This article was published as a part of the Data Science Blogathon.
Introduction
In the first part of the series, we saw some most common techniques which we daily use while cleaning the data i.e. text cleaning in NLP. I would recommend if you haven’t read it first read it, which will help you in text cleaning. The Link for the article is here. You can find the GitHub link here and start practicing and get your hand on the problem.
Most Common Methods for Cleaning the Data
- Removing HTML tags
- Removing & Finding URL
- Removing & Finding Email id
- Removing Stop Words
- Standardizing and Spell Check
- Chat word correction
- Remove the frequent words
- Removing the less frequent words
Removing HTML Tags
Whenever we extract data from blogs articles from different sites, the data is often written in a paragraph format. So while extracting the data, we sometimes have the HTML tags such as header, body, paragraph, strong, and many more.
We can easily remove the HTML tags from the text by using regular expressions. So the idea to build a regular expression where all the tags are removed is made in such a way where first the pattern will identify if the text has a “I had such high hopes for this dress 15 size or (my usual size) to work for me.” in them or not, and if they encounter this, the whole tag will be replaced with the space.
import re text = """
“I had such high hopes for this dress 15 size or (my usual size) to work for me.”
without_html = re.sub(pattern=r”, repl=’ ‘, string=text)
print(f”{without_html}”)

Removing & Finding URL
When we collect the data manually from the website, Wikipedia pages, or some blogs, there are often URL links in them. Sometimes they are important, but what if we don’t need them? There is an easy solution to it.
First of all, we will see if the data has any URL links in them or not with the help of the spacy library. The spacy library has an inbuilt function like_url which will detect if the data has any URL link in them or not.
import spacy
nlp = spacy.load("en_core_web_sm")
text = 'My email is http://abcgmail.com'
doc = nlp(text)
for token in doc:
if token.like_url:
print(token)
Once we know our data has URL links, let’s remove them from the text and clean the text. Here, we will split the sentence into words and find if the word has ht in them or not. If the word encounters ht, that word will be removed from the text. Here ht is the starting characters of the link.
text = 'Look at this link http://abcgmail.com for work purpose https://abd.com' text_sp = text.split() ans = ' '.join([i for i in text_sp if 'ht' not in i]) ans

Removing & Finding Email id
While working with Twitter or Instagram data, we often encounter the email id in the text. If we don’t remove the email id from the text first and remove the punctuations, it will create the problem as only @ will be removed, not the whole email id.
So, let’s first see how to find out if our text has an email id in them or not.
import spacy
nlp = spacy.load("en_core_web_sm")
text = 'My email is [email protected]'
doc = nlp(text)
for token in doc:
if token.like_email:
print(token)
Once we know we have email id in our data, let’s remove it here, we will, first of all, split the sentence into words and find if the word has @ in them or not. Suppose the word encounter @, then that word will be removed from the text.
text = 'My email is [email protected] for work purpose' text_sp = text.split() ans = ' '.join([i for i in text_sp if '@' not in i]) ans

Okay, so we saw how to remove the email id from the text using normal for loop. Let’s now see how to remove the spacy library’s email id. The spacy library has an inbuilt function, .like_email, which detects the email id from the text and makes our work easy.
import spacy
nlp = spacy.load("en_core_web_sm")
text = 'My email is [email protected]'
doc = nlp(text)
for token in doc:
if not token.like_email:
print(token)

Removing Stop Words
Stop words are a commonly used technique in the NLP pipeline, and while making any useful changes, they become an integral part of text cleaning in NLP. What is stop words? Stop words commonly occur in a language, for example, like, and, or, but, etc. They don’t hold any specific meaning in the text, so even if we remove the stop words from the text, it won’t degrade the quality of the text.
In some use cases, such as POS (Part of Speech tagging), we won’t be removing the stop words as they hold some valuable information about the POS, but when we are working with the word cloud mostly, we use the process of removing stop words to get a clear and concise idea. The stop words list is already combined in different languages here, and I am using the English language from the NLTK library.
Downloading the library and stopwords package
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
Now, let’s look at how stop words are removed from the corpus
text = "I had such high hopes for this dress 1-5 size to work for me."
STOPWORDS = set(stopwords.words('english'))
ans = " ".join([word for word in str(text).split() if word not in STOPWORDS])
ans

First, let’s see which words are in the stopword list
# We can see which words are stop words print(nlp.Defaults.stop_words)

We can also modify the stop words list as per our use case by adding some words to the stop word list. Here I am adding a ‘1-5’ word in the stop word list
STOP_WORDS |= {"1-5"}
print(STOP_WORDS) #checking the word "1-5" is added to the list or not

Let’s see the change in the output of the text. Now here ‘1-5’ word is removed from the text.
text = "I had such high hopes for this dress 1-5 size to work for me." ans = " ".join([word for word in str(text).split() if word not in STOP_WORDS]) ans

