filtering happens.
2. Content-Based Filtering
Content-based filtering works on the principle of describing a product and a profile of the user’s desired choices. It assumes that you will also like this other item if you like a particular item. Products are defined using keywords (genre, product type, color, word length) to make recommendations. A user profile is created to describe the kind of item this user enjoys. Then the algorithm evaluates the similarity of items using cosine and Euclidean distances.
Advantage
One significant advantage of this recommender engine technique is that it does not need any additional data about other users since the recommendations are specific to this user. Also, this model can capture the particular interests of a user and suggest niche objects that very few other users are interested in.
Example
Suppose a user X likes to watch action movies like Spider-man. In that case, this recommender engine technique only recommends movies of the action genre or films describing Tom Holland.
3. Hybrid Model
In hybrid recommendation systems, both the meta (collaborative) data and the transactional (content-based) data are used simultaneously to suggest a broader range of items to the users. In this technique, natural language processing tags can be allocated for each object (movie, song), and vector equations calculate the similarity. A collaborative filtering matrix can then suggest things to users, depending on their behaviors, actions, and intentions.
Advantages
This recommendation system is up-and-coming and is said to outperform both of the above methods in terms of accuracy.
Example
Netflix uses a hybrid recommendation engine. It makes recommendations by analyzing the user’s interests (collaborative) and recommending such shows/movies that share similar attributes with those rated highly by the user(content-based).
Working Of Recommendation Engines
Data is the most vital element in constructing a recommendation engine. It is the building block from which patterns are derived by algorithms. The more details it has, the more accurately and practically it will deliver appropriate revenue-generating recommendations. Basically, a recommendation engine works using a combination of data and machine learning algorithms in four phases. Let’s understand them in detail now:
1. Data Collection
The first and most crucial step for creating a recommendation engine is gathering the appropriate data for every user. There are two types of data, i.e., Explicit data that contains information collected from user inputs such as ratings, reviews, likes, dislikes, or comments on products.
In contrast, we have Implicit data that contains information gathered from user activities such as web search history, clicks, cart actions, search log, and order history.
Each user’s data profile will become more distinctive over time; hence it is also crucial to collect customer attribute data such as:
- demographics (age, gender)
- Psychographics (interests, values) to identify similar customers
- feature data (genre, object type) to determine similar products likeness.
2. Data Storage
Once you have collected the data, the next step is to store the data efficiently. As you collect more data, ample, scalable storage must be available. Several storage options are available depending on the type of data you collect, like NoSQL, a standard SQL database, MongoDB, and AWS.
When choosing the best storage options, one should consider some factors: ease of implementation, data storage size, integration, and portability.
3. Analyze The Data
After collecting the data, you need to analyze the data. The data must then be drilled and analyzed to offer immediate recommendations. The most prevalent methods in which you can analyze data are:
- Real-time Analysis, in which the system uses tools that evaluates and analyzes events as it is created. This technique is mainly implemented when we want to provide instant recommendations.
- Batch Analysis, in which processing and analyzing of data are done periodically. This technique is mainly implemented when we want to send emails with recommendations.
- Near-real-time Analysis, in which you analyze and process data in minutes instead of seconds as you don’t need it immediately. This technique is mainly implemented when we provide recommendations while the user is still on the site.
4. Filtering The Data
Once you analyze the data, the final step is to accurately filter the data to provide valuable recommendations. Different matrixes, mathematical rules, and formulas are applied to the data to provide the right suggestion. You must choose the appropriate algorithm, and the outcome of this filtering is the recommendations.
Challenges of Recommendation Engines
Perfection simply doesn’t exist. An English Theoretical Physicist “Stephen Hawking,” once said:
“One of the basic rules of the universe is that nothing is perfect.”
Similarly, there are some challenges companies have to overcome to build an effective recommender system. Here are some of them:
1. The COLD START Problem
This problem arises when a new user joins the system or adds new items to the record. The recommender system cannot initially suggest this new item or user because it does not have any rating or reviews. Hence, it gets challenging for the engine to predict the preference or priorities of the new user, or the rating of the new items, leading to less precise recommendations.
For instance, a new movie on Netflix cannot be recommended until it gets some views and ratings.
However, a deep learning-based model can solve the cold start problem because these models do not heavily depend on user behavior to make predictions. It can optimize the correlations between the user and the item by examining product context and user details like product descriptions, images, and user behaviors.
