This article was published as a part of the Data Science Blogathon.
This article focuses on the initial most important step of Natural Language Processing i.e. tokenization using different libraries (Gensim, Keras, and NLTK) in detail.

Natural language processing (NLP) is a subfield of Artificial intelligence that allows computers to perceive, interpret, manipulate, and reply to humans using natural language.
In simple words, “NLP is the way computers understand and respond to human language.”
Humans communicate through “text” in a different language. However, machines understand only numeric form. Therefore, there is a need to covert “text” to “numeric form”, making it understandable and computable by machines. Thus, NLP comes into the picture which uses pre-processing and feature encoding techniques like Label encoding, One Hot encoding, etc., converting text into numerical format also known as vectors.
For example, when a customer buys a product from Amazon, they leave a review for it. Now, the computer is not a human who understands the sentiment behind that review. Then, how can a computer understand the sentiment of a review? Here, NLP plays its role.
NLP has applications in language translation, sentiment analysis, grammatical error detection, fake news detection, etc.
Figure 1 provides a complete roadmap of NLP from text preprocessing to using BERT. We will discuss everything about NLP in detail taking use-cases and codes.
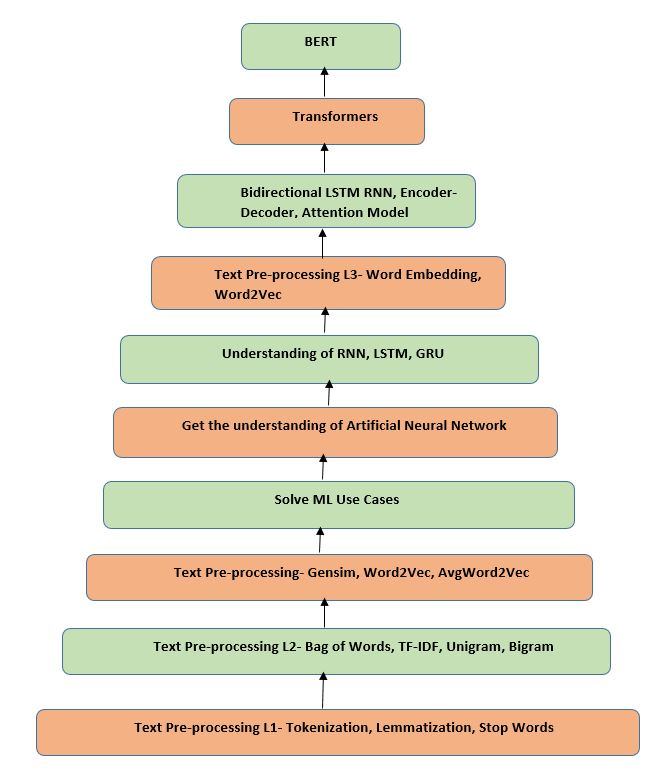
In this article, we will focus on the main step of Pre-processing i.e. Tokenization.
Tokenization
Tokenization is the breaking of text into small chunks. Tokenization splits the text (sentence, paragraph) into words, sentences called tokens. These tokens help in interpreting the meaning of the text by analyzing the sequence of tokens.
If the text is split into sentences using some separation technique it is known as sentence tokenization and the same separation done for words is known as word tokenization.
For instance, A review is given by a customer for a product on the Amazon website: “It is very good”. Tokenizer will break this sentence into ‘It’, ‘is’, ‘very’, ‘good’.
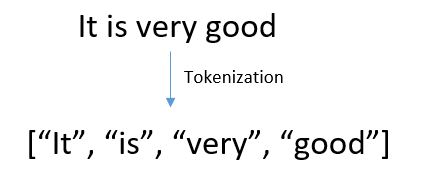
There are different methods and libraries available to perform tokenization. Keras, NLTK, Gensim are some of the libraries that can be used to accomplish the task. We will discuss tokenization in detail using each of these libraries.
Tokenization using NLTK
NLTK is the best library for building programs in Python and working with the human language. It provides easy-to-use interfaces, along with a suite of text processing libraries for tokenization, classification, stemming, parsing, tagging, and many more.
This section will help you tokenize the paragraph using NLTK. It will give you a basic idea about tokenizing which can be used in various use cases such as sentiment analysis, question-answering tasks, etc.
So let’s get started:
Note: It is highly recommended to use google colab to run this code.
#1. Import the required libraries
Import nltk library, as we will use it for tokenization.
import nltk
nltk.download('punkt')
#2. Get the Data
Here, a dummy paragraph is taken to show how tokenization is done. However, code can be applied on any text.
paragraph = """I have three visions for India. In 3000 years of our history, people from all over the world have come and invaded us.
From Alexander onwards, the Greeks, the Turks, all of them came and looted us, took over what was ours.
Yet we have not done this to any other nation. We have not conquered anyone.
We have not grabbed their land, their culture, their history and tried to enforce our way of life on them.
"""
#2. Tokenize paragraph into sentences
Take the paragraph and split it into sentences.
sentences = nltk.sent_tokenize(paragraph)
Output:

#4. Tokenize sentence into words
Rather than splitting paragraph into sentences, here, we are breaking it into words.
words = nltk.word_tokenize(paragraph)
Output:

Tokenization using Gensim
In this section, tokenization of same input is shown using Gensim library.
Gensim is an open source library which was primarily developed for topic modeling. However, it now supports NLP tasks, text similarity and many more.
#1. Import the required libraries.
from gensim.utils import tokenize from gensim.summarization.textcleaner import split_sentences
#2. Tokenize paragraph into sentences
split_sentences(paragraph)
Output:

#2. Tokenize into words
list(tokenize(paragraph))
Output:

Tokenization using Keras
The third way of tokenization is using Keras library.
Keras is an API designed not for machines but for human beings. Keras reduces cognitive load by offering consistent and simple APIs. It also reduces the number of actions required by users for a common use case. The documentation provided by Keras is detailed and extensive helping developers to easily take advantage. It is the most used deep learning library also used by NASA, CERN, and many more organizations around the world.
#1. Import the required libraries
from keras.preprocessing.text import Tokenizer from keras.preprocessing.text import text_to_word_sequence
#2 Tokenize
tokenizer = Tokenizer()
tokenizer.fit_on_texts(paragraph)
train_sequences = text_to_word_sequence(paragraph)
print(train_sequences)
Output:

Challenges with Tokenization
There exists a lot of challenges in tokenization. Here, we have discussed a few of them.
The biggest challenge in tokenization is the boundary of words. For example, when we see a space between two words, say “Ram and Shyam”, here we know that three words are involved as space represents the separation of words in English language. However, in other languages, such as Chinese, Japnese, case is not the same.
Another challenge created is by scientific symbols such as µ, α etc. and other symbols such as £, $, €.
Further, a lot of short forms are involved in English language such as didn’t (did not), etc which causes a lot of problems in the next step of NLP.
A lot of research is going in the field of NLP which requires the proper selection of corpora for the NLP task.
Conclusion
The article started with the definition of Natural Language Processing, discussed its use and applications. Then, the entire pipeline of NLP from tokenization to BERT is shown, majorly focusing on “Tokenization” in this article. NLTK, Keras, and Gensim are three libraries used for tokenization which are discussed in detail. At last, the challenges with Tokenization are briefly described.
In the next article, the next step in Natural Language Processing i.e. stemming and lemmatization in detail along with codes will be discussed.
Thanks for reading this article on Natural Language Processing. Please let me know about your experience of reading this article in the comment section.
Read more articles on AV Blog on NLP.
Connect with me on LinkedIn.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.



