This article was published as a part of the Data Science Blogathon.

How did you find this blog? You typed some keywords related to data science in your browser. Then the search engine which you are using has redirected you to here within milliseconds. Have you ever thought about how it worked? Yes.! The unbeatable power of search engines. The search engines we are using today can handle billions of data flow within milliseconds. So what about a new search engine that can beat the current search engines in speed and semantic accuracy? The whole natural language processing and machine learning communities are discussing the possibilities of such search engines, which they named vector search engines. One of the most using vector search engines nowadays is Weaviate. In this blog, I will introduce the vector search engine – Weaviate to you. In this blog, we are going to cover these topics.
• Introduction to Weaviate
• Why a vector search engine
• How does Weaviate work – Architecture
• Weaviate setup
• Sample queries
Introduction to Weaviate
Weaviate is a vector database and search engine. It is a low-latency vector search engine that supports various media types(text, images, etc.). Weaviate uses machine learning to vectorize and store data and find responses to natural language questions. It includes semantic search, Question-Answer Extraction, Classification, and Customizable Models (PyTorch/TensorFlow/Keras). You may also use Weaviate to scale up your custom machine learning models in production.
Weaviate stores both media (text, images. etc.)objects and their corresponding vectors, allowing for combining vector search with structured filtering with the fault-tolerance of a cloud-native database. Weaviate search can perform through different methods such as GraphQL, REST, and various language clients. Python, Javascript, Go, and Go are popular programming languages that support Weaviate clients.
Nowadays, Weaviate is used by software engineers as an ML-first database for their applications, Data engineers to use a vector database built up from the ground with ANN at its core, Data scientists to deploy their search applications with MLOps.
Some major features of Weaviate are
Fast queries – In less than 100 milliseconds, Weaviate runs a 10 closest neighbour (NN) search over millions of items.
Different media support – Use State-of-the-Art AI model inference (e.g. Transformers) for Images, Text, etc.
Combining scalar and vector search – Weaviate saves both your objects and your vectors, ensuring that retrieval is always quick. A third-party object storage system is not required.
Horizontal scalability– Weaviate can scale horizontally in production depending on the use case.
Graph-like connections – Make graph-like connections between data items to mimic real-life connections between the data points. GraphQL is used to traverse those connections.
Why a vector search engine?
Consider the following data object.
{
“data”: “The Charminar constructed in 1591, is a monument located in Hyderabad,India.”
}
The above data object in the traditional search engine may store as an inverted search index. So for retrieving the data, we need to search with keywords such as “Charminar” or “ monument“, etc., to find it. But what if you have a lot of data and you’re looking for a document about the Charminar, but you’re looking for “landmarks in Telangana” instead? Traditional search engines cannot assist you in this situation, which is where vector search engines come in. To represent the data, Weaviate relies on vector indexing methods. The above-mentioned data object is vectorized in a vector space near the text “landmarks in Telangana” by the vectorization modules. Weaviate can’t produce a perfect match, but it can make a pretty good one to show you the results.
Like it vectorized the text, weaviate can vectorize any media such as image, video..etc., and perform the search. For the same reason that you use a standard search engine for your machine learning, you should use a vector search engine. It may be a strong production environment because it allows you to grow quickly, search, and classify in real-time.
How does Weaviate work?
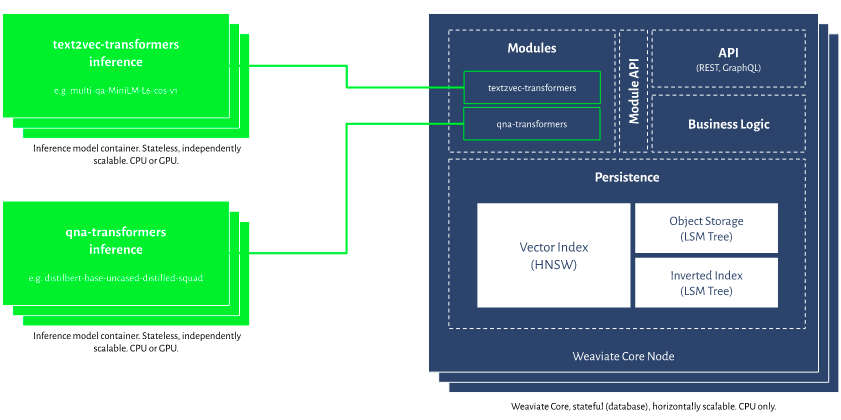
https://www.semi.technology/img/weaviate-architecture-overview.svg
Weaviate is a persistent and fault-tolerant database. Internally, each class in Weaviate’s user-defined schema results in developing an index. A wrapper type that consists of one or more shards is called an index, and shards are self-contained storage units within an index. Multiple shards can be utilized to automatically divide load among multiple server nodes, acting as a load balancer. Each shard house consists of three main components object store, Inverted index and vector index store.