2. Data Sparsity Problem
As we all know, recommendation engines hugely depend upon the data. Under a few situations, some users do not give ratings or reviews of the items they purchased. If we do not have high-quality data, the rating model becomes very sparse, leading to data sparsity problems.
This problem makes it challenging for the algorithm to find users with similar ratings or interests.
To ensure the best quality data and to be able to make the most of the recommendation engine, ask yourself four questions:
- How recent is the data?
- How noisy is the information?
- How diverse is the information?
- How quickly can you feed new data to your recommender system model?
The above questions will ensure that your business meets the complex data analytics requirements.
3. Changing User Preferences Problem
User-item interactions in rating and reviews can generate massive changing data.
For instance, I might be on Netflix today to watch a Romantic movie with my girlfriend. But tomorrow, I might have a different mood, and a classic psychological thriller is what I would like to watch.
On the issue of user preferences, recommender engines may wrongly label users, which will interpret results on large datasets inefficiently. Hence, scalability is a big challenge for these datasets, and some advanced large-scaled methods are needed to address this issue.
How to Build a Recommendation Engine in Python?
This guide section will help you build basic recommendation systems in Python. We will focus on building a basic recommendation system by recommending items that are most comparable to a specific item, in our case, movies. Keep in mind, this is not an exact, robust recommendation engine. It just suggests what movies/items are most similar to your movie preference.
You can find the code and data files at the end of this section. So let’s get started:
Note: It is highly suggested to operate on google collab or jupyter notebook for running this code.
#1. Import the required libraries.
Import numpy and pandas machine learning libraries, as we will use them for data frames and evaluating correlations.
Code
import numpy as np import pandas as pd
#2. Get the Data
Define the column names, read the csv file for the movies and reviews dataset and print the first 5 rows.
Code
column_names = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv('u.data', sep='t', names=column_names)
df.head()
Output
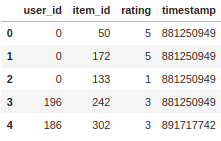
As you can see above, we have four columns: user id, which is unique to each user. Item id is unique to each movie, ratings of the film, and their timestamp.
Now let’s get the movie titles:
Code
movie_titles = pd.read_csv("Movie_Id_Titles")
movie_titles.head()
Output
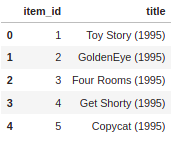
Read the data using the pandas’ library and print the top 5 rows from the dataset. We have the id and title for each film.
We can now join the two columns:
Code
df = pd.merge(df,movie_titles,on='item_id') df.head()
Output
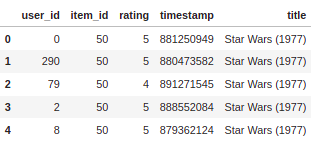
We now have the combined dataframe, which we will use next for Exploratory Data Analysis (EDA).
