This article was published as a part of the Data Science Blogathon.
Hey Folks!
Welcome to the NLP from zero to advanced series on analytics Vidhya where we are covering all the NLP topics from beginner to the advanced level.
In the last article, we have seen various text processing techniques with examples. If you haven’t read here is the link.
We are able to clean raw data and able to get cleaned text data. now it’s time to take the second step.

After getting cleaned data our second step is to convert the text data into a machine-readable format by converting them into numbers and this process is called feature extraction.
Table of Contents
- Feature Extraction
- Bag of Word model
- concept of n-grams
- Count Vectorizer method
- TF-IDF
- Word Embedding with python code
All the topics are detailed explained with python codes and images.
Why do we need feature extraction?
Feature Engineering is a very key part of Natural Language Processing. as we all know algorithms and machines can’t understand characters or words or sentences hence we need to encode these words into some specific form of numerical in order to interact with algorithms or machines. we can’t feed the text data containing words /sentences/characters to a machine learning model.
There are various ways to perform feature extraction. some popular and mostly used are:-
- Bag of Words model
- TF-IDF
1. Bag of Words(BOW) model
It’s the simplest model, Image a sentence as a bag of words here The idea is to take the whole text data and count their frequency of occurrence. and map the words with their frequency. This method doesn’t care about the order of the words, but it does care how many times a word occurs and the default bag of words model treats all words equally.
The feature vector will have the same word length. Words that come multiple times get higher weightage making this model biased, which has been fixed with TF-IDF discussed further.
Implementation of BOW model using Python:
sklearn provides all the necessary feature extraction techniques with easy implementation.
!pip install sklearn import sklearn from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer()
Importing CountVectorizer in order to implement the Bag of words model.
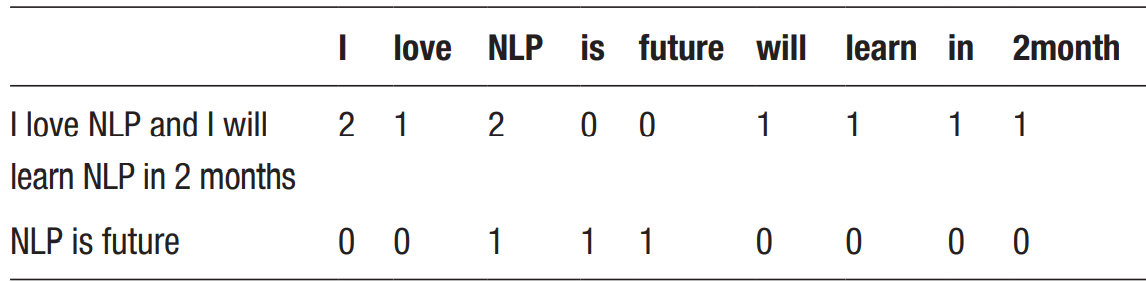
text = ["i love NLP",
"NLP is future",
"i will learn in 2 months"]
vectorizer = CountVectorizer()
count_matrix = vectorizer.fit_transform(text)
count_array = count_matrix.toarray()
df = pd.DataFrame(data=count_array,columns = vectorizer.get_feature_names())
print(df)
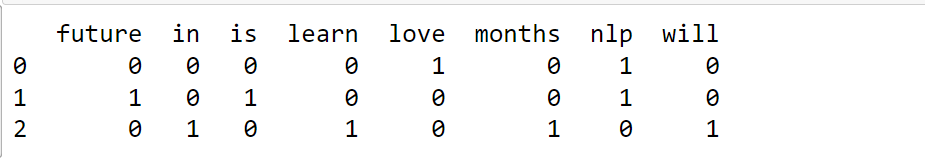
- the method
fit_transform()first fits the data to countVectorizer and then converts it into features - the method
get_features_name()returns the vocabulary of unique words. - once countVectorizer has fitted it would not update the Bag of words.
stopwordswe can pass a list of stopwords or specify language name ie {‘english’}to exclude stopwords from the vocabulary.
After fitting the countVectorizer we can transform any text into the fitted vocabulary.
text2 = ['I love NLP but can not learn in 2 months'] vectorizer.transform(text2).toarray()

In the above example of the BOW model, each word is considered as one feature but there are some problems with this model.
For example: assume that we have the word “not bad” and if we split this into “not” and “bad” then it will lose out its meaning. “not bad” is similar to “good” to some extent. we don’t want to split such words which lose their meaning after splitting. here the idea of n-grams comes into the picture.
