Image classification is a cornerstone task in computer vision, enabling machines to effectively interpret and categorize visual data. While deep learning models like Convolutional Neural Networks (CNNs) dominate the field, traditional machine learning algorithms still hold value for research and comparison purposes. In this blog, we will discuss how to perform image classification using machine learning using four popular algorithms: Random Forest Classifier, KNN, Decision Tree Classifier, and Naive Bayes classifier. We will then jump into implementation step-by-step.
At the end of the article, you will understand why Deep Learning is preferred for image classification using machine learning and machine learning image classification. However, the work demonstrated here will help serve research purposes if one desires to compare their CNN image classifier model with some machine learning algorithms.
Learning Objective:
- Provide a step-by-step guide to implementing image classification algorithms using popular machine learning algorithms like Random Forest, KNN, Decision Tree, and Naive Bayes.
- Demonstrate the limitations of traditional machine learning algorithms for image classification algorithms tasks and highlight the need for deep learning approaches.
- Showcase how to test the trained models on custom input images and evaluate their performance.
This article was published as a part of the Data Science Blogathon.
Table of contents
Dataset Acquisition

The dataset utilized in this blog is the CIFAR-10 dataset, a Keras dataset that can be easily downloaded using the following code. The dataset includes ten classes: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck, indicating that we will address a multi-class classification problem.
First, let’s import the required packages as follows:
from tensorflow import keras
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
import numpy as np
import cv2The dataset can be loaded using the code below:
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()Further, we can obtain the size of the train and test datasets as shown below:
x_train.shape,x_test.shapeThus, there are a total of 50,000 images for training and 10,000 images for testing. Each of these images is 32×32 and colour. The above details can be easily inferred from the shape returned.
NOTE: Observe that there is no need for a train-test split in this case, as train and test sets can be directly obtained from Keras!
Dataset Pre-Processing
This step includes the normalization of images followed by their reshaping.
Normalization is a common step of image preprocessing. It is achieved by simply dividing x_train by 255.0 for the training dataset and x_test by 255.0 for the test dataset. This is essential to maintaining the pixels of all the images within a uniform range.
# Normalization
x_train = x_train/255.0
x_test = x_test/255.0Now comes the most essential step of pre-processing, which is applicable only in this case as we aim to use machine learning for image classification. As we will use the ML algorithms from sklearn, we need to reshape the dataset’s images into a two-dimensional array. Sklearn expects a 2D array to be input to the fit() function, which will be called on the model during training.
Thus, the images of the test dataset should also be resized to 2D arrays as the model was trained with this input shape in machine learning image classification.
NOTE: Neural networks allow us to specify the input shape to the model, making it more flexible. However, there are some restrictions in the case of sklearn.
The required code for the train set is as follows:
#sklearn expects i/p to be 2d array-model.fit(x_train,y_train)=>reshape to 2d array
nsamples, nx, ny, nrgb = x_train.shape
x_train2 = x_train.reshape((nsamples,nx*ny*nrgb))The above code reshapes train set images from (50000,32,32,3), which is a 4D array, to (50000,3072), a 2D array.3072 is obtained by multiplying the dimensions of the image(32x32x3=3072).
The required code for the test set is given below:
#so,eventually,model.predict() should also be a 2d input
nsamples, nx, ny, nrgb = x_test.shape
x_test2 = x_test.reshape((nsamples,nx*ny*nrgb))Similarly, the images of the test set are reshaped from (10000,32,32,3) to (10000,3072).
Implementing a Random Forest Classifier
Let’s build a Random Forest Classifier to classify the CIFAR-10 images.
For this, we must first import it from sklearn:
from sklearn.ensemble import RandomForestClassifierCreate an instance of the RandomForestClassifier class:
model=RandomForestClassifier()Finally, let us proceed to train the model:
model.fit(x_train2,y_train)NOTE: Pass x_train2 to fit() function as it is the reshaped 2D array of the images and sklearn needs a 2D array as input here. Do this while fitting for all the models as they are all implemented using sklearn
Now, predict the test set using the fitted Random Forest Classifier model for image classification algorithms:
y_pred=model.predict(x_test2)
y_predThe model returns a number from 0 to 9 as the output.
