This article was published as a part of the Data Science Blogathon.
Overview
Machine learning (ML) has a lot of potential for increasing productivity. However, the quality of the data for training ML models should be excellent to provide good results. Any ML algorithm provides excellent performance only when there is huge and perfect data fed for training. To get such quality data many organization works cooperatively. When we are taking data from different organizations, it is very important to maintain the confidentiality, privacy, and profit-sharing of data. This article will provide you with a clear vision of how and why PPML (Privacy-preserving machine learning) has become very important when companies shift to cloud environments or work cooperatively.
Introduction
Collecting massive volumes of data is a critical enabler for Artificial Intelligence (AI) approaches, and Machine Learning (ML), which is at the heart of AI, uses such data to create predictive models. However, to collect the data and to utilize it to find the patterns of behavior of data are two different things. Moreover, it comes with various difficulties to be handled by an individual or an organization which includes privacy concerns such as data breaching, financial loss, and reputational harm.
“Much of the most privacy-sensitive data analysis which majorly includes search algorithms, recommender systems, and adtech networks are driven by machine learning.” [1]
The goal of privacy-preserving machine learning is to bridge the gap between privacy while receiving the benefits of machine learning. It is a critical facilitator for the privatization of acquired data and adhering to data privacy laws. The core ideas of privacy-preserving machine learning are introduced in this article. This article shows how to use a combination of machine learning and privacy strategies to solve problems. Take a look at some of the tools that are accessible. This article aims to provide a complete understanding of privacy-preserving machine learning for a wide range of applications.
Table of Contents
- What is PPML?
- Need in today’s era
- Main four stakes of Privacy-preserving
- Data Privacy in Training
- Privacy in Input
- Privacy in Output
- Model Privacy
- PPML Techniques
- Differential Privacy
- Homomorphic Encryption
- Multi-party Computation
- Federated Learning
- Ensemble Privacy-Preserving Techniques
- Summary of various PPML Techniques
- PPML Tools
- PYSYFT
- Tensorflow Privacy
- CRYPTFLOW
- ML Privacy Meter
- CRYPTEN
What is PPML?
Privacy-Preserving Machine Learning is a step-by-step approach to preventing data leakage in machine learning algorithms. PPML allows many privacy-enhancing strategies to allow multiple input sources to train ML models cooperatively without exposing their private data in its original form as given in the following Figure 1.
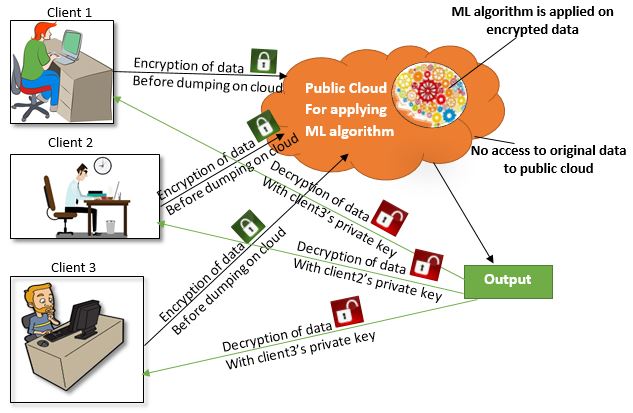
Figure 1: the concept of PPML
Need in Today’s Era
With the benefits of machine learning applications always there is a risk of data privacy; For example, if we consider applications for healthcare or intrusion detection. Cyber-attacks and data leakages are becoming more regular and expensive to handle. Cybercriminals are drawn to large sets of data held for training reasons because they can steal data that can be used to identify people or other valuable information that can be sold. Furthermore, ML models themselves pose a vulnerability since sensitive data may be extracted from them. For example, a research paper [2] demonstrates how to determine if a record was utilized in the training dataset for a certain ML model. They put their method to the test on Amazon and Google Cloud machine learning systems, with results of 74% and 94% accuracy, respectively.