- Unigrams are the single unique words in a sentence
- Bigrams are the combination of 2 words ie “not bad”,” turn off”.
- Trigrams are the combination of 3 words.
while implementing the BOW model using CounVectorizer we can include n-grams in vocabulary using
ngram_rangeparameter.
Implementation of the BOW model with n-gram:
ngram_range=(1, 1)means only unigrams,ngram_range=(1, 2)means unigrams with bigramsngram_range=(2, 2)means only bigrams.
text = ["food was not bad"] vectorizer = CountVectorizer(ngram_range = (1,2)) count_matrix = vectorizer.fit_transform(text) count_array = count_matrix.toarray() df = pd.DataFrame(data=count_array,columns = vectorizer.get_feature_names()) print(df)

2. TF-IDF (Term frequency-inverse Document Frequency)
The BOW model doesn’t give good results since it has a drawback. Assume that there is a particular word that is appearing in all the documents and it comes multiple times, eventually, it will have a higher frequency of occurrence and it will have a greater value that will cause a specific word to have more weightage in a sentence, that’s not good for our analysis.
The idea of TF-IDF is to reflect the importance of a word to its document or sentence by normalizing the words which occur frequently in the collection of documents.
Term frequency (TF): number of times a term has appeared in a document.
The term frequency is a measure of how frequently or how common a word is for a given sentence.
Inverse Document Frequency (IDF):
The inverse document frequency (IDF ) is a measure of how rare a word is in a document. Words like “the”,” a” show up in all the documents but rare words will not occur in all the documents of the corpus.
If a word appears in almost every document means it’s not significant for the classification.
IDF of a word is = log(N/n)
- N: total number of documents.
- n: number of documents containing a term (word)
TF-IDF Evaluates how relevant is a word to its sentence in a collection of sentences or documents.
Implementing TF-IDF with python:
With Tfidftransformer you will compute word counts using CountVectorizer and then compute the IDF values and only then compute the Tf-IDF scores. With Tfidfvectorizer we do all calculations in one step.
sklearn provides 2 classes for implementing TF-IDF:
Tfidftransformerwhere we need to compute word counts then compute IDF values and then compute the TF-IDF scores.Tfidfvectorizerhere all the steps are done in a single step.
Importing libraries :
import sklearn import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer
Implementation :
text = ["i love the NLP",
"NLP is the future",
"i will learn the NLP"]
vectorizer = TfidfVectorizer()
matrix = vectorizer.fit_transform(text)
count_array = matrix.toarray()
df = pd.DataFrame(data=count_array,columns = vectorizer.get_feature_names())
print(df)
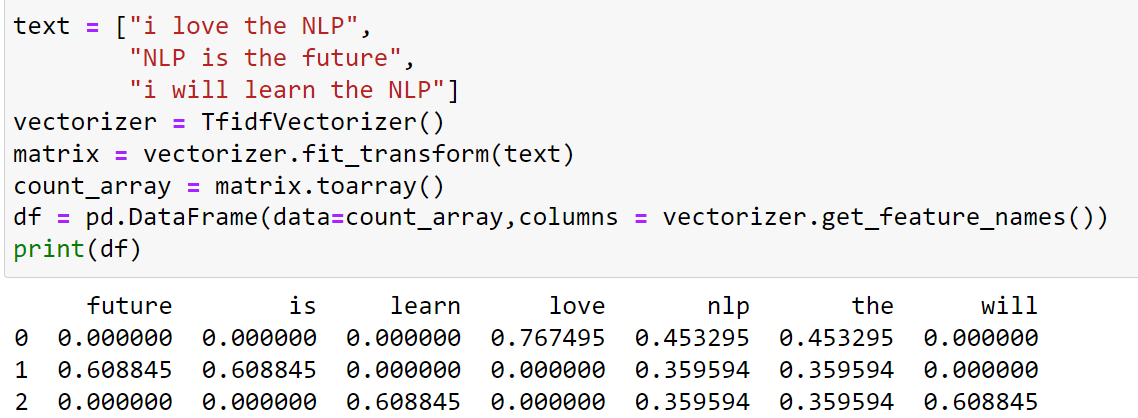
“NLP”, ”the” came in all the three documents hence it has a smaller vector value. ”love” has a higher vector value since it appeared only once in a document.
3. Word Embedding
Imagine I have 2 words “love” and “like”, these two words have almost similar meanings but according to TF-IDF and BOW model these two will have separate feature values and these 2 words will be treated completely different.
