This article was published as a part of the Data Science Blogathon.
Introduction
A Machine Learning solution to an unambiguously defined business problem is developed by a Data Scientist ot ML Engineer. The Model development process undergoes multiple iterations and finally, a model which has acceptable performance metrics on test data is taken to the production environment. Taking the final chosen model reaching it out to the users is called deployment and there are a few options available to deploy a model. Kubernetes(also called k8s) is one of the open-source tools used for deploying our applications. K8s used in conjunction with services provided by cloud service providers like AWS, Google, Microsoft, etc can be used for deploying ML models It is known that companies like Netflix, Spotify, and Adidas use this option for deploying their applications. In this blog, which is pitched at an introductory level, we will have a look at how to use containerize the ML application and use the Kubernetes service to deploy on our local machine.
Docker Container and Kubernetes
A Docker is a software tool that helps in building, deploying our applications efficiently. Let’s Image a scenario where we are trying to host applications on our server. These applications have been developed by three different developers using three versions of python. In this kind of situation, we can use Docker as it provides three isolated environments enclosing the application and its dependencies. Docker containers are similar to the ones used in the shipping industry for transporting goods, where it provides an isolated environment for the goods being transported. In connection with Docker, a Docker Image is a read-only file that contains our application along with the dependencies (like a blueprint) and a Docker container is a running image (we can run a number of containers using one image)
After getting a glimpse of what is Docker, let’s try and understand what is Kubernetes. Kubernetes is an open-source software tool that can be used to manage containerized applications without manual intervention. Kubernetes process is similar to how a music orchestra is conducted. We can think of the musical instruments in an orchestra as a number of containers operating concurrently and say that Kubernetes has a file that contains detailed instructions of containers being used and how they work and interact with each other. So Kubernetes automates the entire process of running containers without a dedicated team monitoring the operations.
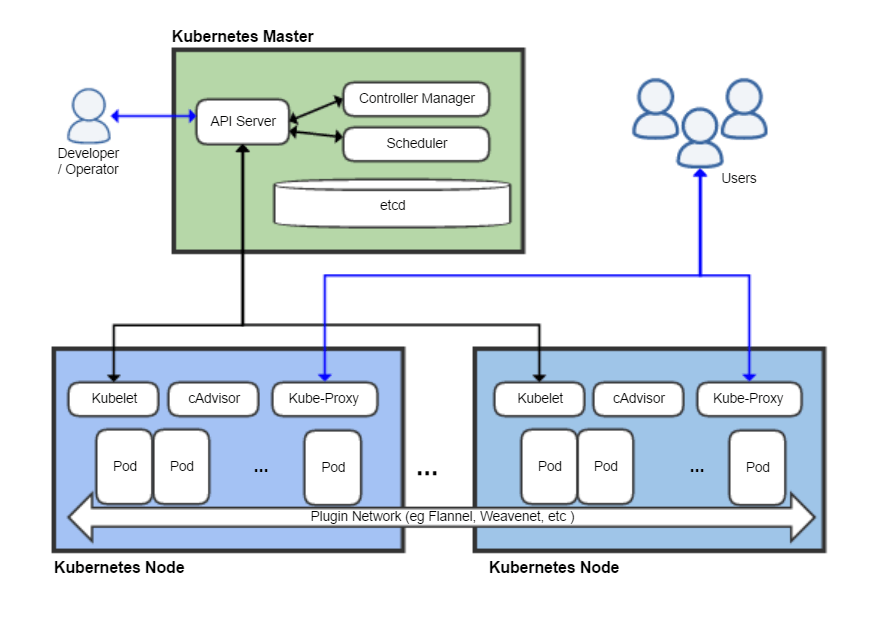
Image Source: https://www.instana.com/
It would not be possible to elaborately address the details of Kubernetes architecture and functioning in this blog, but a large number of resources are available which can provide rich content. However, to understand the overall process of deployment, we will touch upon brief areas. A Kubernetes system with a full set of Kubernetes components is called a cluster, which can run on a physical machine or a Virtual Machine(VM).
The simplified architecture of k8s consists of a control plane and nodes (also called compute machines). The Nodes (there can be more than one node in a cluster) are capable of running on a physical machine or VM. The Nodes also contain pods which are kind of wrap around the containers. The Control Plane is responsible for controlling the cluster components and also houses an object our interest, called API server. The API server is the front end (gateway) of the control plane and we can access pods, services, nodes etc through the API server. In this article we will use Kubectl as the tool to perform operations on the Kubernetes cluster.