In this setting, protecting personally identifiable information (PII), or data that can be used to identify a specific individual, is a major problem. In addition to securing PII from prospective leaks, companies must comply with several data protection requirements, such as the General Data Protection Regulation (GDPR) in Europe. In the case of a GDPR violation, the penalties might be substantial. Cyber-attacks put the companies collecting data, as well as the end-users to whom the data pertains, at jeopardy of legal, financial, and reputational consequences. It would not be sufficient to just remove PII from a dataset, such as names and addresses, because other quasi-identifiers may be used to pinpoint a specific individual in the collection. For example, William Weld, the governor of Massachusetts, was re-identified using apparently anonymized health data records containing only his birth date, gender, and ZIP code in a study done by Latanya Sweeney [3].
Privacy-preserving by augmenting ML with different strategies that protect data privacy, ML strives to address these challenges. These techniques include perturbation techniques like differential privacy, cryptographic approaches like homomorphic encryption and multi-party computing, and machine learning-specific approaches like federated learning.
The current cloud-based scenario for machine learning, security of various assets of any organization, and security of data gave birth to the privacy-preserving ML approach. To deal with this PPML approach, there will not be a single solution to all the types of applications. The various application requires various kind of privacy attention. Furthermore, we must strike a balance between scenario-specific concerns and the requirement to develop platform-independent and robust methodologies. While research on privacy-preserving machine learning has exploded in recent years, there is still a gap between theories and their applications to real-world scenarios.
Main four stakes of Privacy-Preserving
1 Data Privacy in Training
The assurance that a malicious party will not reverse-engineer the training data. While gathering information about training data and model weights is slightly more difficult than gathering information from plain-text (the technical term for unencrypted) input and output data, recent research has shown that reconstructing training data and reverse-engineering models is not as difficult as one might think.
Paper [4] Calculates how rapidly generative sequence models (e.g., character language models) can memorize unusual information within a training set. Carlini and Wagner use the Penn Treebank to train a character language model with a “secret”: “the random number is ooooooooo,” where ooooooooo is a (false) social security number. They demonstrate how discovering a secret that they have hidden inside their copy of the Penn Treebank Dataset may be used to their advantage (PTD). They calculate the amount of memory in the network by training a character language model on 5% of the PTD. When the test set loss is lowest, memorization is at its peak. This is when the secret is at its most widely known.
2 Privacy in Input
The assurance that other parties, including the model developer, will not be able to see a user’s input data.
3 Privacy in Output
The assurance that the output of a model is only accessible to the client whose data is being inferred upon.
4 Model Privacy
The assurance that a hostile party will not be able to steal the model. Many organizations supply predictive skills to developers via APIs or, more recently, downloaded software, and AI models might be their bread and butter. The final of the four stakes to examine is model privacy, which is crucial to both user and company interests. If their competitors can readily imitate their models, companies will have little incentive to create innovative goods or spend money on upgrading AI skills (an act that is not straightforward to investigate).
Many firms’ main products and intellectual property are machine learning models; therefore, having one stolen is dangerous with serious financial consequences. Furthermore, a model can be directly stolen or reverse-engineered using its outputs [5].
PPML Techniques
These are the methods used to ensure that the data cannot be stolen by a third party. As a result, the tactics listed below are used to counteract various assaults.
o Differential Privacy
Differential privacy is a type of privacy that allows you to provide relevant information about a dataset without releasing any personal information about it. Even if an attacker has access to all entries in a dataset, the result of a differentially-private operation cannot be used to link a specific record to a person, thanks to this method. In other words, the presence of an individual’s record in the dataset has no (substantial) impact on the analysis’ outcome. As a result, the privacy risk is basically the same whether or not a person participates in the dataset. Differential privacy is achieved by adding random noise to the result, which may be done via a variety of differentially-private processes such as the Laplace, exponential, and randomized response approaches.
o Homomorphic Encryption
Homomorphic Encryption (HE) is a cryptographic method for calculating encrypted data that results in a decrypted output identical to the original unencrypted input’s output. The following is a sample example of how the approach is used:
a) The data owner encrypts the data using a homomorphic function and shares the output with a third party who is responsible for completing a certain calculation;
b) The third-party compute the encrypted data and provides the output, which is encrypted due to the encrypted input data;
c) The data owner decrypts the output, receiving the outcome of the calculation on the original plain-text data.
