This article was published as a part of the Data Science Blogathon.
Introduction
ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting.
What is shell scripting?
For Unix-like operating systems, a shell is a robust User Interface. It can run other applications and interpret commands. It is an interactive scripting language and provides access to files, utilities, and applications. You can automate tasks with the help of a shell. For exploring and dealing with files and directories, we use Linux shell commands. They can compress and archive files.
ETL Data Pipelines
An ETL workflow is meticulously developed to suit technical and end-user needs. Historically, the overall accuracy of the ETL workflow has been a higher priority than speed, although efficiency is usually a key element in reducing resource costs. We fed data through the data pipeline in smaller packets to increase efficiency. As a result, data can continue to flow through the workflow without being interrupted. If there is a residual bottleneck in the pipeline, it addressed them by parallelizing a slower process.
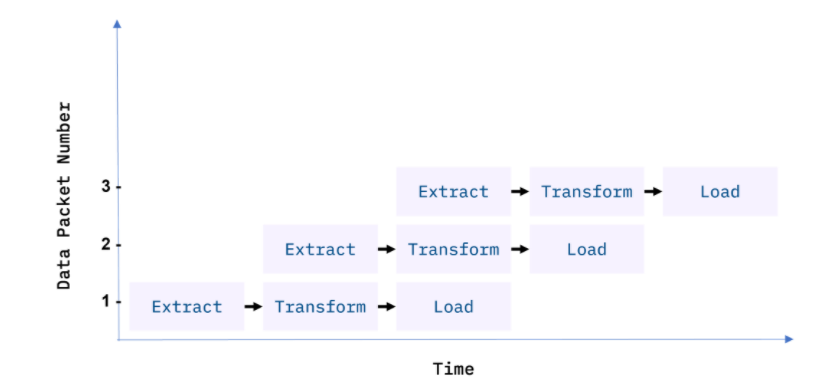
They processed data in batches in traditional ETL pipelines, usually on a repeating schedule that ranges from hours to days apart. Records collecting in an Online Transaction Processing System (OLTP) can, for example, be moved in a daily batch process to one or more Online Analytics Processing (OLAP) systems, where immense amounts of historical data can be analyzed.
1) Batch processing periods do not have to be regular and can be induced by a variety of events.
2) When the size of the source data hits a fixed threshold, or when a system detects the outcome of interest like intruder alarm, or when an outcome of interest occurs and is noticed by a system
3) Online apps like music or video streaming services provide on-demand services.
Staging Areas
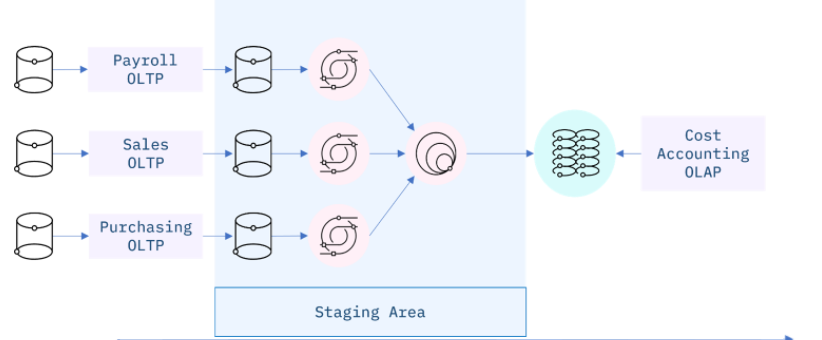
I extensively used ETL pipelines to integrate data from disconnected systems. These systems may come from a variety of vendors, regions, and firms, adding to the operational complexity. For example, a cost accounting OLAP system gathers data from several OLTP systems used by the payroll, sales, and purchasing departments.
ETL using Shell Scripting
- Extract data from a delimited file.
- Transform text data.
- Load data into a database using shell commands.
Data Extraction using Cut Command:
The filter command cut helps us extract selected characters or fields from a line of text.
Extracting characters:
The filter command cut helps us extract selected characters or fields from a line of text.
$ echo "analytics" | cut -c1-4
You should get the string ” as output.
The command below shows how to extract 5th to 8th characters.
$ echo "analytics" | cut -c5-8
You should get the string ‘ytic’ as output.
Non-contiguous characters can be extracted using the comma.
The command below shows how to extract the 1st and 5th characters.
$ echo "analytics vidhya" | cut -c1,11
You get the output: ‘av’

Extracting fields/columns from a text file:
We can extract a specific column/field from a delimited text file, by mentioning
- *) the delimiter using the -d option, or
- *) the field number using the -f option.
The /etc/passwd is a “:” delimited file.