#3. Exploratory Data Analysis
Let’s examine the data a bit and get a peek at some of the best-rated films.
Visualization imports will be our first step in EDA.
Code
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('white')
%matplotlib inline
Next, we will create a rating dataframe with average rating and number of ratings as our two columns:
Code
df.groupby('title')['rating'].mean().sort_values(ascending=False).head()
Output

Code
df.groupby('title')['rating'].count().sort_values(ascending=False).head()
Output

Code
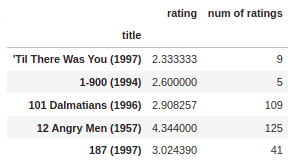
ratings = pd.DataFrame(df.groupby('title')['rating'].mean())
ratings.head()
Output
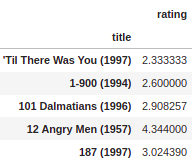
Next, set the number of rating columns right next to mean ratings:
Code
ratings['num of ratings'] = pd.DataFrame(df.groupby('title')['rating'].count())
ratings.head()
Output
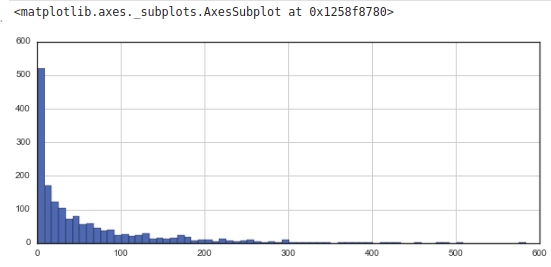
Plot a few histograms to check several ratings visually:
Code
plt.figure(figsize=(10,4)) ratings['num of ratings'].hist(bins=70)
Output
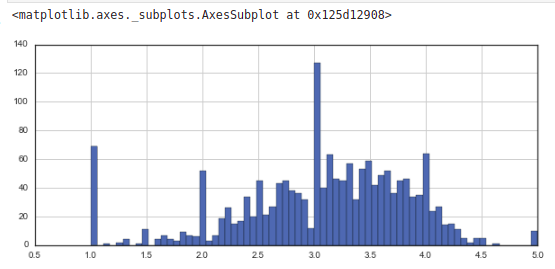
Code
plt.figure(figsize=(10,4)) ratings['rating'].hist(bins=70)
Output
Code
sns.jointplot(x='rating',y='num of ratings',data=ratings,alpha=0.5)
Output
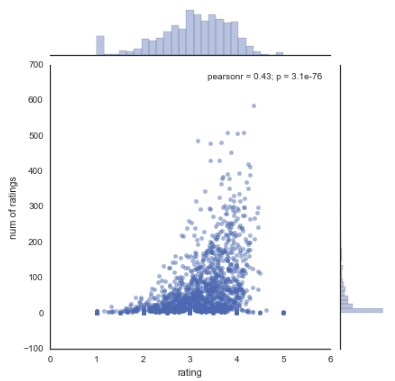
Okay! Now that we have a comprehensive view of what the data looks like, let’s move on to constructing a simple recommendation system in Python:
#4. Recommending Similar Movies
Now let’s construct a matrix with the user IDs and the movie title. Each cell will then consist of the user’s rating of that movie.
Note: There will be many NaN values because most people have not seen most of the film.
Code
moviemat = df.pivot_table(index='user_id',columns='title',values='rating') moviemat.head()
Output
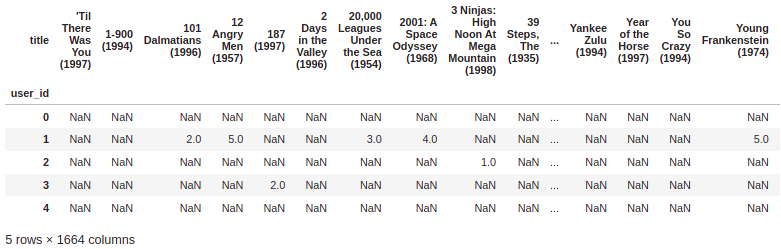
Print the most rated films:
Code
ratings.sort_values('num of ratings',ascending=False).head(10)
Output
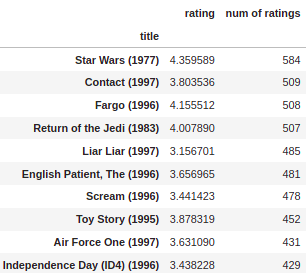
Let’s pick two movies: Star Wars, a science fiction movie. And the other is Liar Liar, which is a comedy. The next step is to grab the user ratings for those two movies:
Code
starwars_user_ratings = moviemat['Star Wars (1977)'] liarliar_user_ratings = moviemat['Liar Liar (1997)'] starwars_user_ratings.head()
Output
We can then use the corrwith() method to get correlations between two pandas series:
Code
similar_to_starwars = moviemat.corrwith(starwars_user_ratings) similar_to_liarliar = moviemat.corrwith(liarliar_user_ratings)
Output

There are still many null values that can be cleaned by removing NaN values. So we use a DataFrame instead of a series:
Code
corr_starwars = pd.DataFrame(similar_to_starwars,columns=['Correlation']) corr_starwars.dropna(inplace=True) corr_starwars.head()
Output
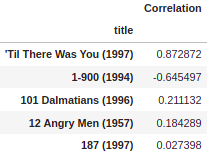
Now, suppose we sort the dataframe by correlation. In that case, we should get the most comparable films, however, note that we get a few movies that don’t really make sense.
This is because there are a lot of films only watched once by users who also watched star wars.