The object store and inverted storage have been developed using an LSM-Tree architecture. This means that data can be consumed at memory speed, and if a threshold is reached, Weaviate will write the full (sorted) memtable to a disc segment. Weaviate will first examine the Memtable for the most recent update for a specific object when receiving a read request. Weaviate will check all previously written segments, starting with the most recent, if not present in the memtable. Bloom filters prevent examining segments that do not contain the requested objects.
Important: Object/Inverted Storage employs a segmentation-based LSM technique. The Vector Index, on the other hand, is unaffected by segmentation and is independent of those object storage.
HNSW vector index storage
Hierarchical Navigable Small-World graph, or HNSW for short, is one of the faster approximate nearest neighbour search algorithms widely used in data science applications. HNSW is the first vector index type supported by Weaviate act as a multilayered graph. In addition to the hierarchical stores stated above. On the other hand, the vector store is unconcerned about the object storage’s internals, and as a result, it doesn’t have any segmentation issues. Weaviate can ensure that each shard is a fully self-contained unit that can serve requests for the data it holds by grouping a vector index with object storage within a shard. Weaviate can avoid the drawbacks of a segmented vector index by locating the Vector index next to (rather than within) the object-store.
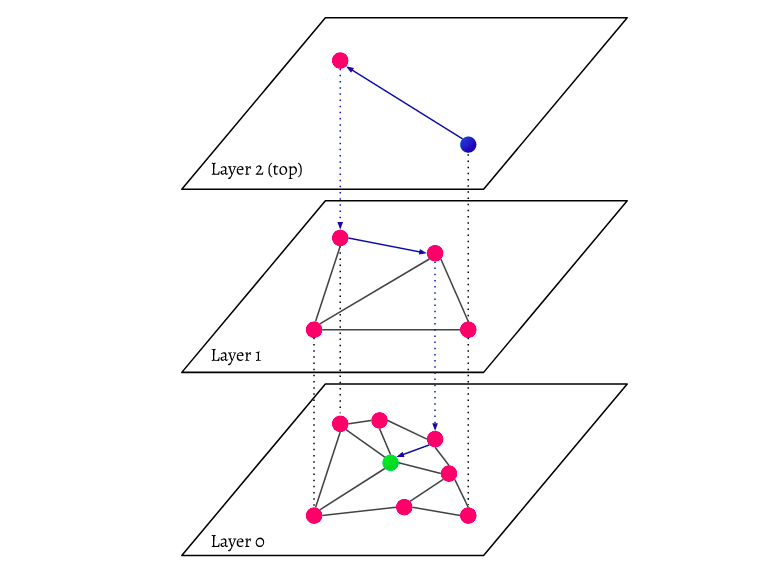
https://www.semi.technology/img/guides/hnsw-layers.svg
Every object in the database is collected (layer 0 in the picture). These data elements are inextricably linked. There are fewer data points represented on each layer above the lowest layer, and these data points correspond to lower layers. However, the number of points in each higher layer decreases exponentially. If a search query is submitted, the nearest data points in the topmost layer will be identified. There is only one extra data point in the image. Then it goes down a layer, finding the closest data points from the initial data point identified in the highest layer and searching for nearest neighbours from there. The closest data object to the search query will be discovered in the deepest layer.
text2vec-contextionary
Text2vec-contextionary is Weaviate’s own language vectorizer module. It puts the words in your dataset into perspective (there are Contextionary versions available for multiple languages). The Contextionary is a vectorizer module that can interact with common models like fastText and GloVe and uses the Weighted Mean of Word Embeddings (WMOWE). FastText on Wiki and CommonCrawl data was used to train the most recent text2vec-contextionary. Weaviate developers want to make the Contextionary available for use cases in every domain, whether they’re business-related, academic-related, or something else entirely. However, if needed, you can make your own vectorizer.