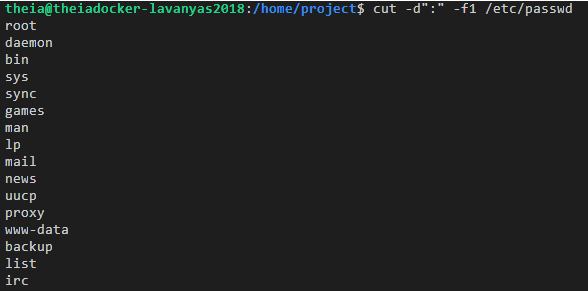
The command below extracts user names (the first field) from /etc/passwd.
$ cut -d":" -f1 /etc/passwd
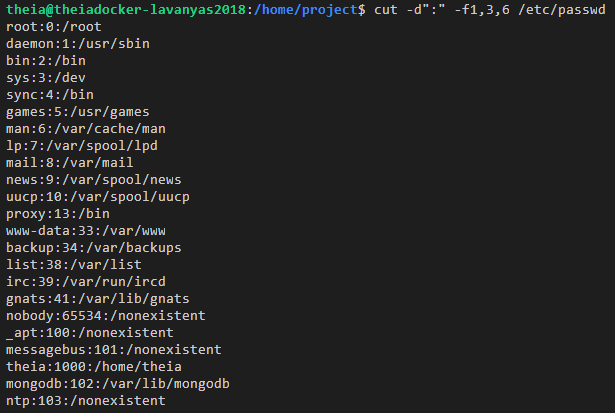
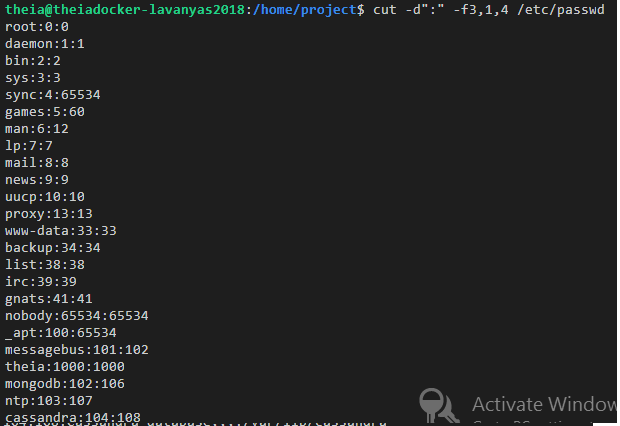
The command below extracts multiple fields 1st, 3rd, and 6th (username, userid, and home directory) from /etc/passwd.
$ cut -d":" -f1,3,6 /etc/passwd
The command below extracts the fields from 3rd to 6th (userid, groupid, user description, and home directory) from /etc/passwd.
$ cut -d":" -f3-6 /etc/passwd
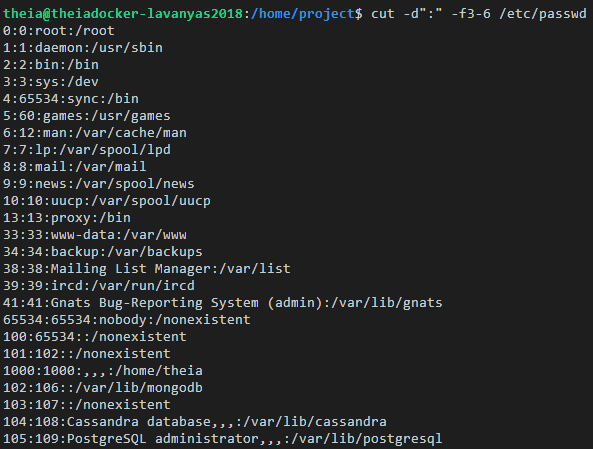
$ cut -d":" -f3,1,4 /etc/passwd
This command retrieves the third, first, and fourth rows.
Transforming Data using tr
Translate from one character set to another
tr is a filter command used to translate, squeeze, and/or delete characters.
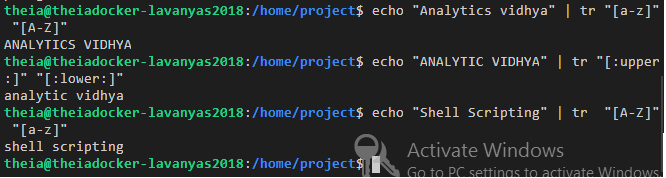
The command below translates all lowercase to uppercase alphabets.
$ echo "Analytics Vidhya" | tr "[a-z]" "[A-Z]"
You could use the predefined character set for this purpose:
$ echo "ANALYTICS VIDHYA" | tr "[:upper:]" "[:lower:]"
The command below translates all uppercase to lowercase alphabets.
