Introduction
Sentiment Analysis has been a very popular activity since the beginning of Natural Language Processing (NLP). It belongs to a subtask or application of text classification, identifying sentiments or subjective information from different texts.
Sentiment Analysis means to identify the view or emotion behind a situation. It means to analyze and find the emotion or intent behind a piece of text or speech or any mode of communication.
Common use cases of sentiment analysis include monitoring customer feedback, targeting individuals to improve their service, and tracking how a change in product or service affects how customers feel. It also helps to track customer sentiment over time. From opinion polls to creative marketing strategy, this platform has completely redefined the way businesses operate, which is why this is an area every data scientist should be well aware of.
In this article, we will be training the sentiment analysis model on a custom dataset using transformers.
Table Of Contents
1 Understanding the Problem statements
2 Import Library
3 Data Preparation
4 Model Building: Sentiment Analysis
5 Find the sentiments on test data
6 Conclusion
Understanding the Problem Statement
Let’s go through the problem statement as well it is very important to understand the purpose before working on the database. The problem statement is as follows:
The purpose of this activity is to detect hate speech in tweets. For simplicity, we say that a tweet contains hate speech when it is associated with racial or sexual prejudice. Therefore, the task is to distinguish racist or sexual tweets from other tweets.
Officially, when a training sample is provided for tweets and labels, where the label ‘1’ means the tweet is discriminatory / gender and the label ‘0’ means the tweet is not racist/sexist, you intend to predict the labels on the test data provided.
You can access the dataset here: dataset.
The columns present in our dataset are :
1. id: unique id of the tweet
2.label : 0 or 1 (positive and negative)
3. tweet: text of the tweet
Steps to be followed
Initially, we will start with importing and installing all the necessary libraries. After the importing is done we will load the data using pandas.
In the next step data preprocessing will be done. In the case of the transformers, DistilBert tokenizer does all the preprocessing like conversion of text to the same case, removing the punctuations, removing all the stop words. You will get to know more about tokenization further in the article.
The preprocessed data is then used to train the DistilBert model and the trained model is then used to find the sentiments on the test data.
Installation:

Installation of transformer library
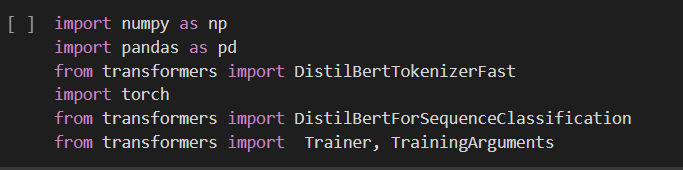
Import Necessary libraries:
Data Preparation :
Importing test, train, and sample data :

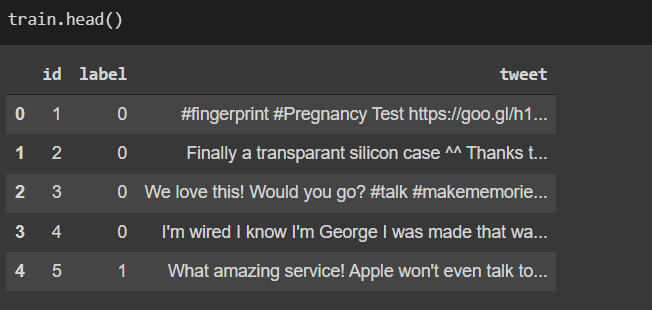
We are only interested in the column label and tweet. Tweet being input column ‘and label is the output variable. The label contains 0 and 1 . with 0 being the positive tweet and 1 being the negative tweet.
That’s why we will be dropping the id column.

