This article was published as a part of the Data Science Blogathon.
Introduction
In this blog, we will get introduced to reinforcement learning with Python with examples and implementations in Python. It will be a basic code to demonstrate the working of an RL algorithm. Brief exposure to object-oriented programming in Python, machine learning, or deep learning will also be a plus point.
Table of contents
What do you mean by Reinforcement Learning With Python?
Before jumping into Reinforcement Learning With Python, abbreviated as RL, let us do a quick recap of machine learning.
In some situations, there is a lot of data available out there. However, algorithms aren’t available to teach machines the logic to arrive at the desired output. This is where machine learning comes to the rescue. Machine learning is the technology that, given the inputs and the desired outputs, will arrive at the logic or the algorithm to predict the output for an unforeseen or new input.
Types of Machine Learning
There are three types of machine learning:
- Supervised learning, in which features and labels are used to train the model to predict known target variables.
- Unsupervised learning, in which only features are used to train the model. Labels are unknown and thus the targets predicted are also unknown. The model learns by finding similar patterns in the dataset and grouping them into clusters.
- Reinforcement learning, which we will be discussing now.
In a nutshell, RL is the branch of machine learning in which a machine learns from experience and takes proper decisions in order to maximize its reward or, in other words, to get the best reward possible. The machine is called the agent here. For every action it takes, it receives an award if it was the right action, failing which, it receives a punishment if it was the wrong action.

The best and the most common example of RL is how pet dogs are trained to get the stick and come back to their master! Every time the dog fails to get the stick or gets a wrong stick, it will not get its treat otherwise it will be rewarded with its delicious treats. The dog, quite obviously, aims to maximize the number of treats it gets because it loves enjoying its food! In this case, the dog is referred to as the agent.
We will get a deeper insight into RL while discussing the underlying terminologies in the subsequent sections.
Scope of RL
A real-time example of reinforcement learning includes adaptive autonomous systems in which a system can teach support staff how to close cases based on the performances of the best support workers.

RL also exhibits super-human performance in video games! For instance, recent research in RL has trained agents for the Playstation game, Gran Turismo that can compete with the world’s best e-sports drivers!” Gran Turismo Sophy” is the name of the agent used here. A picture of the agent can be seen above. Interestingly, it won a head-to-head competition against four of the world’s best Gran Turismo drivers. You can read more about it from the research paper here.
Important Terminologies in RL
In this article, we will discuss the following terms:
- Agent
- Environment
- State
- Action
- Reward
Agent:
As discussed in the previous section, by referring to a dog as an agent, its aim is to maximize the reward. It learns by trial and error method and performs an action in its environment based on which it may or may not get a reward.
It implements some policy to decide what action must be taken at a given timestep.
For example, while training a self-driving car, unless it hits objects on its path, it will be receiving good or positive rewards. Once it dashes an obstacle, it will get a negative reward or a punishment.
Environment:
In the previous example, the track along which the car must ride is its environment. In the dog’s example, the ground where it runs to find the stick is its environment.
State:
“Where is the agent now?”
The answer to the above question gives the state. It is a snapshot of the environment where the agent currently is.
Action:
It is defined as the move made by the agent, based on its environment, at a particular point in time.
For example, the car may turn left or right in its path. Say it turns left. Now, this is the action taken by the car.
Reward:
As discussed so far, an agent bags the reward based on its action. The environment gives a positive or negative reward to the agent depending on what action it took.
How an RL model is Trained?
Training an RL model is an iterative process because the agent keeps on learning from its experience. It keeps exploring the environment. Here, the agent faces a trade-off between experience and exploration: At a given time, should the agent explore the environment and decide its next action or should it decide its next action based on its previous experience?
While training an RL model, firstly, scores are assigned to all the grids in the environment. The agent explores all the possible paths and learns from experience, again, aiming to maximize this total score it achieves by choosing among the grids.
The agent keeps exploring until it gets a negative reward. It stops at this point, realizing,”Oh! I was not supposed to go this way. I was wrong.”
Every time a decision is made, it’s called an episode. After an episode, the agent compares the reward it got in this episode with that of the previous episode. Thus, it learns which path it must choose in order to get the maximum reward.
Summing up, the agent keeps on accumulating scores and experiences as it explores. It simulates(explores) all the paths possible and finds which one will help get the maximum reward.
Steps of RL
To summarize what we discussed in the previous section, the following are the steps of an RL algorithm:
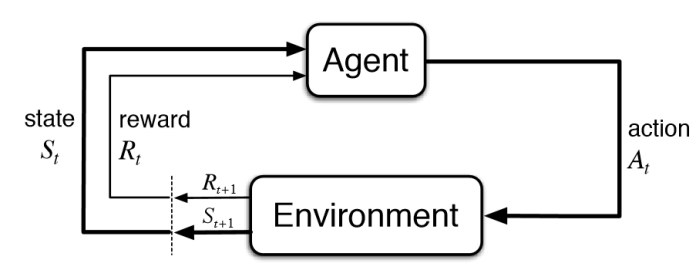
- The agent performs an action in its environment.
- The environment then returns the reward and the next state
- So, over time, the agent learns to take the best actions aiming to maximize the long-term rewards.
Basic Implementation of Reinforcement Learning with Python
It’s time to get our hands dirty with a few snippets!!!
The below code will help us draw an overview of how RL systems work internally. However, this is only a simple implementation to understand the concepts of RL which we discussed so far.
You can use Google Colab for implementation or install the random package and code on your local system.
To Check Random Package
To check if the action taken by the agent was correct or wrong, logic will be involved. But, here, let’s choose one of the rewards randomly using the random package. Let’s begin by importing it:
import randomFor the implementation, we will use two classes, namely, MyEnvironment and MyAgent.In this example, consider a game that the agent must finish in at most twenty steps.
MyEnvironment:
This is the environment class that represents the agent’s environment. The class must have member functions to get the current observation or current state where the agent is, what are the points for reward and punishment, keep track of how many more steps are left which the agent can take before the game is over.
With the above understanding, let us define the environment class as follows:
#create Environment class
class MyEnvironment:
def __init__(self):
self.remaining_steps=20
def get_observation(self):
return [1.0,2.0,1.0]
def get_actions(self):
return [-1,1]
def check_is_done(self):
return self.remaining_steps==0
def action(self,int):
if self.check_is_done():
raise Exception("Game over")
self.remaining_steps-=1
return random.random()Number of Steps Remaining
__init__() is the default constructor which initializes the number of steps remaining to 20 before the agent starts playing the game.
The get_observation() function returns the current state of the agent in terms of the coordinates. It can be any number of coordinates here but I have considered 3 and the coordinate values (1.0,2.0,1.0) are also arbitrary. You can assume any number of coordinates and any value for each of the coordinates as you wish! Basically, these coordinate values give information about the environment. For the simplicity of the implementation here, I have not used any logic to get these coordinates.
When an agent performs an action, it should get a positive reward or a negative reward which I have set to +1 and -1 respectively. The get_actions() function returns these two possible rewards as a list.
The next function check_is_done() checks if the agent has any remaining number of steps that it can take. If this is none, then the agent should not move anymore.
The action() function is used by the environment to return some reward points to the agent based on its action which the function receives as an integer parameter. The function first checks if the game is over by invoking the previous function(check_is_done()).In case the game is over, it raises an exception and stops the game otherwise it decrements the number of remaining steps available. The random package is used here to return a random number as the reward for the agent’s action!
Real-time Applications
Real-time applications, there will be some logic to compute this reward here.
myAgent:
The agent class is simpler compared to the environment class. The agent collects rewards given to it by its environment and makes an action. For this, we will need a data member and a member function.
With this knowledge, the agent class can be defined as follows:
class myAgent:
def __init__(self):
self.total_rewards=0.0
def step(self,ob:MyEnvironment):
curr_obs=ob.get_observation()
print(curr_obs)
curr_action=ob.get_actions()
print(curr_action)
curr_reward=ob.action(random.choice(curr_action))
self.total_rewards+=curr_reward
print("Total rewards so far= %.3f "%self.total_rewards)Initialization of Reward Points in Default Constructor
The __init__() default constructor initializes the total reward points to 0.0 as the agent doesn’t win any reward at the beginning of the game.
The step() member function has the corresponding environment(the environment where the agent is exploring) as its parameter. That’s why the object of the environment class is passed as a parameter to this function.
The function first gets the current state of the agent by invoking the get_observation() function of the environment class using its object. It then gets the possible rewards(1 or -1 as explained in the myEnvironment class)for the actions made by the agent. It then randomly chooses either 1 or -1 using the random.choice() function and claims this value to be the current action taken by the agent(But, in reality, this value is not random. It will be computed using some logic). This value is passed to the action function of the myEnvironment class to obtain the current reward. The returned reward is added to the total rewards collected by the agent so far.
Note that the reward here can be positive(in case of 1) or negative(in case of -1) and will be added to the total rewards of the agent.
Finally, create objects of the above classes and execute as follows:
if __name__=='__main__':
obj=MyEnvironment()
agent=myAgent()
step_number=0
while not obj.check_is_done():
step_number+=1
print("Step-",step_number)
agent.step(obj)
print("Total reward is %.3f "%agent.total_rewards)Objects can be created in Python simply by declaring the class this way:class_name(). There are no parameters __init__ constructors so it is that simple in our case.
obj is an object of myEnvironment class and agent is an object of the myAgent class. Until the game is not over, which is checked by the while loop, the agent takes an action by invoking the step function of the myAgent class by passing obj which refers to the agent’s environment.
You can find the entire code from here.
Results
Running the above code, we will get the rewards accumulated by the agent in each and every step up to 20 steps which is the upper limit defined by us. Here is a snapshot of what I got:
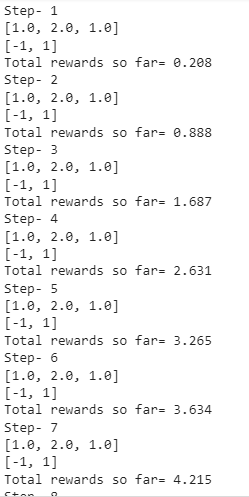
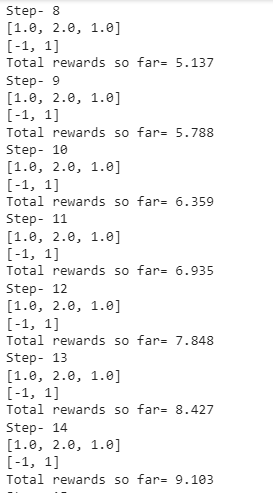

‘Source:Author’
The rewards collected in every step have been displayed clearly step-wise as shown above.
Great! My agent collected a total reward point of 12.235.
Observe that your rewards and my rewards will be different because a random package is used to calculate these rewards. We know that the random package returns numbers randomly. In fact, if you execute the code sometime later, you will get a different answer!
Also, the observation [1.0,2.0,1.0] and the rewards [-1,1] returned in every step will be the same because we haven’t used any logic here. In reality, the agent takes an action and its state will also keep changing.
Rewards will remain constant thus always being 1 or -1 only. Further, how they are applied and the final reward points are given to the agent must be computed through some logic but, in our example, the random package has been used to simulate the same.
Challenges of RL
It is very complex in reality because there cannot be any rewinds or what-if-s(we cannot stop AI and ask it to show something else to the user when it is running in real-time!). Also, real-time performance involves millions of users whom the system must respond to in just a few milliseconds! For things operating in the real world, explorations lead to many consequences and there is no undo option available.
Conclusion
In summary, Reinforcement Learning with Python covers the fundamentals, key terms, training methods, and implementation steps of RL. Through practical demonstrations, it illuminates the breadth of RL’s applicability, offering a foundation for deeper exploration within the realm of machine learning.
Hope you liked it.
Thank you for reading!.
You can find my other articles on Analytics Vidhya from here.
References
- Image-1:Dog
- Image-2:Gran Turismo Sophy
- Image-3:RL diagram
- Paper
- Basics of RL
- Implementation of RL in Python
- RL in real life
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.