$ echo "Shell Scripting" | tr "[A-Z]" "[a-z]"
Squeeze repeating occurrences of characters:
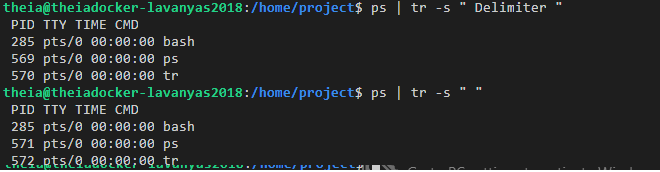
The -s option replaces a sequence of repeated characters with a single existence of that character.
The command below replaces repeat occurrences of ‘space’ in the output of the ps command with one ‘space’.
$ ps | tr -s " "
In the above example, we can replace the space character with: “[:space:]”.
Delete characters:
We can delete particular characters using the -d option.
The command below deletes all digits.
$ echo "My phone number is 5634" | tr -d "[:digit:]"

The output will be: ‘My phone number is’
Start the PostgreSQL Database
Run the following command to start the PostgreSQL database.
$ start_postgres
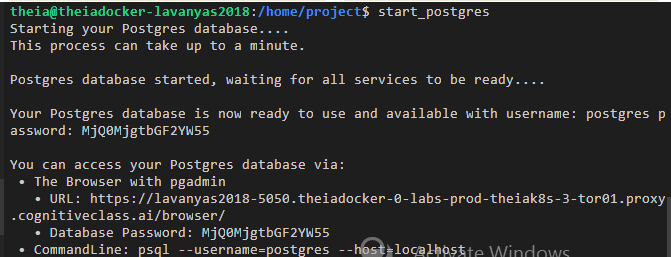
Copy the URL link to the browser and we can control and view the PostgreSQL database and schema using the PostgreSQL dashboard
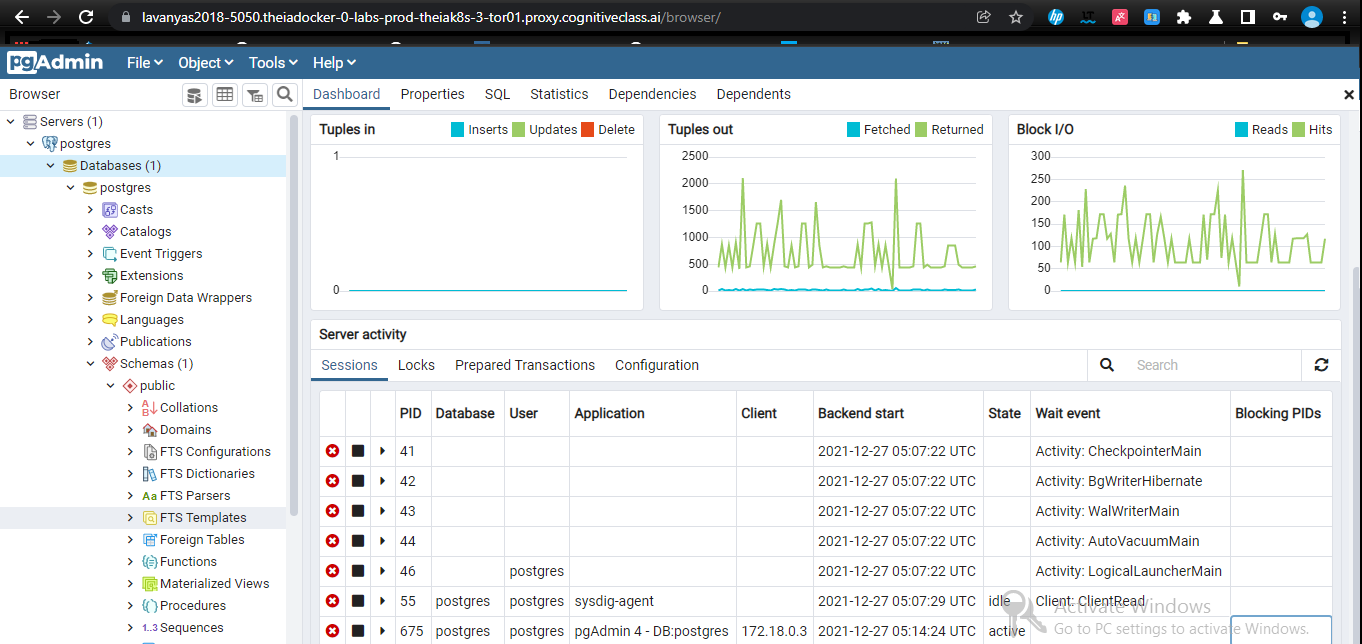
Note down the access information presented towards the end of these messages, especially the Command line:
I displayed a sample command line below:
$ psql --username=postgres --host=localhost

Running this command will start the interactive psql client which connects to the PostgreSQL server.
Now to start the database and to work with the command line,
Problem Statement
Imagine a scenario is to report the hourly average, minimum and maximum temperatures from a sensor that supplies the temperature on demand and feeds the results to a dashboard every minute. Provided the APIs that read the temperature and print the output, and load the stats to a database that is available to a reporting tool like a dashboard.