TF-IDF, BOW model completely depends on the frequency of occurrence, it doesn’t take the meaning of words into consideration, hence above-discussed techniques are failed to capture the context and meaning of sentences.
“I like you” and “I love you” will have completely different feature vectors according to TF-IDF and BOW model, but that’s not correct.
note: while working with some classification task we would have big raw data and if we keep considering every synonym as a different word it will generate humongous numbers of tokens and this will cause numbers of features to get out of control.
Word embedding is a feature learning technique where words are mapped to vectors using their contextual hierarchy. similar words will have identical feature vectors.
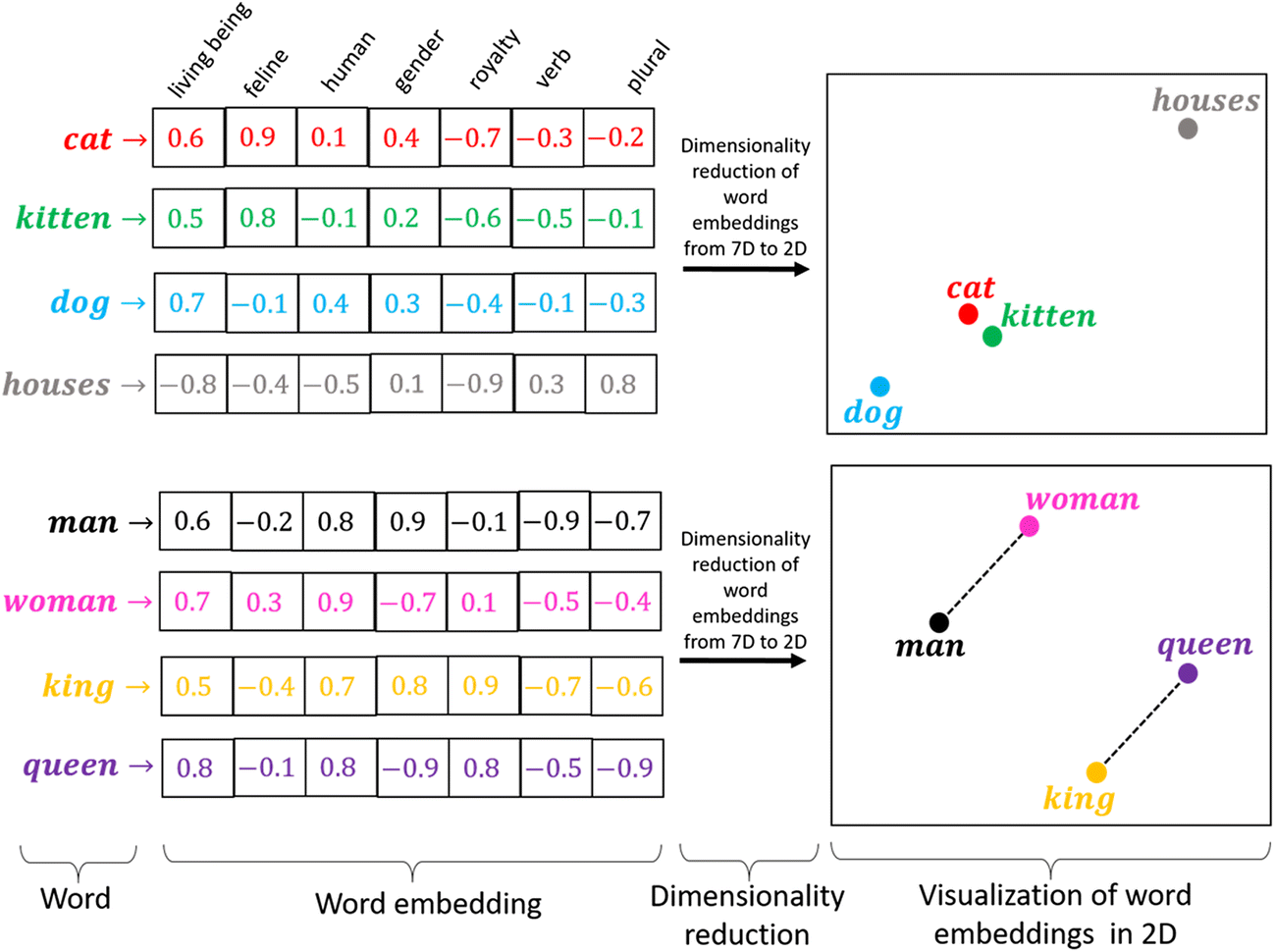
As you notice, cats and kitten are placed very closely since they are related.
word embedding is trained on more than 6 billion words using shallow neural networks.
word2vec has 2 algorithms
- CBOW
- Skip-Gram
don’t worry we don’t need to train word2vec, we will use pre-trained word vectors.
