This article was published as a part of the Data Science Blogathon.
An end-to-end guide on Text generation using LSTM

Hey Folks!
In this article, we are going to talk about text generation using LSTM with end-to-end examples. we will also look at concepts related to LSTM as a quick revision.
In the next generation, we predict the next character of a given word of a sequence. Text data can be seen as a sequence of words or a sequence of individual data. For the prediction of sequence, we have used deep learning models like RNN/LSTM/GRU.
I have already written a very detailed article on the idea of RNN then I discussed why RNN is not practical and explained RNN and GRU with examples. you can refer to this link.
Table of Contents
- Introduction to LSTM
- Why does RNN fail?
- Understanding LSTM architecture and various Gates
- The idea of Text Generation
- Implementation of Text Generation using LSTM
Introduction
Text generation can be considered a very important feature of AI-based tools. it comes very useful in machines which are supposed to become more interactive towards humans. smart gadgets like smart-speakers, home assistants use text generation in some forms.
Use cases of Text-Generation
- Search engines
- Chatbots
- Text summarize
- Question answering
Why RNN isn’t Practical for Text Generation?
RNN has a big problem of vanishing and exploding gradients. hence RNN can’t hold longer sequential information and in the Text-generation task, we particularly need a model that can memorize a long sequence of data. for this purpose LSTM came into the picture.
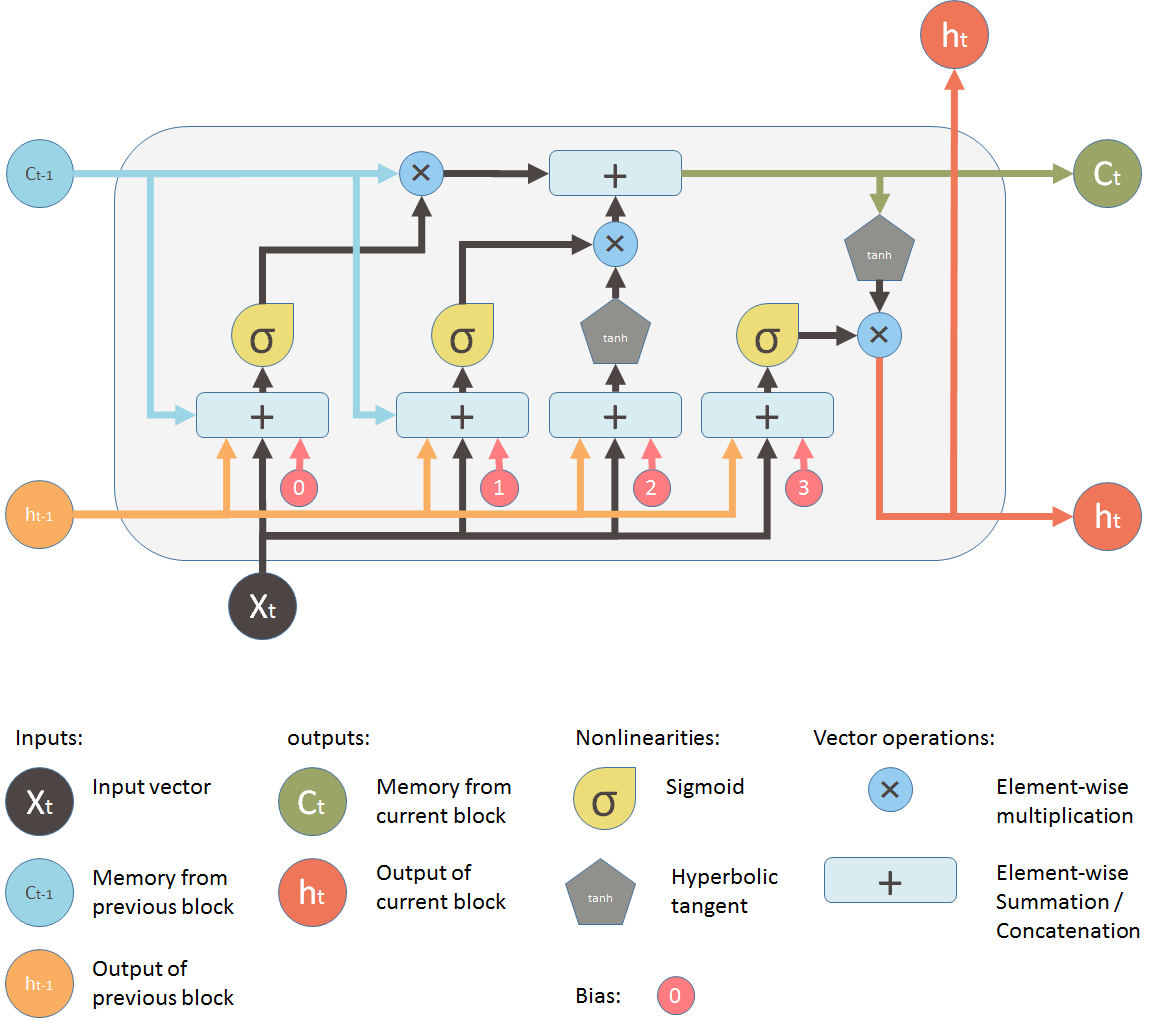
LSTM (Long Short Term Memory)
As we know that RNN can’t hold /memorize sequential data for a long time and begins to forget the previous inputs and new input comes. In order to fix this problem, LSTM is designed with various gates.