The displayed predictions clearly show this. We can map these answers to their corresponding classes using the following table:
Here is an HTML table representing the provided classes: “`html| Class | Output |
|---|---|
| 0 | Airplane |
| 1 | Automobile |
| 2 | Bird |
| 3 | Cat |
| 4 | Deer |
| 5 | Dog |
| 6 | Frog |
| 7 | Horse |
| 8 | Ship |
| 9 | Truck |
Now, evaluate the model with the test images by obtaining its classification report, confusion matrix, and accuracy score.
accuracy_score(y_pred,y_test)
print(classification_report(y_pred,y_test))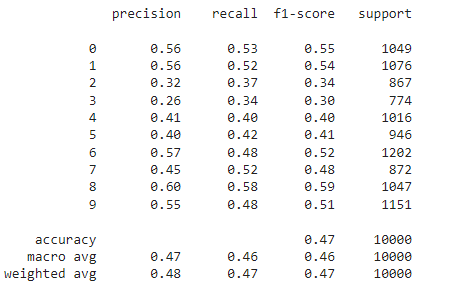
confusion_matrix(y_pred,y_test)
Thus, the Random Forest Classifier shows only 47% accuracy on the test set.
Implementing a KNN
KNN stands for K-nearest neighbours. It is also an algorithm popularly used for multi-class classification.
It is implemented in sklearn using the K-Neighbors Classifier class. We begin by importing it:
from sklearn.neighbors import KNeighborsClassifierAnd then instantiating it to create a KNN model:
knn=KNeighborsClassifier(n_neighbors=7)I have chosen seven neighbours randomly. Feel free to play with the number of neighbours to arrive at a better and, thus, optimal model.
Finally, train it:
knn.fit(x_train2,y_train)Now, predict for the test set using the fitted KNN model:
y_pred_knn=knn.predict(x_test2)
y_pred_knnThe predictions are outputs representing the classes as described in the previous algorithm.
Now, proceed to evaluate the KNN model just the way we evaluated our previous model.
accuracy_score(y_pred_knn,y_test)
print(classification_report(y_pred_knn,y_test))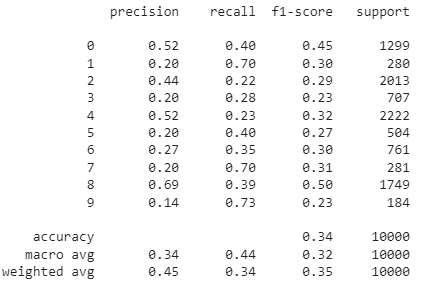
confusion_matrix(y_pred_knn,y_test)
Thus, the KNN Classifier shows only 34% accuracy on the test set.
Implementing a Decision Tree
It is implemented in sklearn using the DecisionTreeClassifier class. We begin by importing it:
from sklearn.tree import DecisionTreeClassifierAnd then instantiating it to create a DecisionTreeClassifier model:
dtc=DecisionTreeClassifier()Finally, train it:
dtc.fit(x_train2,y_train)Now, predict the test set using the fitted decision tree model:
y_pred_dtc=dtc.predict(x_test2)
y_pred_dtcThe predictions are outputs representing the classes as described in the previous algorithm.
Now, proceed to evaluate the decision tree model just as we evaluated our previous model.
accuracy_score(y_pred_dtc,y_test)
print(classification_report(y_pred_dtc,y_test))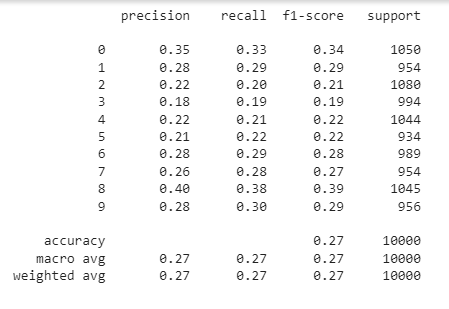
confusion_matrix(y_pred_dtc,y_test)
Thus, the Decision tree Classifier shows only 27% accuracy on the test set.
Implementing a Naive Bayes Classifier
It is the most fundamental machine learning classifier, also abbreviated as NB. It works based on Bayes Theorem and has independent features.
It’s implemented in sklearn using the GaussianNB class. We begin by importing it:
from sklearn.naive_bayes import GaussianNB
And then instantiating it to create an NB model:
nb=GaussianNB()Finally, train it:
nb.fit(x_train2,y_train)Now, predict for the test set using the fitted NB model:
y_pred_nb=nb.predict(x_test2)
y_pred_nbThe predictions are outputs representing the classes as described in the previous algorithm.
Now, proceed to evaluate the decision tree model just as we evaluated our previous model.
accuracy_score(y_pred_nb,y_test)
print(classification_report(y_pred_nb,y_test))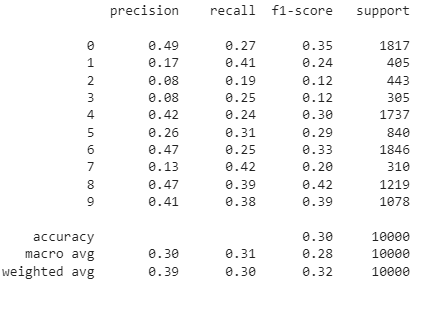
confusion_matrix(y_pred_nb,y_test)
Thus, the Naive Bayes Classifier shows only 30% accuracy on the test set.