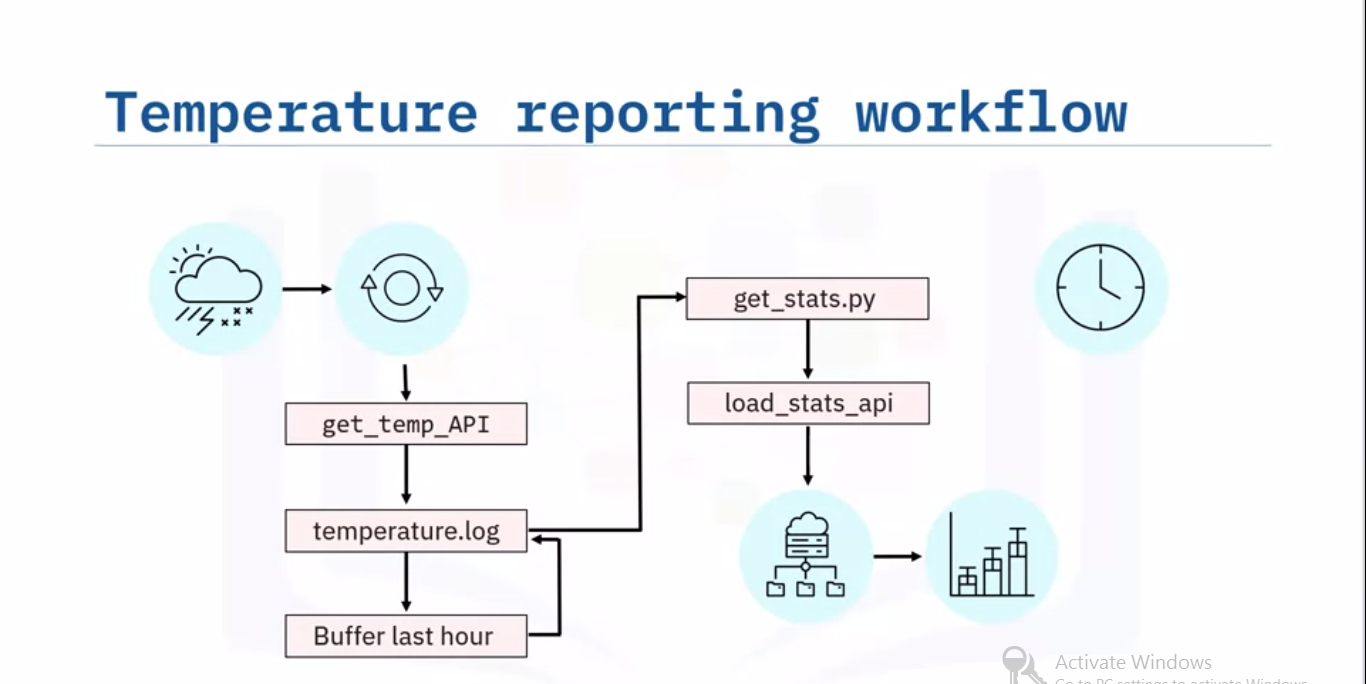
Source: IBM
Let’s sketch the workflow for your ETL pipeline, starting with the weather station and its data layer. The extraction step involves getting a current temperature reading from the sensor using the supplied ‘get_temp’ API. You can append the reading to a log file, say ‘temperature.log’. Since you will only need to keep the most recent hour of readings, buffer the last 60 readings, and then just overwrite the log file with the buffered readings.
Next, call a program, for example, a python script called ‘get_stats.py’, which calculates the temperature stats from the 60-minute log, and loads the resulting stats into the reporting system using the load_stats API. The stats can then display a live chart showing the hourly min, max, and average temperatures. If we want to schedule the workflow to run every minute.
Start by creating a shell scripting called ‘temperature_access_log_ETL.sh’.
$ touch temperature_access_log_ETL.sh
Next open the file with a text editor, such as ‘gedit’ or ‘nano’.
$ gedit temperature_access_log_ETL.sh
In the editor, type in the Bash shebang to turn your file into a Bash shell scripting. Now you can add the following comments to sketch your tasks:
1) Extract a temperature reading from the sensor using the supplied ‘get_temp’ API.
2) Append the reading to a log file, say ‘temperature.log’.
3) You only need to keep the most recent hour of readings, so buffer the last 60 readings.
Call a program, say a python script called ‘get_stats.py’, which calculates the temperature stats from the 60-minute log, and load the resulting stats into the reporting system using the supplied API.
After completion of the ETL bash script, you will need to schedule it to run every minute. Now you can fill in some details for comments. Start by initializing your temperature log file on the command line with the touch command.