Image Source. https://dockerlabs.collabnix.com/
The Problem At Hand
The scope of work in the present case is to develop a solution to predict a student will get placed in a campus recruitment program. The placement of a student depends on various factors like their performance in school and colleges, work experience, etc. It includes secondary and higher secondary school percentages and specialization.
In the current case for the sake of simplicity, we will deploy a single container on k8s for our implementation part. The main focus area of this blog is on K8s and spending time on the initial steps in the overall development process will dilute the content and make this a long text. The readers are free to browse through my GitHub repo (placed at reference) containing the code to look at the initial development phase. I have used a mac machine to demonstrate the deployment and depending on the type of machine you are using for development and deployment, there may be slight changes to the code and in case of difficulty, I would recommend seeking help from the online community like stackoverflow.com etc.
The sequence of initial activities are as follows:-
(a) Develop an ML model to predict whether a candidate with given attributes will be placed in campus recruitment or not. The developed model (Random Forest) had an accuracy of 96 % on the test set. I have used Dictvectorizer() for encoding categorical features and at the end of the model building, I created binary forms of model and encoding using pickle library as the output of Jupyter Notebook.
(b) In the next step, created a virtual project environment in vs code using pipenv and created a predict.py which uses flask framework and binary file with dictvectorizer and model to create an API for the user to interact with the model and pass features of a candidate for prediction. The required libraries like scikit-learn, numpy, flask etc were installed in a virtual environment using pipenev, and the resultant files Pipfile and Pipfile.lock holds the details of dependencies for the project. The flask app was tested locally using a test file predict-test.py , which has the sample features for testing the application. I have used gunicorn as WSGI server and in case you are using a Windows machine, you may have to switch to an alternate option like waitress.
(c) Using the above files, a Dockerfile with a python base image was created for preparing the Docker image and running a container from it. The Docker image was pushed as a public repository on https://hub.docker.com/.
Deployment Walkthrough
The Docker image from https://hub.docker.com/ forms the starting point of this demonstration of deployment and you can commence the deployment from this point onwards. The pre-requisite for starting this exercise is the installation of Docker-Desktop. Once Docker-Desktop is installed, enable Kubernetes in the settings. At the start, check Docker installation by using the command docker –version. start by pulling the image from the https://hub.docker.com/.
$ docker pull subbu0319/placement-app
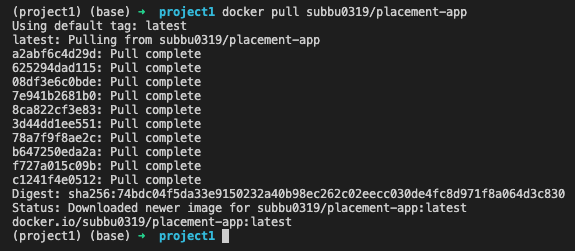
Once the image is pulled , check for images on local machine.
$ docker images