The text2vec-contextionary is a 300-dimensional space where data is placed. A vector of 300 numbers will be assigned to each data point. This vector is calculated using the Contextionary, which has already been trained (no training is required).
The Contextionary calculates the position in the vector space that represents the real-world entity when you add data. The conversion from a data object to a vector position is calculated using the centroid of the words, weighted by the number of times each word appears in the original training text corpus.
Extending the Contextionary
By extending the Contextionary, custom words or abbreviations (i.e. “concepts”) can be directly introduced to Weaviate. This endpoint will fill the Contextionary with your own words, abbreviations, and concepts in context by transferring learning. Weaviate learn various concepts in real-time by using the v1/modules/text2vec-contextionary/extensions/ endpoint. This endpoint can also be used to overwrite concepts. Before adding data, you must first learn Weaviate the new concepts.
Parameters
The extended-term or abbreviation you want to add to the Contextionary in a body (in JSON or YAML) with the following fields:
"concept": A string with the word, compound word or abbreviation"definition": A clear description of the concept, which will be used to create the context of the concept and place it in the high dimensional Contextionary space."weight": A floating-point number with the relative weight of the concept (default concepts in the Contextionary weight 1.0)
Persistence and Crash Recovery
At some point during the ingestion journey, both the LSM stores for object and inverted storage and the HNSW vector index store require memory. Each operation is also written into a Write-Ahead-Log to protect data in the event of a crash (WAL). WALs are append-only files that are fast to write and are rarely the bottleneck in the ingesting process.
Weaviate setup
There are several ways to set up a Weaviate instance. It is better to start with docker-compose when setting up the trial version. Cloud deployments can be used for small and large projects. For production environments and large projects, it is recommended to use Kubernetes. Here I am going to describe how to setup weaviate using docker-compose
To start Weaviate with docker-compose, we need a docker-compose configuration file. Docker-compose file is YAML file(.yml)
An instance docker-compose setup document with the transformer model sentence-transformers/msmarco-distilroberta-base-v2 is:
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:1.9.0
restart: on-failure:0
ports:
- "8080:8080"
environment:
QUERY_DEFAULTS_LIMIT: 20
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: "./data"
DEFAULT_VECTORIZER_MODULE: text2vec-transformers
ENABLE_MODULES: text2vec-transformers
TRANSFORMERS_INFERENCE_API: http://t2v-transformers:8080
t2v-transformers:
image: semitechnologies/transformers-inference:sentence-transformers-msmarco-distilroberta-base-v2
environment:
ENABLE_CUDA: 0 # set to 1 to enable
# NVIDIA_VISIBLE_DEVICES: all # enable if running with CUDA
Using a pre-trained language transformer model as a Weaviate vectorization module with the text2vec-transformers module. Transformer models differ from Contextionary models in that they allow you to plug in a ready-to-use NLP module tailored to your use case.
Save the above snippet as docker-compose.yml and run docker-compose up from within the same folder to run any of the examples below.
Now check the localhost in the browser as http://localhost:8080. You can see the weaviate GUI window there. Once the weaviate is up in your system, the next task is to create the data schema(the Skelton/structure of the dataset). In this example, we will use the wine dataset, and you can download it from here.
Create a data schema
We have one class, “Wine,” with a “title” and “description” in our example. Using the Weaviate client, upload the schema in JSON format to http://localhost:8080/v1/schema.
import weaviate
client = weaviate.Client("http://localhost:8080")
class_obj = {
"class": "Wine",
"properties": [
{
"name": "title",
"dataType": ["text"]
},
{
"name": "description",
"dataType": ["text"]
}
]
}
new_class = client.schema.create_class(class_obj)
Upload data
Now the real wine data must be uploaded to Weaviate.