$ touch temperature.log
In the text editor, enter a command to call the API to read a temperature, and append the reading to the temperature log. Now, just keep the log file, by overwriting the temperature log with its last lines of code. This completes the data extraction step.
Transformation Phase:
Suppose you have written a Python script, called ‘get_stats.py,’ which reads temperatures from a log file calculates the temperature stats, and writes the result to an output file so that the input and output filenames are command-line arguments.
You can add the following line to your ETL script, which calls ‘python3’ and invokes your Python script ‘get_stats.py,’ using the readings in ‘temperature.log,’ and writes the temperature stats to a CSV file called ‘temp_stats.csv.’
$ python get_stat.py temperature.log temp_stat.csv
This completes the transformation phase of your ETL script.
Load Phase:
Finally, you can load the resulting stats into the reporting system using the supplied API. It provokes by calling the API and the temperature temp_stat.csv in a command-line argument. Next, don’t forget to set permissions to make your shell scripting executable.
Now it’s time to schedule your ETL job. Open the crontab editor.
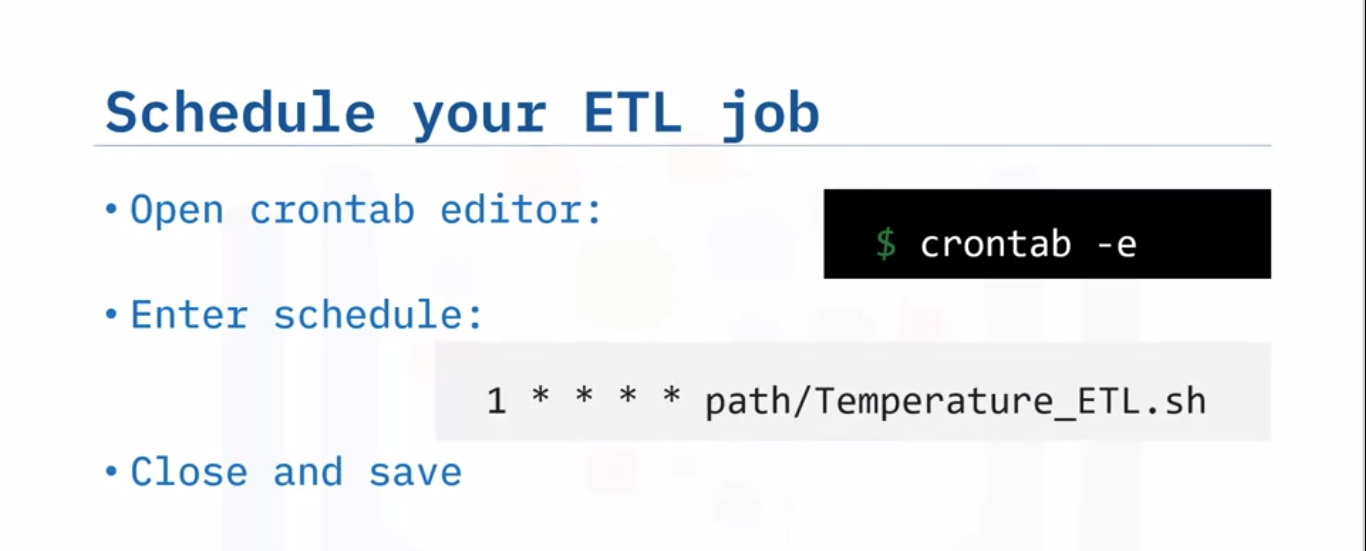
Schedule your job to run every minute of every day.
$ crontab -e
Close the editor and save your edits.
Your new ETL job is now scheduled and running in production.
Now our final task is to load the data in the file ‘web-server-access-log.txt.gz’ to the table ‘access_log’ in the PostgreSQL database ‘template1’:
The following are the columns and their data types in the webserver-access-log.txt.gz file :
A. timestamp – TIMESTAMP
B. latitude – float
C. longitude – float
D. visitorid – char(37)
and two more columns: accessed_from_mobile (boolean) and browser_code (int).
The file is available at the location: “https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DB0250EN-SkillsNetwork/labs/Bash%20Scripting/ETL%20using%20shell%20scripting/web-server-access-log.txt.gz“.
The columns which we need to copy to the table are the first four columns: timestamp, latitude, longitude, and visitorid.
1: Start the Postgres server.
If the server is not already started, Run the start_postgres command.
$ start_postgres
2: Create the table.
Next create a table named shell_access_log to store the timestamp, latitude, longitude, and visitorid.
To connect to the database, run the following command to connect to PostgreSQL.