we will change the tag of placement-app image, giving tag v1 to the image (default is latest)
$ docker image tag placement-app:latest placement-app:v1
Run a docker container using above image
$ docker run -it –rm -p 9696:9696 placement-app:v1
Using an editor like vs-code create a python script predict-test.py which contains sample features being used for prediction.
#predict-test.py import requests candidate = [{"gender": "M",
"ssc_p": 71.0,
"ssc_b": 'Central',
"hsc_p": 58.66,
"hsc_b": 'Central',
"hsc_s": 'Science',
"degree_p": 58.0,
"degree_t": 'Sci&Tech',
"etest_p": 56.0,
"mba_p": 61.3,
"specialisation": 'Mkt&Fin',
"workex": 'Yes',
}]
url = "http://localhost:9696/predict"
print(f'Candidate features have been evaluated and output is {requests.post(url=url,json=candidate).json()}')
|
Once we get the confirmation that the container is running fine, open another terminal and run the python script predict-test.py using the command
$ python predict-test.py

If we see the output like above, we can see that the container is running fine in the local environment. The model has predicted that for the given candidate, the probability of placement is around 90%. Now we will use, Kubernetes to deploy the container in a local environment. We will use minikube to run our k8s cluster and kubectl to interact with the cluster and run our commands.
Minikube is a utility that can be used to run Kubernetes on our local machine. It creates a single node cluster contained in a Virtual Machine(VM). This kind of setup helps to demonstrate k8s operations without spending time and resource-consuming of entire k8s. The resources for the installation of minikube and kubectl are provided in the reference section below. Post-installation, the minikube can be started with command,
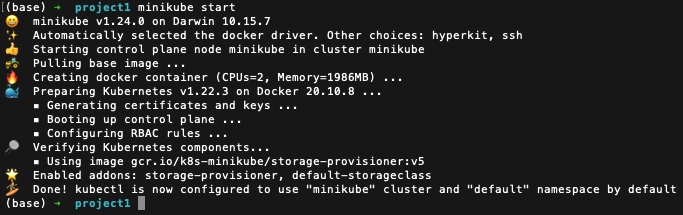
Check status of minilube,
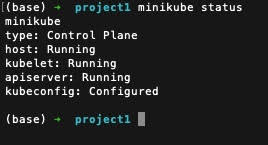
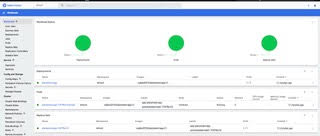
As we see that minikube is up and running, we can check the status of the cluster and components.

The cluster is running but components are yet to be created. Now we will go ahead and create our deployment with pods and an associated service component using respective yaml files. You can check out the contents of deployment.yaml and service.yaml from my GitHub repository and create a copy on the local machine.


Now, we can check the status of cluster components again to confirm all are up and running.
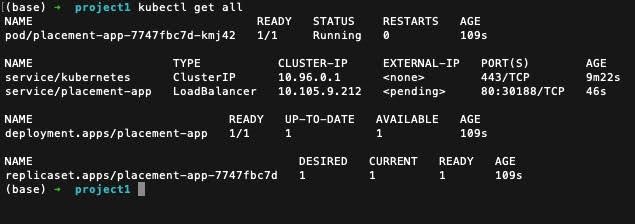
As the pods and service are running, we can access the service to check whether our application is running on the cluster using the following minikube command.
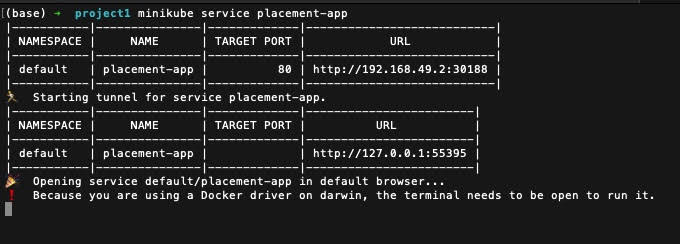
Open a separate terminal and run the python script, predict-test.py. Use the URL http://127.0.0.1:55395/9696 in the python script.

We can see the ML application has been deployed successfully on the kubernetes . We can also view the minikube dashboard using the command,
$ minikube dashboard
Once we have completed our deployment, we can delete the deployment and service using the commands kubectl delete svc and kubectl delete deployment . Then we can stop minikube and delete the local cluster using the commands minikube stop and minikube delete.
Deploying the k8s on a local machine will not ensure that the ML application is accessible to the end-user irrespective of geographic location. EKS(Elastic Kubernetes Service), Azure Kubernetes Service (AKS) and Google Kubernetes Engine (GKE) are the popular k8s service platform provided by AWS, Azure and Google respectively which can be used for cloud deployment. I hope to pursue the deployment of k8s on the cloud in another article.
Conclusion
This article is an attempt to introduce the deployment of a containerized ML application using Kubernetes. The use case was a simple container application with minimum complexity and was deployed using a single cluster on the local machine. As a part of further effort, the readers are advised to pursue further reading on deploying multiple containers on k8s and deploying the k8s using a cloud service like AWS, Azure or GCP.
Read more articles on machine learning on our website.
References
1. https://www.docker.com/products/docker-desktop (for installation of Docker-Desktop)
2. https://www.freecodecamp.org/news/docker-simplified-96639a35ff36/
3. https://avinetworks.com/glossary/kubernetes-architecture/
4. https://minikube.sigs.k8s.io/docs/start/ (for installation of minikube)
5. https://kubernetes.io/docs/tasks/tools/ (for installation of kubectl)
About the Author
Subramanian Hariharan is a Marine Engineer with more than 30 years of experience and is passionate about leveraging data for Business Solutions.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A Marine Engineering professional with more than 29 years experience with a passion to leverage data for business solutions. I am a post graduate In Mechanical Engineering with experiences ranging from Operations, Production, Project Management, Quality Management and Data Analytics. I have also completed Advanced Certification in Data Science from Thayer School of Engineering , University of Dartmouth. I strongly believe learning is continuous process for growth in life and sharing knowledge builds a sense of community





