What is KNN?
KNN also called K- nearest neighbour is a supervised machine learning algorithm that can be used for classification and regression problems. K nearest neighbour is one of the simplest algorithms to learn. K nearest neighbour is non-parametric i,e. It does not make any assumptions for underlying data assumptions. K nearest neighbour is also termed as a lazy algorithm as it does not learn during the training phase rather it stores the data points but learns during the testing phase. It is a distance-based algorithm.
In this article, I will explain the working principle of KNN, how to choose K value, and different algorithms used in KNN.
This article was published as a part of the Data Science Blogathon.
Working Principle Of KNN
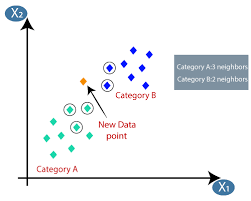
Source:https://www.javatpoint.com/k-nearest-neighbor-algorithm-for-machine-learning
Consider there are two categories, category A and category B. We want to classify which category the new datapoint lies in. To classify the point we can use the KNN algorithm which observes the behaviour of the nearest points and classify itself accordingly. In this case, the behaviour is which category it belongs to.
Consider an XY plane with data points plotted in the graph.
Choose the K value
Calculate the distance between all the training points and new data points.
Sort the computed distance in ascending order between training points and new data points.
Choose the first K distances from the sorted list
Take the mode/mean of the classes associated with the distances.
For classification problem compute mode else for regression problem compute mean with the distances.
Distance Metrics
It is essential to choose the most appropriate distance metrics for a particular dataset. The following are the various distance metrics:
Minkowski Distance-Minkowski distance is calculated where distances are in the form of vectors that have a length and the length cannot be negative.
Manhattan Distance-The distance between two points is the sum of the absolute differences of their Cartesian coordinates.
Euclidean Distance- It is a measure of the true straight line distance between two points in Euclidean space.
Cosine Distance-It is used to calculate the similarity between two vectors. It measures the direction and uses the cosine function to calculate the angle between two vectors.
Jaccard Distance-It is similar to cosine distance as both the methods compare one type of attribute distributed among all data. The Jaccard approach looks at the two data sets and finds the incident where both values are equal to 1.
How to choose the K value?
One of the trickiest questions to be asked is how we should choose the K value.
One should not use a low value of K= 1 because it may lead to overfitting i,e during the training phase performs good but during the testing phase, the model performs badly. Choosing a high value of K can also lead to underfitting i.e it performs poorly during the training and testing phase.
We should not use even values of K when classifying binary classification problems. Suppose we choose K=4 and we evenly distribute the neighboring 4 points among classes, with 2 data points belonging to category 1 and 2 data points belonging to category 2. In that case, the data point cannot classify as there is a tie between the classes
Choose K value based on domain knowledge.
Plot the elbow curve between different K values and error. Choose the K value when there is a sudden drop in the error rate.
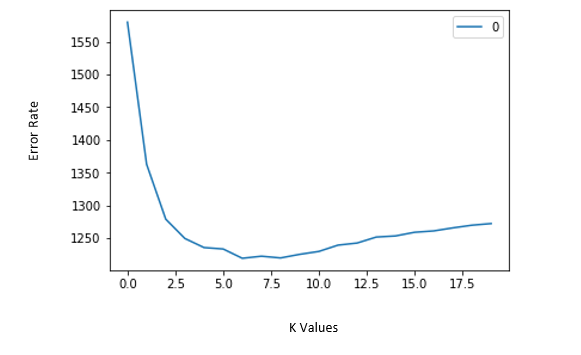
Source:https://prwatech.in/blog/tag/k-nearest-neighbors-algorithm-tutorial/
Different Algorithms of KNN
Before going forward learning different algorithms of KNN it is important to know what a tree is. A tree as a non-linear data structure to store collections of objects by linking nodes together to represent a hierarchy.