$ psql --username=postgres --host=localhost

In PostgreSQL, run the following command to connect to the database ‘template1’.
postgres=# c template1;

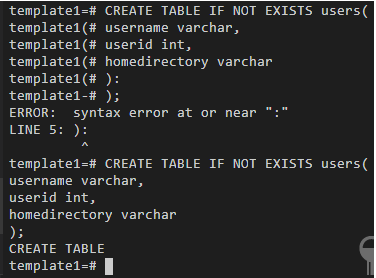
Once you connect to the database, run the command to create the table called ‘access_log’:
CREATE TABLE access_log(timestamp TIMESTAMP, latitude float, longitude float, visitor_id char(37));
It should receive the confirmation message ‘CREATE TABLE’

Once you receive the confirmation message ‘CREATE TABLE’, Quit from psql command-line:
q
3. Create a shell script named shell-access-log.sh and add commands to complete the remaining tasks to extract and copy the data to the database.
Create a shell scripting to add commands to complete the rest of the tasks.
To create a new file, use File->New File
Name the newly created file as “shell-access-log.sh” and click ‘OK’.
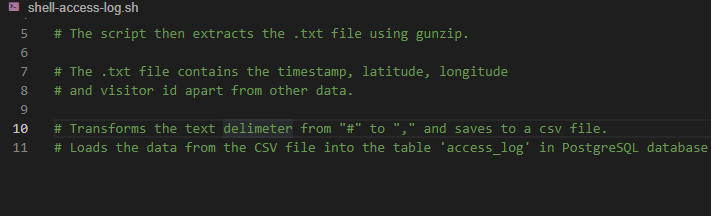
For listing the aim of the script using comments, copy and paste the below commands into the newly created file(shell-access-log.sh).
# shell-access-log.sh
# This script downloads the file ‘web-server-access-log.txt.gz’ # from “https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DB0250EN-SkillsNetwork/labs/Bash%20Scripting/ETL%20using%20shell%20scripting/”.
# The script then extracts the .txt file using gunzip.
# The .txt file contains the timestamp, latitude, longitude, and
# a visitor_id apart from other data.
# Transforms the text delimiter from “#” to “,” and saves to a csv file.
# Loads the data from the CSV file into the table ‘access_log’ in the PostgreSQL database.
Now Save the file using the File->Save menu option.The file should look like this,
Now Save the file using the File->Save menu option. The file should look like this,
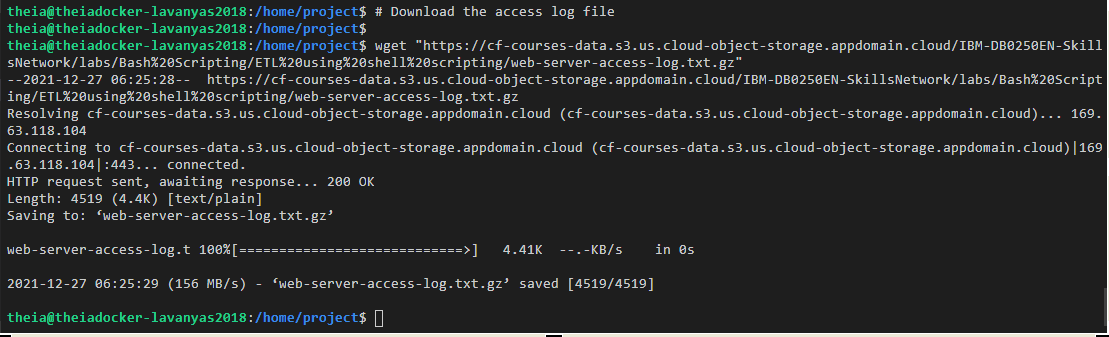
Before extracting the data from the file, we have to download the file into the runtime. To download the access log file.
# Download the access log file
wget "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DB0250EN-SkillsNetwork/labs/Bash%20Scripting/ETL%20using%20shell%20scripting/web-server-access-log.txt.gz"
After downloading the file, Unzip the gzip file.
# Unzip the file to extract the .txt file.
gunzip -f web-server-access-log.txt.gz
After unzipping the file, we need to extract some fields from the file.
Extract timestamp, latitude, longitude, and visitorid which are the first four fields from the file using the cut command.
Write the extract code and add them to the end of the script(shell_access_log.sh).(shell_access_log.sh).
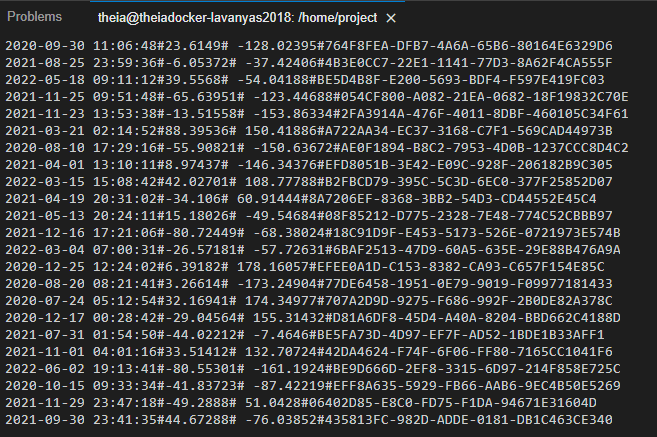
# Extract phase echo "Extracting data" # Extract the columns 1 (timestamp), 2 (latitude), 3 (longitude) and # 4 (visitorid) cut -d# -f1-4 web-server-access-log.txt
The columns in the web-server-access-log.txt file are delimited by ‘#’.