LSTM solves the problem of short-term memory learning by using different types of gates.
When a new input comes in RNN, it modifies the existing information without deciding if the incoming input is important or not, whereas in the case of LSTM gates are available to allow only important inputs to modify the existing information.
In LSTM gates decide what data to be ignored and what to be feed-forward for the training. there are 3 gates in LSTM:
- Input Gate
- Output Gate
- Forget Gate

Forget Gate
This gate is responsible for selecting relevant information and discarding irrelevant information. after selecting relevant information it is passed through the input gate.
First, the information from the current state and previous hidden state is passed through the activation function. here will be the sigmoid activation function. Sigmoid activation function return value between 0 to1.a value closer to 0 means current information should be ignored otherwise it should be passed through the input gate.
Input Gate
This gate is responsible for adding information to the model by using the activation function sigmoid. Using the activation function tanhcreates an array of information that is passed through the input gate. the array of information contains values ranging from -1 to 1 and a sigmoid function filter and maintain what information should be added to the model and what information should be discarded.
Output Gate
Output Gate is responsible for generating the next hidden states along with cell states that are carried over the next time step. It creates a hidden state using the activation function tanhand its value ranges from -1 to 1.
The Idea of Text Generation
Text generation is nothing but a continuous series of next-word predictions. as we already know that text data is a sequence of words, using these sequences we can predict the next word.
Implementing Text Generation
There are steps various steps listed for text generation:-
- Load the necessary libraries
- Load the textual- data
- Perform text-cleaning if needed
- Data preparation for training
- Define and train the LSTM model
- Prediction
Loading necessary libraries
- libraries for data handling
import pandas as pd
import numpy as np
import string, os
import warnings
warnings.filterwarnings("ignore")
warnings.simplefilter(action='ignore', category=FutureWarning)
- loading deep learning libraries
# set seeds for reproducability from tensorflow import set_random_seed from numpy.random import seed set_random_seed(2) seed(1) # keras module for building LSTM from keras.preprocessing.sequence import pad_sequences from keras.layers import Embedding, LSTM, Dense, Dropout from keras.preprocessing.text import Tokenizer from keras.callbacks import EarlyStopping from keras.models import Sequential import keras.utils as ku
Loading the Dataset
We will use Newyork’s time comments dataset available on Kaggle. you can download the dataset or you can even create a new Kaggle notebook using this dataset.
The dataset contains various articles and comments. Our objective is to load all the articles as headlines and merge them into a list.
# Loading the all headlines as a list
curr_dir = '../input/'
all_headlines = []
for filename in os.listdir(curr_dir):
if 'Articles' in filename:
article_df = pd.read_csv(curr_dir + filename)
all_headlines.extend(list(article_df.headline.values))
break
all_headlines = [line for line in all_headlines if line!= "Unknown"] print(all_headlines[:10])

We have a total of 829 headlines and we will use these headlines to generate text.
Dataset Preparation
For Dataset Preparation our first task will be to clean the text data which includes removing punctuations, lowercasing words, etc.