The unencrypted input and output are not accessible to the third party throughout this procedure.
o Multi-party Computation
MPC (Multi-Party Computation) is a system that allows many participants to calculate a function without disclosing their private inputs. The parties are self-contained and distrustful of one another. The fundamental concept is to allow computation to be performed on private data while keeping the data private. MPC ensures that each participant only learns from the outcome and their contribution as much as possible.
We’ll go through various secure MPC strategies shortly below. [25] is a good place to start for further information.
The cryptographic protocol garbled circuits are commonly used for two-party secure computing on Boolean functions (circuits). The protocol’s steps are as follows:
• The first party, Alice, encrypts (or garbles) the function (circuit) and sends it to the second party, Bob, along with her encrypted input;
• Bob encrypts his input with the help of Alice using oblivious transfer, in which Alice and Bob transfer some information while the sender is unaware of what information has been transferred;
• Bob evaluates the function using both encrypted inputs and gets the encrypted output;
Many MPC techniques use secret sharing as a strategy. For example, the (t, n)-secret sharing technique divides the secret s into n shares and assigns each participant a share. When t shares are merged, the secret s may be reconstructed, but when any t-1 of the shares are combined, no information about s is exposed. To put it another way, the secret is divided so that any group of at least t people can reconstruct it, but no group of less than t can.
Both MPC and homomorphic encryption are effective privacy approaches, but they come at a high cost for communication and processing.
o Federated Learning
Federated learning allows ML processes to be decentralized, lowering the amount of information exposed from contributor datasets and reducing the danger of data and identity privacy being compromised. The basic idea behind federated learning is that a central machine learning (ML) model M owned by a central authority (e.g., a company) can be further trained on new private datasets from data contributors by having each contributor train locally with its dataset and then updating the central model M (i.e., updating the model’s parameter).
Federated learning, in particular, operates as follows:
(1) A group of n participants (data contributors) receives the central model M;
(2) Each participant updates the model M locally by training it on its own local dataset Zl, yielding a new local parameter l.
(3) The central authority receives each participant’s update l;
(4) The central authority combines each participant’s local parameters to form a new parameter that is used to update the central model. This procedure can be continued until the primary model is well-trained.
o Ensemble Privacy-Preserving Techniques
There is no silver bullet when it comes to achieving privacy in machine learning. The level of privacy given by the tactics described here is determined by several factors, including the machine learning algorithm used, the adversary’s abilities and resources, and counting. As a result, to obtain higher degrees of privacy, it may be necessary to combine or assemble several privacy-preserving ML techniques.
Summary of various PPML Techniques
Each privacy-preserving machine learning approach aims to achieve distinct privacy goals while hardening an ML infrastructure and reducing the vulnerability surface exposed to an attacker. Table 1 summarizes the key features of the privacy-preserving ML approaches reviewed above, including their privacy aims, strengths, and limitations.
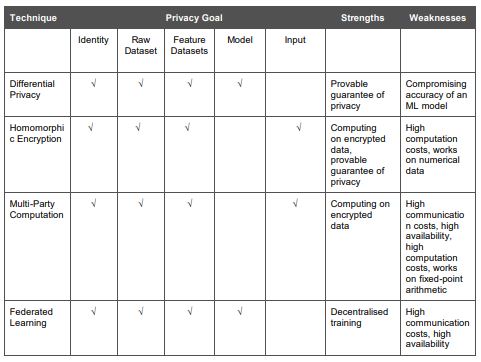
Table 1 source: Overview of Privacy-Preserving Techniques[6]
Differential privacy protects the privacy of distinct datasets in an ML process and provides a proven assurance of privacy. However, striking the correct balance between anonymized data value and privacy, which are inversely connected, can be difficult.
Homomorphic encryption allows you to operate with encrypted data while keeping the original datasets’ functionality; nevertheless, its scope is fairly limited, and scalability might be a problem.
MPC allows several people to work together to solve a problem by exchanging encrypted data. This may be used to (1) train a common machine learning model without revealing private information, resulting in identity, raw dataset, and feature dataset privacy, and (2) calculate the output of an ML model by having the parties share their encrypted inputs, resulting in input privacy. The flexibility of working with encrypted data, like HE, comes at a cost in terms of communication, and the necessity to update the model or apply an ML approach might add to the performance overhead. Furthermore, the requirement of continuous availability of computing parties may pose scalability issues, while the usage of fixed-point arithmetic limits the scope of ML’s applicability.