Save the file and run the script using the bash command.
$ bash shell-access-log.sh
Verify the output contains all the four fields that we extracted.
Now, redirect the extracted output into a text file.
To redirect the extracted data into a file named extracted-data.txt, replace the cut command at end of the shell_access_log.sh script with the following command.
# Extract phase echo "Extracting data" # Extract the columns 1 (timestamp), 2 (latitude), 3 (longitude) and # 4 (visitorid) cut -d# -f1-4 web-server-access-log.txt > extracted-data.txt
Again Save the file and run the script.
$ bash cp-access-log.sh
Run the command below to verify that the file extracted-data.txt is created, and has the content.
$ cat extracted-data.txt
the output must display like below,
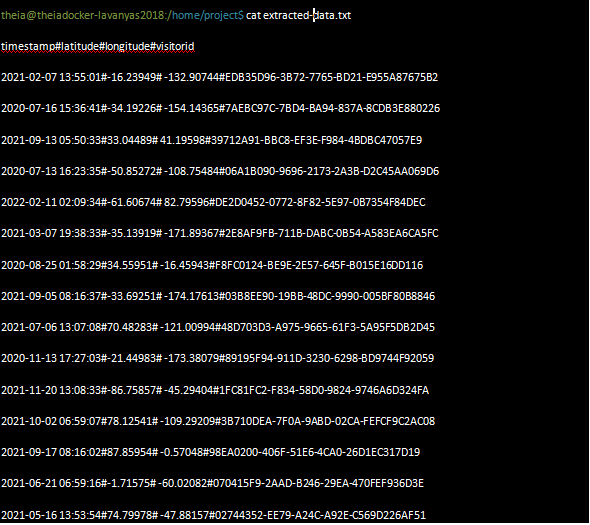
Now next step is to perform a transform in the txt file to CSV format.
The original “#” delimiter set apart the extracted columns.
We need to convert this into a “,” delimited file.
To perform the above operation, Add the following code below at the end of the script shell_access_log.sh.
# Transform phase echo "Transforming data" # read the extracted data and replace the colons with commas. tr "#" "," < extracted-data.txt
Save the file and run the script.
$ bash cp-access-log.sh
We need to verify that the output contains ‘,’ in place of “#”.
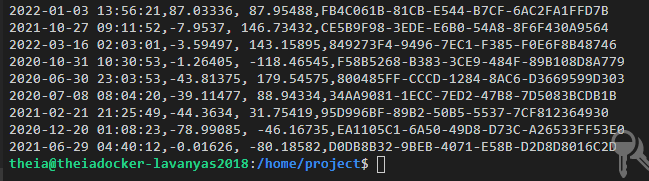
Now we need to transform the .txt data into .CSV file.
Replace the tr command at end of the script with the command below.
tr “#” “,” transformed-data.csv
After replacing the command, the script will now look like this:
# Extract phase
echo "Extracting data"
# Extract the columns 1 (timestamp), 2 (latitude), 3 (longitude) and # 4 (visitorid) cut -d# -f1-4 web-server-access-log.txt > extracted-data.txt
# Transform phase echo "Transforming data"
# read the extracted data and replace the colons with commas. tr "#" "," transformed-data.csv
Save the file and run the script.
$ bash cp-access-log.sh
Output:

Run the command below to verify that the file ‘transformed-data.csv’ is created, and has the content.
$ cat transformed-data.csv
verify the output looks like this,
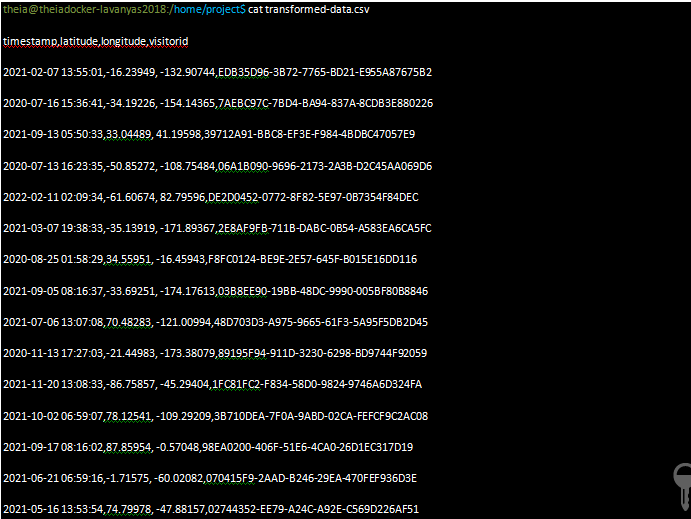
The final step is to load the data into the table access_log in PostgreSQL
PostgreSQL command to copy data from a CSV file to a table is COPY.