Results
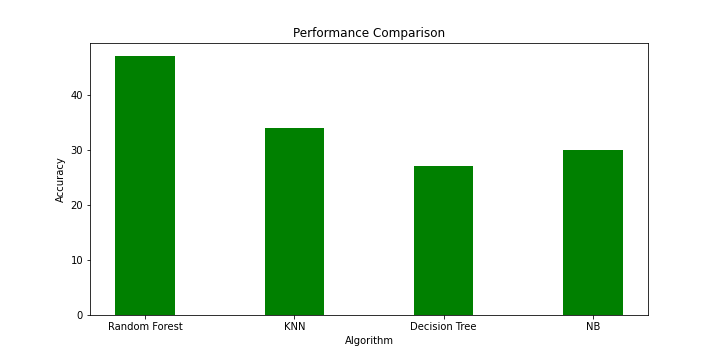
The graph above summarizes the accuracies of the four ML algorithms we just explored for our CIFAR-10 dataset.
The Random Forest Classifier shows the best performance, with 47% accuracy, followed by KNN, with 34% accuracy, NB, with 30% accuracy, and Decision Tree, with 27% accuracy. Thus, Random Forest exhibits the best performance, and Decision Tree exhibits the worst.
However, all Machine learning algorithms perform poorly, as indicated by their accuracy. The highest is just 47%, while Deep learning algorithms outsmart them exceptionally, with accuracy mostly exceeding 90%!!!
I mentioned at the beginning that this work can only be used to compare a Deep Learning model and defend the DL model.
Testing for Custom Input
From the above results, RandomForestClassifier shows the best performance and decent accuracy. Let us choose this model.
Custom input refers to an image you want to pass to the model and test.
Many real-time applications test models for a single input. For example, a system uses an individual’s photo to recognize faces.
I have used the following custom image to test my model:

Mention the path of your image, which is the location where you have stored the custom image you want to test.
img_path='/content/bird.jfif'NOTE: As I have implemented the work on Google Colab,I uploaded an image there and included the path of the image accordingly. Change the value of img_path according to the location of the image you want to test.
First, read the image using OpenCV and then resize it to 32×32.
img_arr=cv2.imread(img_path)
img_arr=cv2.resize(img_arr,(32,32))Now, reshape the image to 2D as discussed in the pre-processing section:
#so,eventually,model.predict() should also be a 2d input
nx, ny, nrgb = img_arr.shape
img_arr2 = img_arr.reshape(1,(nx*ny*nrgb))Let us declare a list called classes:
classes = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]It has all ten categories. As discussed earlier, the model will output a number from 0 to 9, and the corresponding class can be retrieved from the above list.
Finally, the required array is passed to the random forest classifier using the predict() function.
ans=model.predict(img_arr2)
print(classes[ans[0]])
#RandomForestClassifierThe answer variable is a list having only one number, which is the index of the class list. The category in this index is the predicted class.
The model predicts it to be a bird, which is right! But it predicts incorrectly for a few test images. Building a CNN or ANN model instead can overcome this drawback.
Conclusion
Thus, this blog discussed image classification in machine learning by implementing four common ML algorithms, including Random Forest, KNN, Decision Tree, and Naive Bayes classifier. Due to their poor accuracy, deep learning is preferred for image classification tasks.
You can explore this work further by improving these image classifications in ML models using hyperparameter tuning. You may arrive at better accuracies in that case! Go ahead and try!
Key Takeaways:
- ML algorithms have poor accuracy for image classification using machine learning.
- Preprocessing steps like normalization and reshaping are required.
- Deep learning (CNNs) is preferred for better accuracy.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Frequently Asked Questions
Q1. Can we use KNN for image classification?
A. Yes, KNN can be used for image classification. However, it is often less efficient than deep learning models for complex tasks.
Q2. Which ML model is best for classification?
A. The best ML model for classification often depends on the dataset, but deep learning models like convolutional neural networks (CNNs) are highly effective for image classification.
Q3. What is vgg16 model for image classification?
A. The developers designed VGG16 as a convolutional neural network model for image classification. It features 16 layers of convolutional layers, max pooling, and fully connected layers and is known for its depth and performance.
Q4. What are the 5 steps involved in image classification?
A. The five steps involved in image classification are:
a) Data preprocessing
b) Data augmentation
c) Model building
d) Model training
e) Model evaluation







Great tutorial! Well written. Using pixel intensity values as features is not a very good way of training a model. You could use Convolutions from CNN to extract features and reduces dimensions. This can be flattened and utilised as features
Hi! Why we need resize the image to 32x32? Great work!
hey I am having issues loading the data set. I'm getting some sort of SSLCertVerificationError Error message. Do you have any solutions