Implementing word2vec using python:
A pre-trained word vector is a text file containing billions of words with their vectors. we only need to map words from our data with the words in the word vector in order to get the vectors.
you can either download the word vector file or you can create a notebook using this link.
Source: Kaggle
Pre-trained word vector file come in (50,100,200,300) dimension. here dimension is the length of the vector of each word in vector space. more dimension means more information about that word but bigger dimension takes longer time for model training.
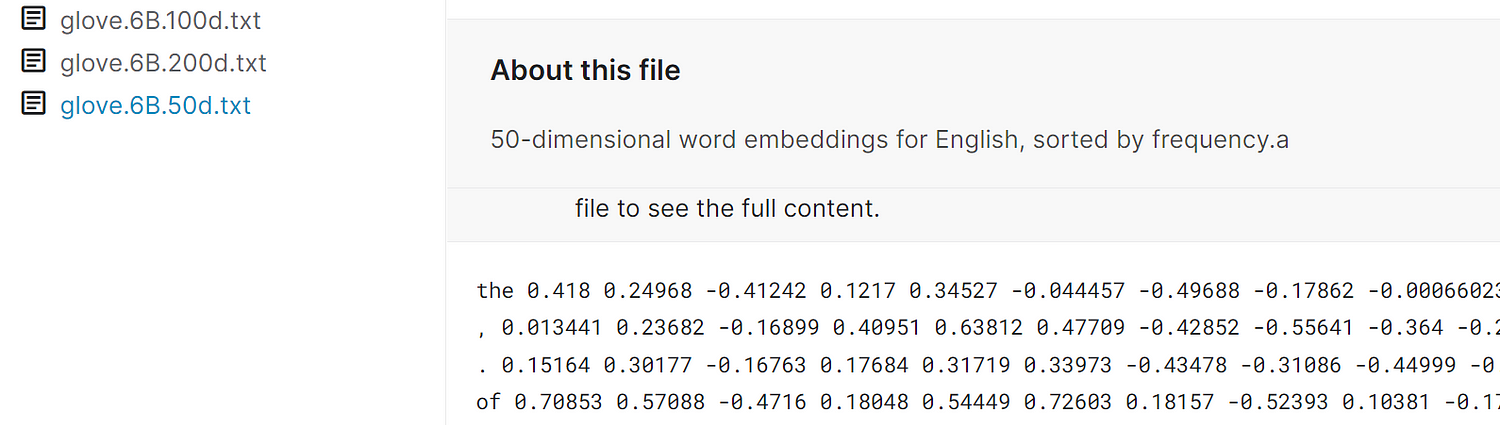
1. Loading glove word embedding of 100 dimensions into a dictionary:
import numpy as np
glove_vectors = dict()
file = open('../input/glove6b/glove.6B.100d.txt', encoding = 'utf-8')
for line in file:
values = line.split()
word = values[0]
vectors = np.asarray(values[1:])
glove_vectors[word] = vectors
file.close()
The Python dictionary makes mapping easy hence loading into the dictionary is always preferable.
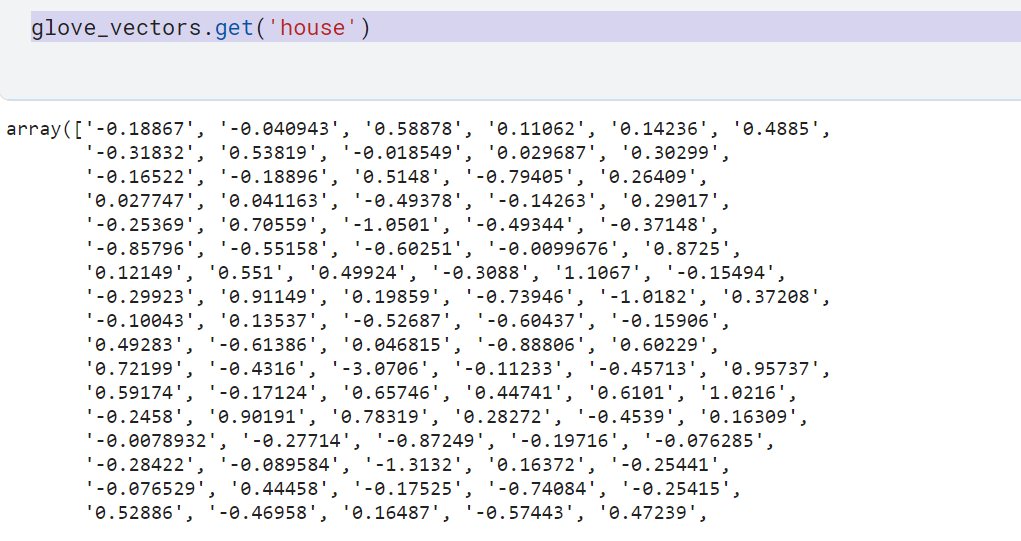
- we can use the
get()method toglove_vectorsto get the vectors
glove_vectors.get('house')

we divide the vectors by the number of words in that particular sentence/document for normalization purposes.