import pandas as pd
import weaviate
# initiate the Weaviate client
client = weaviate.Client("http://localhost:8080")
# open wine dataset
df = pd.read_csv('winemag-data-130k-v2.csv', index_col=0)
def add_wines(data, batch_size=20):
no_items_in_batch = 0
for index, row in data.iterrows():
wine_object = {
"title": row["title"] + '.',
"description": row["description"],
}
client.batch.add_data_object(wine_object, "Wine")
no_items_in_batch += 1
if no_items_in_batch >= batch_size:
results = client.batch.create_objects()
no_items_in_batch = 0
client.batch.create_objects()
add_wines(df.head(2500))
Sample queries
After all of the objects have been successfully uploaded, you can begin querying the data. We can develop simple and complicated queries with GraphQL using weaviate client. We can use the following graphQL queries to retrieve the top 20 semantically matching results
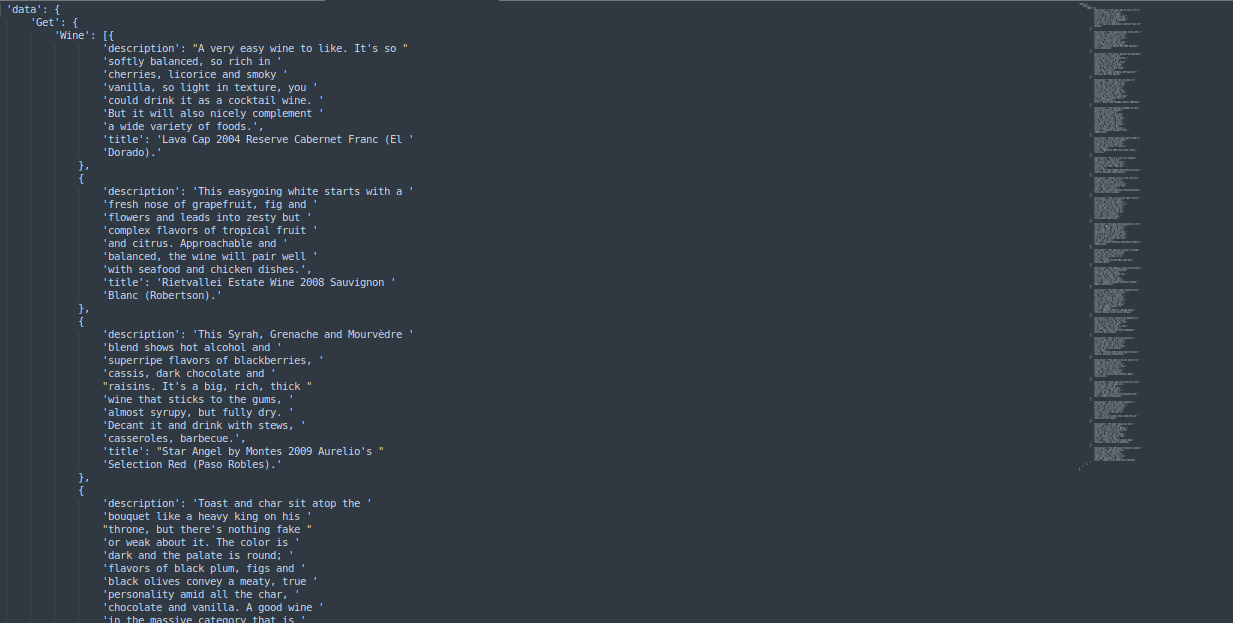
near text
Let’s assume we’re having chicken tonight and want to know which wines go nicely with it.