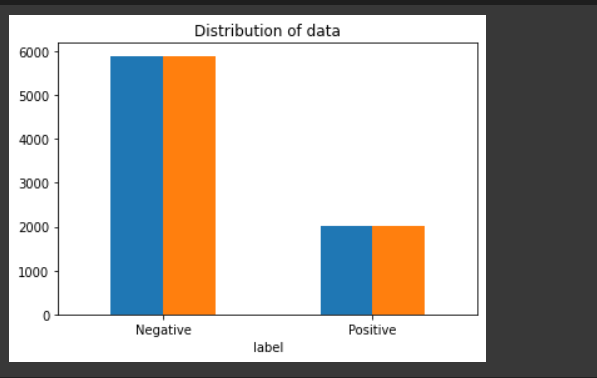
Distribution of positive and negative labels in the data :

Output:
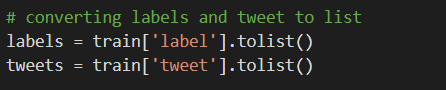
We will need to convert the tweet and labels column in the form of a list so that we can input them to the tokenizer that we will see the further steps.
Tokenization and Encoding of data
About the tokenizer:
The tokenizer that we will be using is DistillBert tokenizer fast. DistilBertTokenizerFast is identical to BertTokenizerFast and runs end-to-end tokenization: punctuation splitting and wordpiece.
The parameters that are present in DistilBertTokenizerFast are :
( vocab_filedo_lower_case = Truedo_basic_tokenize = Truenever_split = Noneunk_token = ‘[UNK]’sep_token = ‘[SEP]’pad_token = ‘[PAD]’cls_token = ‘[CLS]’mask_token = ‘[MASK]’tokenize_chinese_chars = Truestrip_accents = None**kwargs )
The method splits the sentences into tokens, adds the [cls] and [sep] tokens, and also matches the tokens to id.
Tokenization:


So in tokenizer, we will give a list of tweets as the input and will get the token ids in return that we will input in the model.
Padding, Truncation, and all of the preprocessing are done in the DistillBert tokenizer itself.
Now since we are using PyTorch to implement this we will convert our data to tensors.
So for converting the data into tensor we will be using the twitterDataset class that is implemented below:
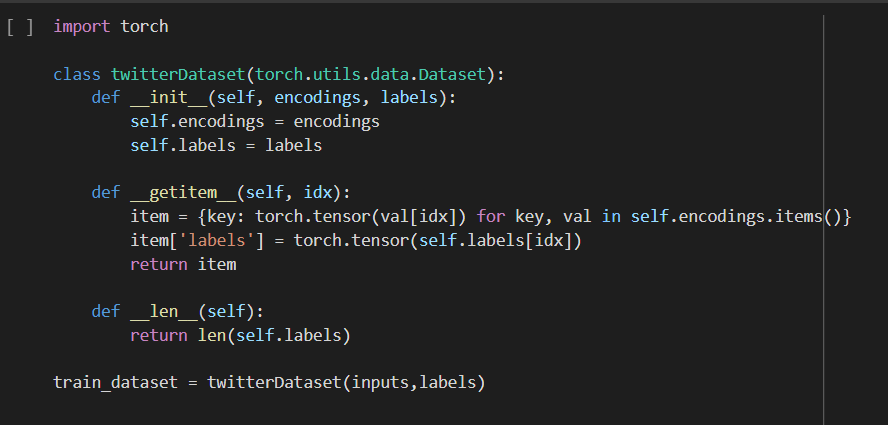
Output:

The output of this is a dictionary containing 3 key-value pair
Input id’s: This contains tensors of integers where each integer represents the word from the original sentence.
Attention Mask: It is simply an array of 1’s and 0’s indicating which tokens are padding and which aren’t.
Labels: target variables
Model Building: Sentiment Analysis
About the Model :
We will use the Distillbert model for our training purposes. BERT uses Transformer, an attention-grabbing method that learns the contextual relationships between words (or small words) in a text. Transformer combines two distinct modes – a text input that reads text input and a video that generates a working forecast. Since the purpose of BERT is to model the language, only the encoding method is required.
Dilbert is a small, fast, cheap, and easy Transformer model trained by Distilling base BERT. It has 40% fewer parameters than Bert-base based, 60% faster performance while saving more than 95% of BERT performance as measured in the GLUE language comprehension benchmark.
For in-depth knowledge of Bert, you can access this link