There are four different algorithms in KNN namely kd_tree,ball_tree, auto, and brute.
kd_tree=kd_tree is a binary search tree that holds more than x,y value in each node of a binary tree when plotted in XY coordinate. To classify a test point when plotted in XY coordinate we split the training data points in a form of a binary tree. We can choose to split the root node through X coordinate by taking its median.For example training set have points [(1,2),(2,3),(3,4),(4,5),(5,6),(6,7),(7,8)].By splitting the tree through X-axis we see the point (4,5) forms the root. I
n the next layer of the binary tree we split the data point by taking the median but rather than splitting it based on the X-axis we split it concerning the Y-axis. On the left-hand side, we get (1,2),(2,3),(3,4) and on the right hand, we get (5,6),(6,7),(7,8).On the left-hand side taking the median concerning y axis[2,3,4] we get (2,3).On the right-hand side taking the median concerning the Y-axis we get (6,7).[Note that y points on the left-hand side are[6,7,8]. We take the median of these points and not the X-axis of it]. The process carries on alternatively until all nodes are split.
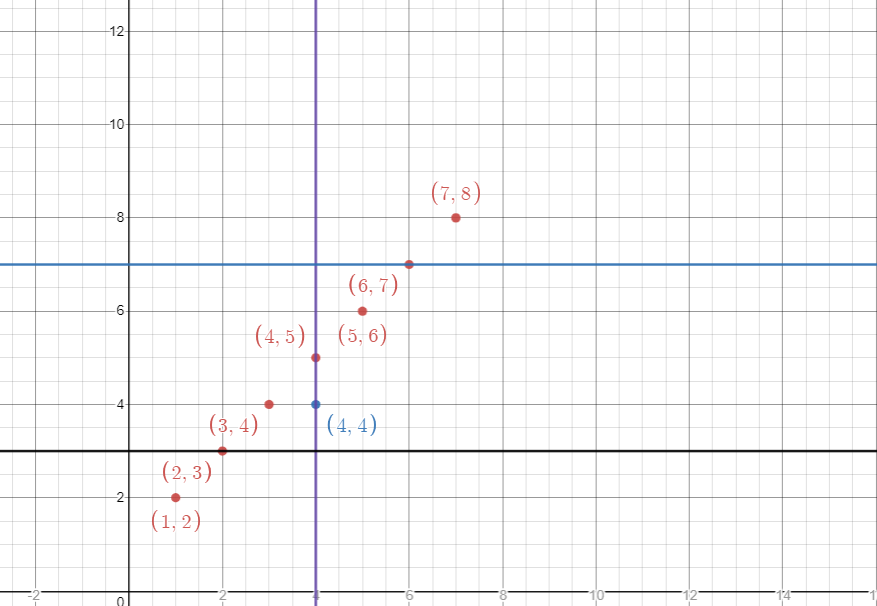
Source:https://www.desmos.com/calculator
ball_tree=This algorithm is based on ball structure. This algorithm forms clusters of ball structure with the data points. The first cluster has all the training data points. The point with maximum distance to the centroid forms the new centroid of the second cluster. The main principle of the ball tree algorithm is dividing the data points into clusters. The cluster keeps on dividing until a particular defined depth or limit is reached.
brute=Brute force algorithm tries to find the most optimal value or class from an exhaustive list to classify the test point accurately.
auto=Auto algorithm will try to find the most optimal point or class based on the values passed in the fit method. We can specify a range of values for k value, weights, and leaf size hyperparameters of K nearest neighbour.
Advantages & Disadvantages of KNN Algorithm
Advantages
It is very easy to understand and implement
It is an instance-based learning(lazy learning) algorithm.
- NN learns during the training phase, but once trained, we can add new data points without affecting the algorithm’s performance.
It is well suited for small datasets.
Disadvantages
It fails when variables have different scales.
It is difficult to choose K-value.
It leads to ambiguous interpretations.
It is sensitive to outliers and missing values.
Does not work well with large datasets.
It does not work well with high dimensions.
Conclusion
In this article, we came across the introduction and working principle of KNN. We also looked at various distance metrics used in KNN to compute the distance between data points and various different KNN algorithms used when performing hyperparameter tuning and when to use them.
Read more articles on KNN Algorithms.
Analytics Vidhya does not own the media shown in this article; the authors use it at their discretion.