Standardizing and Spell Check
We have often encountered data that is not properly formatted and has spelling errors. To solve this problem, we have an autocorrect library.
There might be spelling errors in the text, or it might not be in the correct format. For example, “swimming” for “swiming” or some words like “I loveee this” for “I love this”. Let’s first install the autocorrect library.
!pip install autocorrect
Now, let’s see how it’s done.
import itertools
from autocorrect import Speller
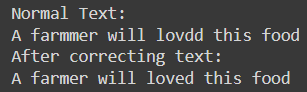
text="A farmmer will lovdd this food"
#One letter in a word should not be present more than twice in continuation
text_correction = ''.join(''.join(s)[:2] for _, s in itertools.groupby(text))
print("Normal Text:n{}".format(text_correction))
spell = Speller(lang='en')
ans = spell(text_correction)
print("After correcting text:n{}".format(ans))
Chat Words Conversion
We have often encountered some slang words, and we even write them in our day-to-day life. But that becomes a daunting task for the data cleaning and pre-processing process, and we need to take special care of this step as far as text cleaning in NLP is concerned.
We will make a function that will convert these short forms into long forms.
chat_words_str = """
AFAIK=As Far As I Know
AFK=Away From Keyboard
ASAP=As Soon As Possible
ATK=At The Keyboard
ATM=At The Moment
A3=Anytime, Anywhere, Anyplace"""
chat_words_map_dict = {}
chat_words_list = []
for line in chat_words_str.split("n"):
if line != "":
cw = line.split("=")[0]
cw_expanded = line.split("=")[1]
chat_words_list.append(cw)
chat_words_map_dict[cw] = cw_expanded
chat_words_list = set(chat_words_list)
def chat_words_conversion(text):
new_text = []
for w in text.split():
if w.upper() in chat_words_list:
new_text.append(chat_words_map_dict[w.upper()])
else:
new_text.append(w)
return " ".join(new_text)
chat_words_conversion("one minute A3")

Remove the Frequent Words
Let’s take dummy data to differentiate between them for the data easily; you can have access from here.
import pandas as pd
df = pd.read_csv('NLP cleaning part-2.csv')
df[:3]
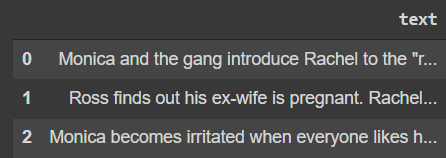
The data looks like this. We only have one column, which is text. We can use the collections library to find which words are frequently used and then use them in the word cloud.
Let’s see which words are repeated throughout the text, and if they hold importance, we will not remove them from the data.
from collections import Counter
cnt = Counter()
for text in df["text"].values:
for word in text.split():
cnt[word] += 1
cnt.most_common(10)
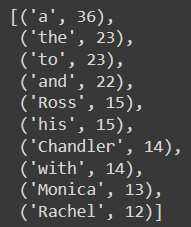
We saw which words are the most used in the text. If these words are not important, we can use the code below and remove them from the data.
FREQWORDS = set([w for (w, wc) in cnt.most_common(10)])
def remove_freqwords(text):
"""custom function to remove the frequent words"""
return " ".join([word for word in str(text).split() if word not in FREQWORDS])
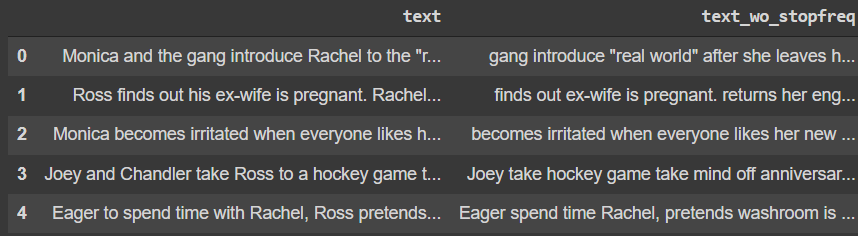
df["text_wo_stopfreq"] = df["text"].apply(lambda text: remove_freqwords(text))
df.head()
Remove the Less Frequent Words
After removing the most frequent words, there are changes that we have some less frequent words which don’t hold any vital information in the data and also use more memory. So, to remove them, below is the function. The words can be like I, and, or, etc.
n_rare_words = 10
RAREWORDS = set([w for (w, wc) in cnt.most_common()[:-n_rare_words-1:-1]])
def remove_rarewords(text):
"""custom function to remove the rare words"""
return " ".join([word for word in str(text).split() if word not in RAREWORDS])
df["text_wo_stopfreqrare"] = df["text_wo_stopfreq"].apply(lambda text: remove_rarewords(text))
df.head()

Conclusion
We saw the most common techniques to clean and pre-process the data and to implement the process of text cleaning in NLP. With each subsection, we saw techniques of removing them and when to remove them with the use cases. Additionally, what kind of situation do we need to avoid while applying the techniques to remove and clean the data for text analysis purposes or more. Following this article with codes and examples will help you gain knowledge of text cleaning.
About the Author
You can contact me on any of the below mediums:
LinkedIn | Kaggle | Tableau | Medium | Analytics Vidhya | Github
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A student who is learning and sharing with a storyteller to make your life easy.