import weaviate
import pprint
# initiate the Weaviate client
client = weaviate.Client("http://localhost:8080")
near_text_filter = {
"concepts": ["wine that fits with chicken"],
"certainty": 0.5
}
query_result = client.query
.get("Wine", ["title","description"])
.with_near_text(near_text_filter)
.with_limit(20)
.do()
pprint.pprint(query_result)
Output
move away from
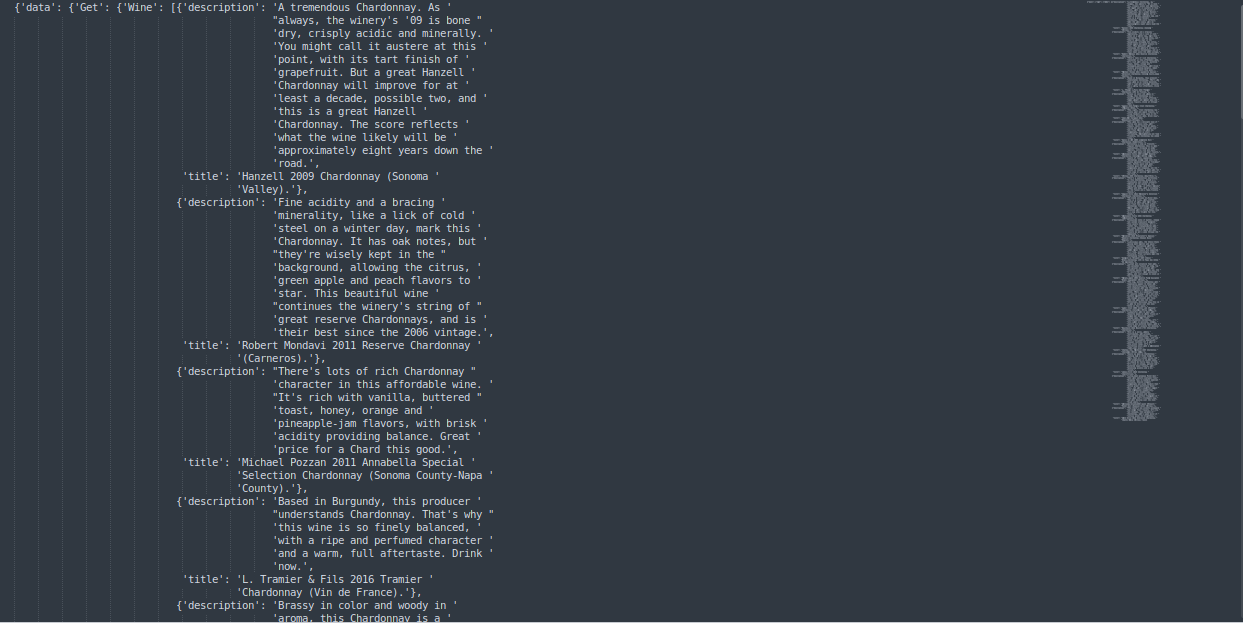
Let’s assume we are looking for healthy wines related to chardonnay but not much spicy and not much related to Aeration.
import weaviate
import pprint
# initiate the Weaviate client
client = weaviate.Client("http://localhost:8080")
near_text_filter = {
"concepts": ['healthy wine Chardonnay"],
"certainty": 0.5,
"moveAwayFrom":{
"concepts":["spicy and Aeration"],
"force":0.6
}
}
query_result = client.query
.get("Wine", ["title","description"])
.with_near_text(near_text_filter)
.with_limit(20)
.do()
pprint.pprint(query_result)
Output
More
Let’s assume we have fish tonight and want to know which wines go nicely with it but not much spicy and not much related to Aeration and more related to Chardonnay and corked.
import weaviate
import pprint
# initiate the Weaviate client
client = weaviate.Client("http://localhost:8080")
near_text_filter = {
"concepts": ["wine that fits with fish"],
"certainty": 0.5,
"moveAwayFrom": {
"concepts": ["spicy and Aeration"],
"force": 0.45
},
"moveTo": {
"concepts": ["Chardonnay with Corked"],
"force": 0.85
}
}
query_result = client.query
.get("Wine", ["title","description"])
.with_near_text(near_text_filter)
.with_limit(20)
.do()
pprint.pprint(query_result)
Output
We can use the certainty and force parameters in the above examples for result tuning purposes.
Wrapping up
So That’s it. Now you learned a little bit about semantic search and vector storage in this blog. In this article, I tried to demonstrate how to create your own vector database using your own data in Weaviate and how to retrieve them semantically in step by step manner. In the future, vector search engines like weaviate and semantic search will become an inextricable part of our everyday lives.
Happy coding..🤗
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A passionate data scientist. I love to explore data and extract insights that can help solve complex problems. With my knowledge of programming languages such as Python, I am proficient in developing models and analyzing large data sets. My passion for learning has led me to continuously expand my skillset and stay up-to-date with the latest trends in the field. I am committed to using data science to make a positive impact on society and believe that the power of data can transform businesses and organizations.





