Feed-forward Neural Networks, also known as Deep feedforward Networks or Multi-layer Perceptrons, are the focus of this article. For example, Convolutional and Recurrent Neural Networks (used extensively in computer vision applications) are based on these networks. We’ll do our best to grasp the key ideas in an engaging and hands-on manner without having to delve too deeply into mathematics.
Search engines, machine translation, and mobile applications rely on deep learning technologies. These technologies stimulate the human brain to identify and create patterns from various types of input.
A feedforward neural network is a key component of this fantastic technology since it aids software developers with pattern recognition and classification, non-linear regression, and function approximation.Also, in this article you will get to know about deep feed forward network in deep learning, and all you to get about the neural network and deep learning.
Let’s look at this fundamental aspect of the neural network’s construction.
This article was published as a part of the Data Science Blogathon

Table of contents
What is Feed-forward Neural Networks?
A feedforward neural network is an artificial neural network in which nodes’ connections do not form a loop. Often referred to as a multi-layered network of neurons, feedforward neural networks are so named because all information flows forward only.
Data enters the input nodes, travels through the hidden layers, and exits the output nodes. The network lacks links, allowing the information leaving the output node to be sent back into the network.
The purpose of feedforward neural networks is to approximate functions.
Here’s how it works
A classifier uses the formula y = f* (x).
This assigns the value of input x to the category y.
The feedfоrwаrd netwоrk will mар y = f (x; θ). It then memorizes the value of θ that most closely approximates the function.
The Google Photos app shows that a feedforward neural network is the foundation for photo object detection.
Types of Neural Network’s Layers
The following are the components of a feedforward neural network:
Layer of input
It contains the neurons that receive input. The data is subsequently passed on to the next tier. The input layer’s total number of neurons equals the number of variables in the dataset.
Hidden layer
This is the intermediate layer, which is concealed between the input and output layers. It has many neurons that alter the inputs and then communicate with the output layer.
Output layer
It is the last layer and depends on the model’s construction. The output layer is the expected feature, as you know the desired outcome.
Neurons weights
Weights describe the strength of a connection between neurons. A weight’s value ranges from 0 to 1.
Cost Function in Feedforward Neural Network
The cost function is an important factor of a feedforward neural network. Generally, minor adjustments to weights and biases have little effect on the categorized data points. Thus, a method for improving performance can be determined by making minor adjustments to weights and biases using a smooth cost function.
The mean square error cost function is defined as follows:

Where,
w = weights collected in the network
b = biases
a = output vectors
x = input
‖v‖ = usual length of vector v
Loss Function in Feedforward Neural Network

The cross-entropy loss associated with multi-class categorization is as follows:

Also Read: Understanding Loss Function in Deep Learning
Gradient Learning Algorithm
The Gradient Descent Algorithm repeatedly calculates the next point using gradient at the current location, then scales it (by a learning rate) and subtracts the achieved value from the current position (makes a step) (makes a step). It subtracts the value since we want to decrease the function (to increase it would be adding) (and to maximize it would be adding). This procedure may be written as:
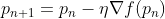
There’s a crucial parameter η, which adjusts the gradient and hence affects the step size. In machine learning, it is termed learning rate and substantially affects performance.
- The smaller the learning rate, the longer GD converges or may approach maximum iteration before finding the optimal point
- If the learning rate is too great, the algorithm may not converge to the ideal point (jump around) or diverge altogether.
The Gradient Descent method’s steps are:
- Pick a beginning point (initialization)
- Compute the gradient at this spot
- Produce a scaled step in the opposite direction to the gradient (objective: minimize) (objective: minimize)
- Repeat points 2 and 3 until one of the conditions is met:
- maximum number of repetitions reached
- step size is smaller than the tolerance.
The following is an example of how to construct the Gradient Descent algorithm (with steps tracking):
The function accepts the following five parameters:
- Starting point: In our example, we specify it manually, but it is frequently determined randomly.
- Gradient function – must be defined in advance
- Learning rate – factor used to scale step sizes
- Maximum iterations
- Tolerance for the algorithm to be stopped on a conditional basis (in this case, a default value is 0.01)
Example- A quadratic function
Consider the following elementary quadratic function:
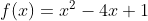
Because it is a univariate function, a gradient function is as follows:
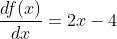
Let us now write the following methods in Python:def func1(x): return x**2-4*x+1 def gradient_func1(x):
return 2*x – 4
With a learning rate of 0.1 and a starting point of x=9, we can compute each step manually for this function. Let us begin with the first three steps:
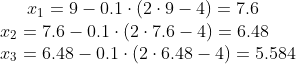
The python function is invoked as follows:history, result = gradient_descent(9, gradient_func1, 0.1, 100)
The animation below illustrates the GD algorithm’s steps at 0.1 and 0.8 learning rates. As the algorithm approaches the minimum, the steps become steadily smaller. Jumping from one side to the other is necessary for a faster learning rate before convergence.
.gif)
The following diagram illustrates the trajectory, number of iterations, and ultimate converged output (within tolerance) for various learning rates:

The Need for a Neuron Model
Suppose the inputs to the network are pixel data from a character scan. There are a few things you need to keep in mind while designing a network to classify a digit appropriately:
You must experiment with the weights to see how the network learns. To reach perfection, weight variations of just a few grams should have a negligible effect on production.
On the other hand, what if a minor change in the weight results in a large change in the output? The sigmoid neuron model can resolve this issue.

Applications of Feedforward Neural Network
These neural networks are utilized in a wide variety of applications. The following are units denote several of them:
- Physiological feedforward system: Feedforward management is exemplified by the central involuntary system’s usual preventative control of heartbeat before exercise.
- Gene regulation and feedforward: A theme predominates throughout the famous networks, and this motif has been demonstrated to be a feedforward system for detecting non-temporary atmospheric alteration.
- Parallel feedforward compensation with derivative: This is a relatively recent approach for converting the non-minimum component of an open-loop transfer system into the minimum part.
What is the difference between feedforward and feed backward neural networks?
The primary distinctions between feedforward and recurrent neural networks are:
Direction of signal flow
Feedforward neural networks function in a one-way direction, transmitting signals from input to output layers without any loops for feedback.
Recurrent neural networks possess bidirectional signal flow and are capable of processing sequences by retaining an internal state that serves as a type of memory.
Difficulty
Feedforward networks are less complex and have simpler structures.
Feedback loops and the capability to handle sequences make recurrent networks more intricate.
Algorithms for training purposes
Backpropagation is commonly employed to train feedforward networks by modifying weights according to the difference between expected and observed results.
Recurrent networks are commonly trained with backpropagation through time (BPTT), which is a modified version of feedforward backpropagation designed for recurrent networks.
Also Read: How to Load Kaggle Datasets Directly Into Google Colab?
Conclusion
Deep learning is a field of software engineering that has accumulated a massive amount of study over the years. Researchers have developed several neural network designs for use with diverse data types. Applying neural networks to large datasets requires enormous computing power and equipment acceleration. Designers achieve this by arranging a Graphics Processing Units (GPUs) system in a cluster.
New GPU users can find free customized settings on the Internet, which they can download and use without charge. They most commonly use Kaggle Notebooks and Google Colab Notebooks. To build a good feedforward neural network, you must test the network design several times.
Frequently Asked Questions
Q1. What is the difference between feedforward and deep neural networks?
A. Feedforward neural networks have a simple, direct connection from input to output without looping back. In contrast, deep neural networks have multiple hidden layers, making them more complex and capable of learning higher-level features from data.
Q2. Is CNN a Feedforward Network?
A. Yes, Convolutional Neural Networks (CNNs) are feedforward networks. They process input data through layers in a single forward pass, applying convolutional filters to detect patterns and features, particularly effective for image and spatial data.
Q3. What is the difference between feedforward and feedbackward neural networks?
A. Feedforward neural networks move data in one direction from input to output, without loops. In contrast, feedback (or recurrent) neural networks allow connections to cycle back, enabling the network to maintain a state and process sequences or temporal data.
Q4. What is the main difference between a feedforward neural network and a recurrent neural network?
A. Feedforward neural networks process data in a single pass from input to output without considering temporal dynamics. However, recurrent neural networks (RNNs) have loops that allow them to maintain a memory of previous inputs, making them suitable for sequential and time-dependent tasks.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!