2. Creating a function that takes every sentence and returns word vectors:
vec_dimension = 100
def get_vec(x):
arr = np.zeros(vec_dimension)
text = str(x).split()
for t in text:
try:
vec = glove_vectors.get(t).astype(float)
arr = arr + vec
except:
pass
arr = arr.reshape(1,-1)[0]
return(arr/len(text))
document:
x = ['I love you',
'I love NLP and i will try to learn',
'this is word embedding']
features = get_vec(x)
features
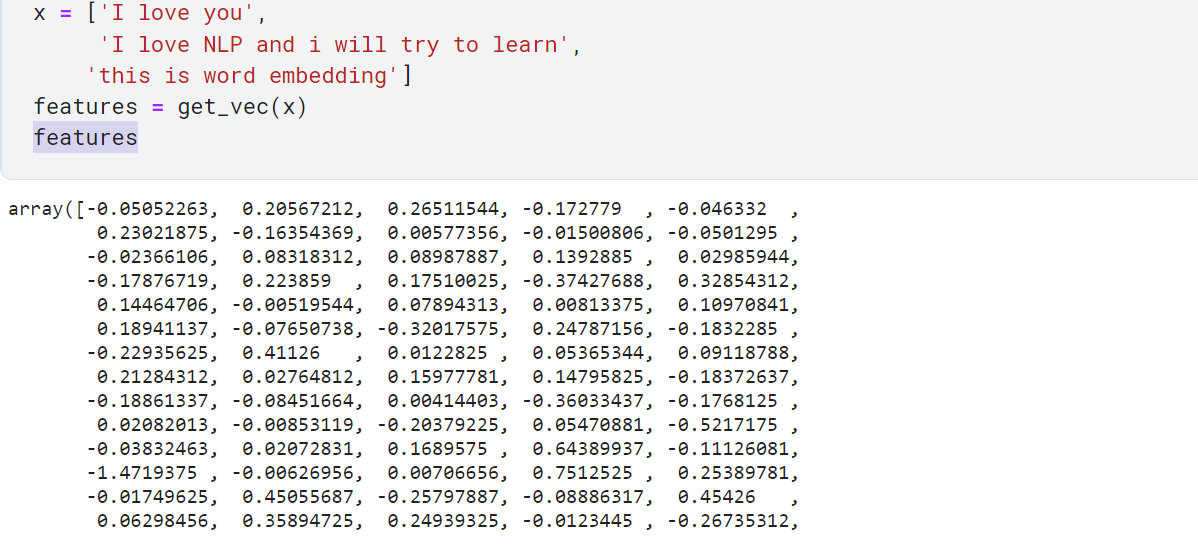
These numbers are the features of document x, the length of features is 100 since we have used 100 dimensions.
download notebook using this link.
EndNote
In this article, we have seen various Features Extraction techniques. we discussed the Idea of Bag of Words and the problem with the BOW model then we saw the concept of n-grams and how to use n-grams in the BOW model in python. we discussed the TF-IDF model and then discussed the Word-Embedding using pre-trained features in python.
All these feature extraction techniques are easily available in the sklearn package. for the word embedding, we can use pre-trained word2vec features as we have discussed.
In the next article, we will see feature extraction in the action. we will train a machine learning model that will be able to classify Spam emails.
If you have any suggestions or queries for me write to me on Linkedin.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A data enthusiast exploring the leading technologies related to the data





Thats amazing! , I learned a lot from Analytics Vidhya Thank you so much Abhishek Jaiswal and Analytics Vidhya owner.