Data Cleaning
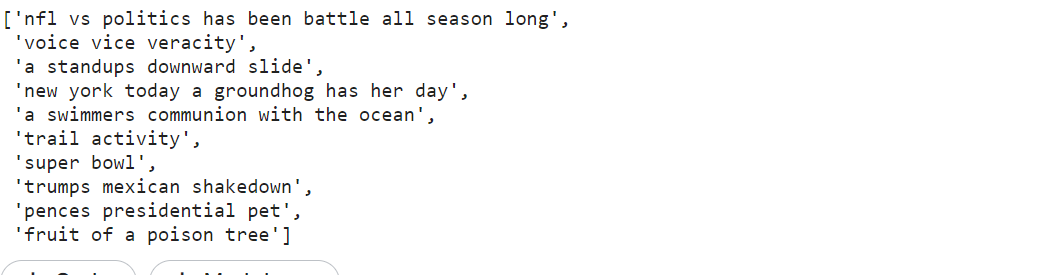
We defined a function that takes a single headline at a time and returns the cleaned headline. Using iteration we have passed each headline and made a list of cleaned data corpus.
def clean_text(txt):
txt = "".join(t for tin txt if t not in string.punctuation).lower()
txt = txt.encode("utf8").decode("ascii",'ignore')
return txt
corpus = [clean_text(x) for x in all_headlines] print(corpus[:10])
Generating n-gram Sequence for training
In NLP language model requires sequential input data, and input word/token must be numerical. Here we are generating n-grams in order to train our model for next word prediction.
tokenizer = Tokenizer()
def get_sequence_of_tokens(corpus):
## tokenization
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
## convert data to a token sequence
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
return input_sequences, total_words
inp_sequences, total_words = get_sequence_of_tokens(corpus) print(inp_sequences[:10])

As you see that inp_sequence is an n-gram sequence that is required for training next-word prediction. we had 829 headlines and using the n-gram concept we have now 4544 rows.
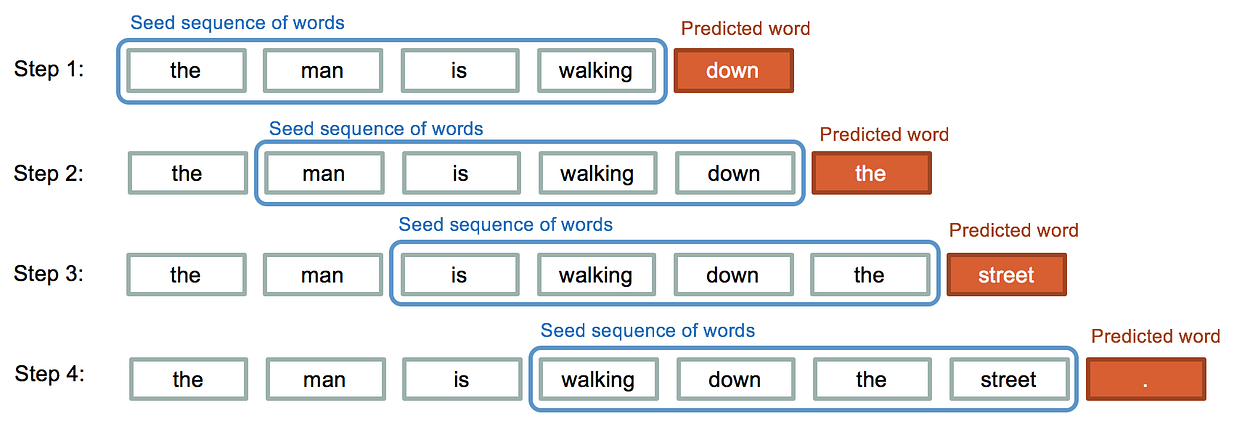
You can relate the inp_sequences with this picture where you can clearly see that in every step we add a token to the Seed sequence for training.
Padding the Sequences
The inp_sequence we just made have variable sequence length, which is not favorable for training, using padding we make every sequence of having the same length.
def generate_padded_sequences(input_sequences):
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
predictors, label = input_sequences[:,:-1],input_sequences[:,-1]
label = ku.to_categorical(label, num_classes=total_words)
return predictors, label, max_sequence_len
predictors, label, max_sequence_len = generate_padded_sequences(inp_sequences)
predictors: these are tokens that will be used as input for predicting the next word.label:is the next word to be predicted.max_sequence_len:is the sequence length.pad_sequence:provided by Keras is used to pad an array of tokens to a given length.- In this case,
max_sequence_lenis 17.