Federated learning overcomes the drawbacks of centralized model training by allowing models to be trained locally without needing the exchange of data contributor datasets, ensuring identity, raw dataset, and feature dataset privacy. The network of devices used to train the model, on the other hand, necessitates high communication costs and device availability during training.
PPML Tools
o PYSYFT
PySyft is a Python-based open-source machine learning toolbox that is safe and private. It’s part of the Open Mined program, which develops AI frameworks
and technologies that respect people’s privacy. Different privacy-preserving techniques are supported by the library, including differential privacy, HE, MPC, and federated learning. Popular deep learning frameworks such as PyTorch, TensorFlow, and Keras are also extended by PySyft.
o Tensorflow Privacy
TensorFlow Privacy (TFP) is a Python toolbox for training and generating differentially private machine learning models. The library is built on Google’s TensorFlow (https://www.tensorflow.org/), an open-source framework for traditional machine learning training that ignores privacy concerns. One of the library’s key privacy-preserving ML methodologies is to train an ML model using differential private SDG. TFP may also be used to calculate the privacy guarantees offered by the differential private mechanism of choice, which can be used to (1) compare ML models in terms of privacy and (2) account for utility loss when choosing one model over another.
Visit the GitHub site to get started with the TFP library. https://github.com/tensorflow/privacy
o CRYPTFLOW
CrypTFlow is a system that uses concepts from programming languages and MPC to give a solution for securely querying ML models.
o ML Privacy Meter
Integrating privacy safeguards into the ML process used to construct the model is just as critical as assessing the resilience of an ML model against specific assaults.
ML Privacy Meter is a Python package that uses Google’s TensorFlow to assess privacy threats in machine learning models. Under both white box and black box adversary models, the tool may be used to develop membership inference attacks. After that, the program may calculate the privacy risk ratings based on the adversary model selected. The risk scores may be viewed as a measure of how accurate such attacks on the model of interest are. Finally, the program can visualize the results and generate privacy reports.
It is recommended to visit the GitHub repository for further details about the utility.
https://github.com/privacytrustlab/ml_privacy_meter
o CRYPTEN
CrypTen is a privacy-preserving machine learning framework based on research. The program is based on PyTorch, an open-source machine learning platform. The framework now supports MPC, with the possibility of adding HE (Homomorphic Encryption) support in the future.
Read more articles on Machine Learning on our blog.
References
[1] C. F. Kerry, “Protecting privacy in an ai-driven world,” 2020. Last accessed 31 January 2022, https://www.brookings.edu/research/ protecting-privacy-in-an-ai-driven-world/ [2] R. Shokri, M. Stronati, C. Song, and V. Shmatikov, “Membership inference attacks against machine learning models,” in 2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, May 22-26, 2017, pp. 3–18, IEEE Computer Society, 2017. [3] L. Sweeney, “k-anonymity: A model for protecting privacy,” Int. J. Uncertain. Fuzziness Knowl. Based Syst., vol. 10, no. 5, pp. 557–570, 2002. [4] Carlini, Nicholas, et al., The Secret Sharer: Evaluating and testing unintended memorization in neural networks (2019), 28th USENIX Security Symposium (USENIX Security 19). [5] Tramèr, Florian, et al., Stealing machine learning models via prediction APIs (2016), 25th USENIX Security Symposium (USENIX Security 16). [6]https://www.alexandra.dk/wp-content/uploads/2020/10/Alexandra-Instituttet-whitepaper-Privacy-Preserving-Machine-Learning-A-Practical-Guide.pdf
To know more about the author kindly visit her LinkedIn page: https://in.linkedin.com/in/dulari-bhatt-283952144
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Dr. Dulari Bhatt is Master Trainer at Edunet Foundation. She is having 12 years of experience in academia. Her main research interests are in the field of Big Data Analytics, Computer Vision, Machine Learning, and Deep Learning. She has authored 3 technical books and published several research papers in reputed international journals. She is an active writer in Analytics Vidhya and OSFY magazine. She has received a gold category award from GTU for spreading IPR awareness. Several times winner of Data Science Blogathons..






Amazing Article. It's a really good article for a person from another branch.