Enable GPU if it’s available

Trainer Class for Training:
The Trainer class provides an API for feature-complete training in PyTorch for most standard use cases.
Before instantiating your Trainer, create a TrainingArguments to access all the points of customization during training.
The API supports distributed training on multiple GPUs/TPUs, mixed-precision through NVIDIA Apex, and Native AMP for PyTorch.
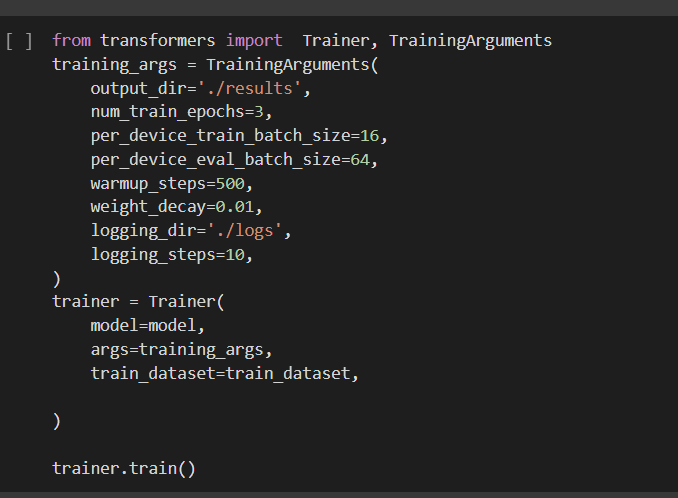
Output:
Checking the model on test data and finding the polarity of the sentiment:
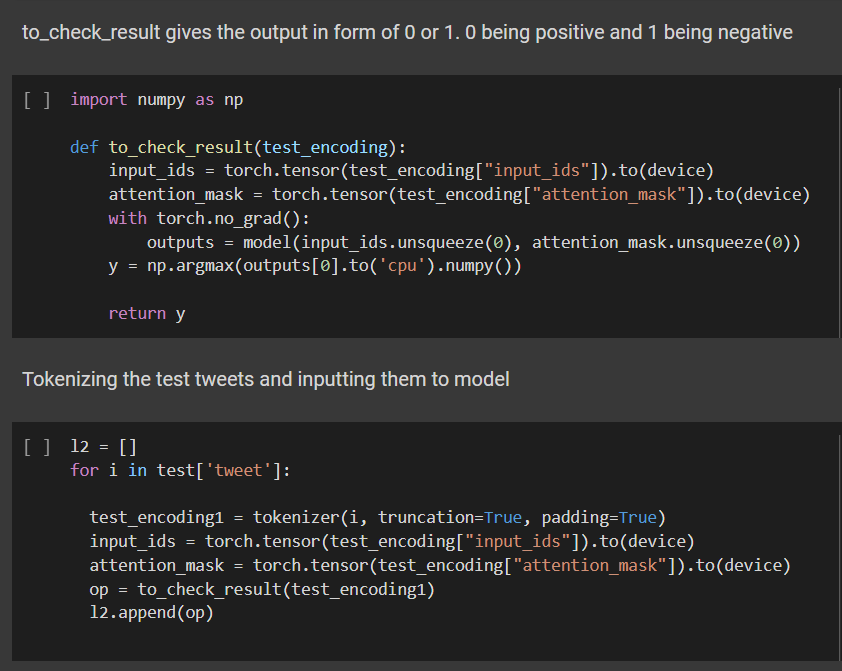
l2 list contains the output sentiment of all the tweets in the test data.
Conclusion
To get a better result we can use BERT large model. The difference between BERT base and BERT large is in the number of encoder layers. The BERT base model has 12 embedded coding layers on top of each other and the larger BERT has 24 layers of embedded layers on top of each other. The BERT base has 768 hidden layers and the larger BERT has 1024 hidden layers.
We can also use the Roberta model to find a better result. Robustly optimized BERT approach Roberta, is a retraining of BERT with improved training methodology, 1000% more data, and compute power
Without a doubt, BERT is a remarkable breakthrough in the field of NLP, and the fact that it is easy to implement and fast adds the advantages of exploring the algorithm and building models to solve many problems that work in the real world.