Model Creation
So far we have prepared the data for training. now in this step, we will create an LSTM model that will take predictors as input X and labels as input y.
A quick reminder on Layers in Keras:-
- Input Layer: This is responsible for taking input sequence.
- LSTM Layer: It calculates the output using LSTM units and returns hidden and cell states. In our case we have added 100 units in the layer, that can be fine-tuned later.
- Dropout Layer: This layer is responsible for regularisation which means it prevents over-fitting. this is done by turning off the activations of some neurons in the LSTM layer.
- Output Layer: This Computes the probability of our prediction.
def create_model(max_sequence_len, total_words):
input_len = max_sequence_len - 1
model = Sequential()
# ----------Add Input Embedding Layer
model.add(Embedding(total_words, 10, input_length=input_len))
# ----------Add Hidden Layer 1 - LSTM Layer
model.add(LSTM(100))
model.add(Dropout(0.1))
# ----------Add Output Layer
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
return model
model = create_model(max_sequence_len, total_words) model.summary()
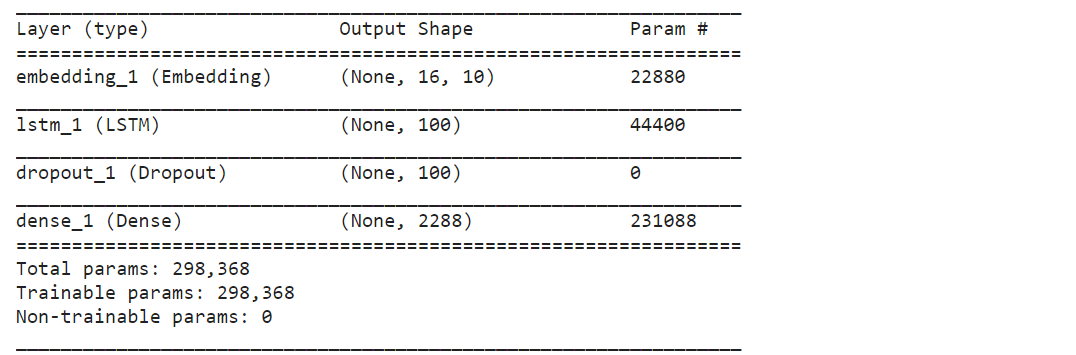
Training the model
After building the model architecture we can train the model using our predictors (X_train) and label(y_train).100 epochs should be enough.
model.fit(predictors, label, epochs=100, verbose=5)
Text Generation (Prediction)
Awesome!!
We have trained our model architecture and now it’s ready to generate text. We need to write a function to predict the next word based on the input words. We also have to tokenize the sequence and pad it with the same sequence_length we provided for training, and then we will append each predicted word as a string.
def generate_text(seed_text, next_words, model, max_sequence_len):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word,index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " "+output_word
return seed_text.title()
seed_text: it’s the initial words that will be passed for text generation.predict_classes:it will return the token id for the predicted word.predicted: Its token id for predicted word and this will be converted back into a word using the dictionarytokenizer.word_index .items().next_wordsIt’s the number of next words we want to be predicted.
Prediction
Calling the function generate_textwill generate text.generate_text function takes initial words and number of words to be predicted, model name, and sequence length.
print (generate_text("india and pakistan", 3, model, max_sequence_len))
print (generate_text("president trump", 3, model, max_sequence_len))
print (generate_text("united states", 4, model, max_sequence_len))
print (generate_text("donald trump", 2, model, max_sequence_len))
print (generate_text("new york", 3, model, max_sequence_len))
print (generate_text("science and technology", 5, model, max_sequence_len))

Conclusion
In this article, we have discussed the LSTM model with its architecture and then we discussed the Idea of the text-generation and we implemented the text-generation using the LSTM model.
Our trained model worked perfectly well but you can improve the model by:-
- Adding more data to be trained on
- Fine Tuning the model architecture, ie ( number of units, layers, etc).
- Fine Tuning the parameters like ( epochs, units, learning rate, activation function, etc)
Thanks for Reading !!
Feel free to hit me on my Linkedin if you have any suggestions or questions for me.
References
- https://iq.opengenus.org/text-generation-lstm/
- https://www.kaggle.com/shivamb/beginners-guide-to-text-generation-using-lstms
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A data enthusiast exploring the leading technologies related to the data