The syntax for the Query:
COPY table_name FROM 'filename' DELIMITERS 'delimiter_character' FORMAT;
The file comes with a header. So use the ‘HEADER’ option in the ‘COPY’ command.
Invoke this command from the shell scripting by sending it to ‘psql’ filter command.
Now, append the copy command and add the line to the end of the script ‘shell-access-log.sh’.
# Load phase echo "Loading data" # Send the instructions to connect to 'template1' and # copy the file to the table 'access_log' through the command pipeline. echo "c template1;COPY access_log FROM '/home/project/transformed-data.csv' DELIMITERS ',' CSV HEADER;" | psql --username=postgres --host=localhost
Now the shell_access_log.sh file should have the following final script:
# Extract phase echo "Extracting data" # Extract the columns 1 (timestamp), 2 (latitude), 3 (longitude) and # 4 (visitorid) cut -d# -f1-4 web-server-access-log.txt > extracted-data.txt # Transform phase echo "Transforming data" # read the extracted data and replace the colons with commas. tr "#" "," transformed-data.csv # Load phase echo "Loading data" # Send the instructions to connect to 'template1' and # copy the file to the table 'access_log' through the command pipeline. echo "c template1;COPY access_log FROM '/home/project/transformed-data.csv' DELIMITERS ',' CSV HEADER;" | psql --username=postgres --host=localhost
After saving the file, run the final script.
$ bash shell-access-log.sh

To query the database, load the transformed data into the PostgreSQL table like the one shown below,
Run the command below to verify that the table accesss_log is populated with the data.
$ echo 'c template1; \SELECT * from access_log;' | psql --username=postgres --host=localhost
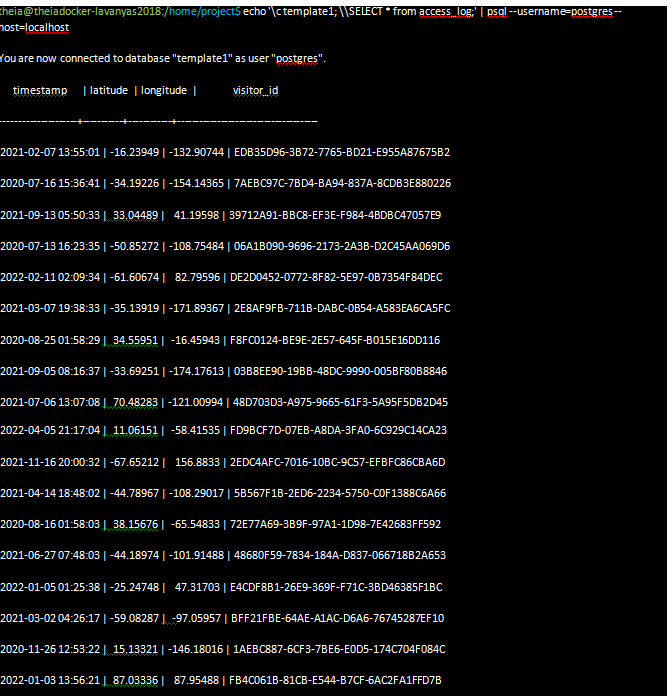
You should see the records displayed on the screen.
ETL pipelines are created with Bash scripts
We can schedule ETL jobs that can run on a schedule using cron.
$ crontab -e
About Myself:
Hello, my name is Lavanya, and I’m from Chennai. Being a passionate writer and an enthusiastic content maker, I used to surf through many new technological concepts. The most intractable problems always thrill me. I am doing my graduation in B. Tech in Computer Science Engineering and have a strong interest in the fields of data engineering, machine learning, data science, artificial intelligence, and Natural Language Processing, and I am steadily looking for ways to integrate these fields with other disciplines of science and technologies to further my research goals.
Linkedin URL: https://www.linkedin.com/in/lavanya-srinivas-949b5a16a/
End Notes:
An ETL pipeline known as a data pipeline is the system that allows ETL activities. Data pipelines are a set of tools and actions for transporting data from one system to another, where it can be stored and managed differently.
I hope this article will be more descriptive and refreshing!
If you have further queries, please post them in the comments section. If you are interested in reading my other articles, check them out here!
Thank you for reading my article on Shell Scripting. Hope you liked it.
Additional reference:
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.