Code
corr_starwars.sort_values('Correlation',ascending=False).head(10)
Output
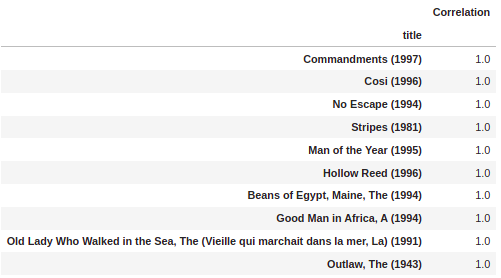
We can fix this by filtering films out with less than 100 reviews. We can determine this value based on the histogram we plotted in the EDA section earlier.
Code
corr_starwars = corr_starwars.join(ratings['num of ratings']) corr_starwars.head()
Output
Now sort the values and witness how the titles make a lot more understanding:
Code
corr_starwars[corr_starwars['num of ratings']>100].sort_values('Correlation',ascending=False).head()
Output
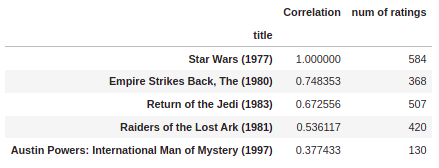
Now the same proceeds for the comedy Liar Liar movie:
Code
corr_liarliar = pd.DataFrame(similar_to_liarliar,columns=['Correlation'])
corr_liarliar.dropna(inplace=True)
corr_liarliar = corr_liarliar.join(ratings['num of ratings'])
corr_liarliar[corr_liarliar['num of ratings']>100].sort_values('Correlation',ascending=False).head()
Output
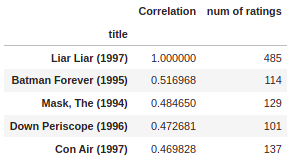
Great Job, you have made a movies recommendation engine of your own.
Note: Access the google notebook here.
Applications & Top Companies using Recommendation Engines
Many industries employ recommendation engines to boost user interaction and enhance shopping prospects. As we all saw, recommendation engines can change the way businesses communicate with users and maximize their return-on-investment (ROI) based on the information they can gather.
We will see how almost every business uses a recommendation engine to stand a chance to profit.
1. E-Commerce
E-commerce is an industry where recommendation engines were first widely employed. E-commerce businesses are best suited to provide accurate recommendations with millions of customers and data on their online database.
2. Retail
Shopping data is the most valuable information for a machine learning algorithm. It is the most precise data point on a user’s intent. Retailers with troves of shopping data are at the forefront of enterprises generating concrete recommendations for their customers.
3. Media
Like e-commerce, media companies are the first to hop onto the recommendations engines techniques. It is hard to notice a news site without a recommendation engine at play.
4. Banking
Banking is a mass-market industry utilized digitally by millions of people and is prime for recommendations. Understanding a customer’s exact financial situation and past choices, correlated with data of thousands of comparable users, is quite decisive.
5. Telecom
This industry shares similar dynamics with the banking industry. Telcos have the credentials of millions of customers whose every action is documented. Their product range is also moderately narrow compared to other sectors, making recommendations in telecom a more manageable solution.
6. Utilities
Similar dynamics with telecom, but utilities have an even more limited scope of products, making recommendations relatively easy to use.
Top Companies Using Recommendation Engines Include
- Amazon
- Netflix
- Spotify
- YouTube
- TikTok
- Tinder
- Quora
- Yahoo
Final Thoughts
Recommendation engines are a powerful marketing tool that will help you better up-sell, cross-sell, and boost your business. Many things are going on in the field of recommendation engines. Every company has to keep up to date with the technology to provide the best satisfaction set of recommendations to all their users.
Here we reach the end of this guide. I hope all the topics and explanations are helpful enough to assist you in starting your journey in the recommendation engines in machine learning.
Read more articles on our blog about Recommendation Engines.
If you still have any doubt, reach out to me on my social media profiles, and I will be happy to help you out. You can read more about me below:
About Author
I am a Data Scientist with a Bachelors’s degree in computer science specializing in Machine Learning, Artificial Intelligence, and Computer Vision. Mrinal is also a freelance blogger, author, and geek with five years of experience in his work. With a background working through most areas of computer science, I am currently pursuing Masters in Applied Computing with a specialization in AI from the University of Windsor, and I am a Freelance content writer and content analyst.
Read More On Recommender Engines By Mrinal Walia:
1. Top 5 Open-Source Machine Learning Recommender System Projects With Resources
2. Must-Try Open-Source Deep Learning Projects for Computer Science Students
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus





