This article was published as a part of the Data Science Blogathon.
Machine learning and artificial intelligence, which are at the top of the list of data science capabilities, aren’t just buzzwords; many companies are keen to implement them. Before developing intelligent data products, however, one requires to look down into complete data literacy, collecting, and infrastructure to make it happen. Big data is changing the way we do business. Resultantly, necessitating the hiring of data engineers who can collect and manage massive volumes of information. We’ll go over the mechanics of the data flow process in this article, as well as the nuances of establishing a data warehouse and the job of a data engineer.
Introduction on Data Engineering
Data Engineering is the process of designing and building large-scale data collection, storage, and analysis systems. It’s a broad topic with applications in nearly every business. We can collect large volumes of data, but this requires correct people and technology to ensure that data is usable by the time it reaches data scientists and analysts.

Table of contents
If we look at the hierarchy of demands in data science implementations, we can see that data engineering is the next stage after acquiring data for analysis. In fact, we can’t overlook this discipline. As if it allows for efficient data storage and dependable data flow while also managing the infrastructure. Without data engineers to analyze and channel that data fields like machine learning and deep learning won’t prosper.
What is Data Engineering?
Data engineering is a series of processes that aims at building information flow and access interfaces and procedures. Maintaining data such that it is available and usable by others necessitates the use of dedicated specialists – data engineers. In a nutshell, data engineers put up and maintain the organization’s data infrastructure, ready it for analysis by data analysts and scientists.
Let’s start with data sources to grasp data engineering in simple words. There are frequently several various types of operations management software (e.g., ERP, CRM, production systems, etc.) within a large firm, all of which contain different databases with different information.

Furthermore, we can save data as a distinct file or even fetch it in real-time from external sources (such as various IoT devices). As the number of data sources grows, composing data into fragments across multiple formats prohibits an organization from receiving a complete and accurate picture of its financial situation.
For example, we must link the sales data from a specialized database to inventory records in a SQL server. This operation entails pulling data from those systems and integrating it into a centralized storage system. In this centralized system we can collect, reform, and maintain data for ready to use purpose. Data warehouses are storage facilities like this. Data engineers manage the process of migrating data from one system to another, whether it’s a SaaS service, a Data Warehouse (DW), or just another database.
Why is Data Engineering Important?
Data Engineering is important because it helps make data easy to use, accurate, and reliable. Here is Why it matters:
- Getting Data Easily: Data engineers organize data so that people can find and use it easily. This means that when someone needs information, they can get it quickly without any hassle.
- Making Sure Data is Good: Data engineers clean up messy data and make sure it’s accurate. Imagine if you’re looking at sales numbers, but some of them need to be corrected. Data engineers fix those mistakes so that decisions are based on the right information.
- Handling Lots of Data: Nowadays, there’s a ton of data being generated all the time. Data engineers build systems that can handle huge amounts of data without slowing down. So, even when there’s a lot to deal with, things keep running smoothly.
- Speeding Things Up: Data engineers make sure that data processes happen fast. People prefer waiting for data to load or analyze. They tweak things so that everything happens quickly and efficiently.
- Making Different Systems Work Together: Sometimes, data comes from different places in different formats. Data engineers figure out how to combine all that information and make it work. This means that even if data is coming from different sources, it can still be used together.
- Helping with Decision Making: Good data helps businesses make smart decisions. Data engineers set up systems that turn raw data into valuable insights. This helps bosses and managers make better choices for the company’s future.
- Keeping Things Safe and Legal: Data engineers make sure that data is kept safe and follows the rules. They set up security measures to protect data from hackers and make sure that the company is following laws about data privacy.
ETL Data Pipeline
A data pipeline is essentially a collection of tools and methods for transferring data from one system to another for storage and processing. It collects data from several sources and stores it in a database. It’s an another tool, or an app, giving data scientists, BI engineers, data analysts, and other teams quick and dependable access to this combined data.

Data engineering is primarily responsible for constructing data pipelines. Designing a program for continuous and automated data interchange necessitates considerable programming skills. For a variety of tasks, we can use a data pipeline tool. These are:
- Transferring data to a data warehouse or the cloud.
- Gathering data into a single spot for machine learning projects’ convenience.
- In the Internet of Things (IoT), we combine data from numerous linked devices and systems.
- Transferring databases to a cloud-based data warehouse and,
- BI brings data together in one location for better business choices.
Data pipeline challenges
It is difficult to set up a secure and dependable data flow. Many things can go wrong during data transport. For example, data can be susceptible to damage, bottlenecks can cause slowness, and conflicts in data sources result in duplicate or inaccurate data. To obscure sensitive information, maintaining authenticity and correctness of vital data, we require rigorous planning and testing. We perform this to filter out trash data, eliminate duplicates, and fix incompatible data types.
Building data pipelines has two key pitfalls:
- Lack of meaningful metrics, and
- Underestimation of data load.
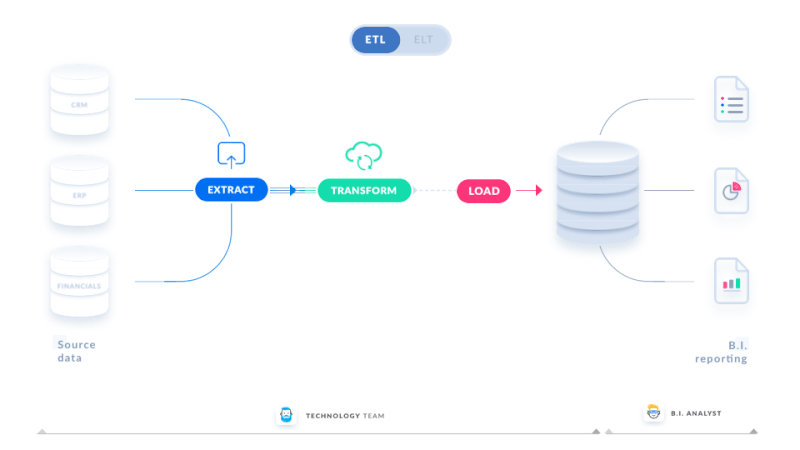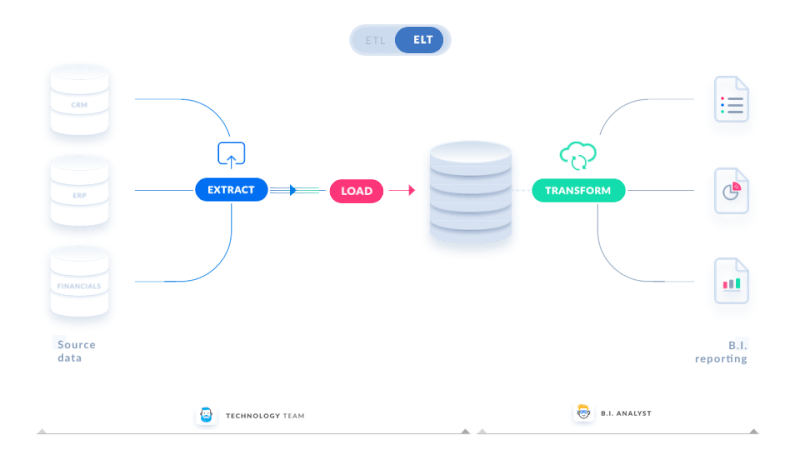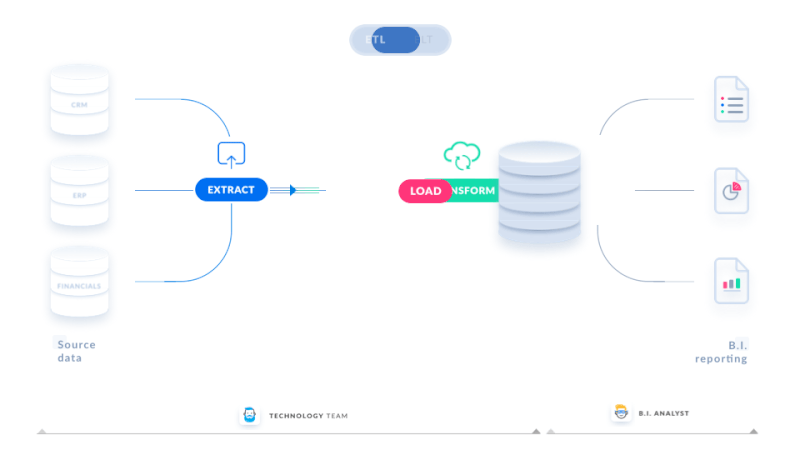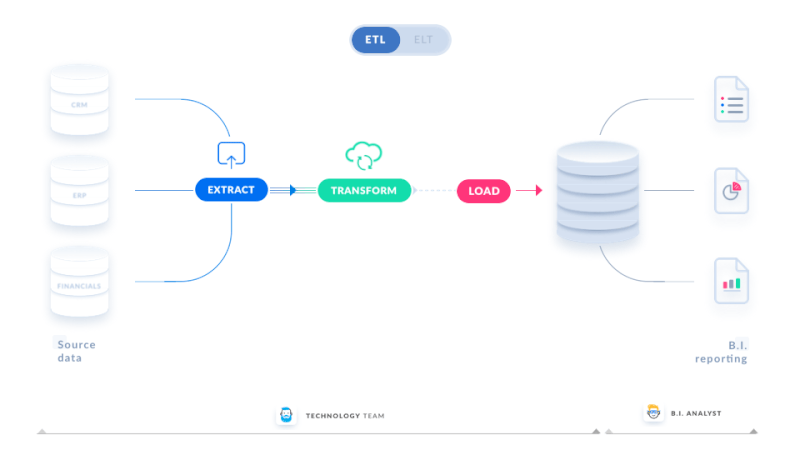
ETL & ELT
ETL refers to extracting, transforming, and loading. Pipeline infrastructure varies in size and scope based on the use case. Data engineering, on the other hand, frequently begins with ETL operations.
- Extract: The process of obtaining data from a source system is known as extraction. For instance, a python process- retrieves data from an API, access data from an OLTP database, and so on.
- Transform: Here, we process or transform the extracted data. Changing field types and names, implementing business logic on the data set, enhancing data, and so on.
- Load: It’s a process of loading transformed data into the data asset used by the end-user.
After the data has been translated and imported into a single storage location, we may use it for further analysis and business intelligence tasks, such as reporting and visualization.
Source: Linkedin.com
Traditionally, we used ETL to refer to any data pipeline in which data is extracted from a source, transformed, and loaded into a final table for end-user usage. The transformation could be done in Python, Spark, Scala, or SQL in the data warehouse, among other languages. ELT is a term which we can describe as data pipelines that convert data in a data warehouse.
When individuals mention ETL and ELT, they’re referring to
- ETL: The raw data is saved in a file system, then converted using python/spark/scala or other non-SQL languages before being imported into tables for end-user use.
- ELT: Enter raw data into the data warehouse and use SQL to transform it into the final table that the end-user may use.
Data Warehouse
A data warehouse is a database that stores all of your company’s historical data and allows you to conduct analytical queries against it. A data warehouse is a relational database that is optimized for reading, aggregating, and querying massive amounts of data from a technical point of view. Traditionally, data warehouses (DWs) exclusively held structured data or can organize it into tables. Modern DWs, on the other hand, can integrate structured and unstructured data.
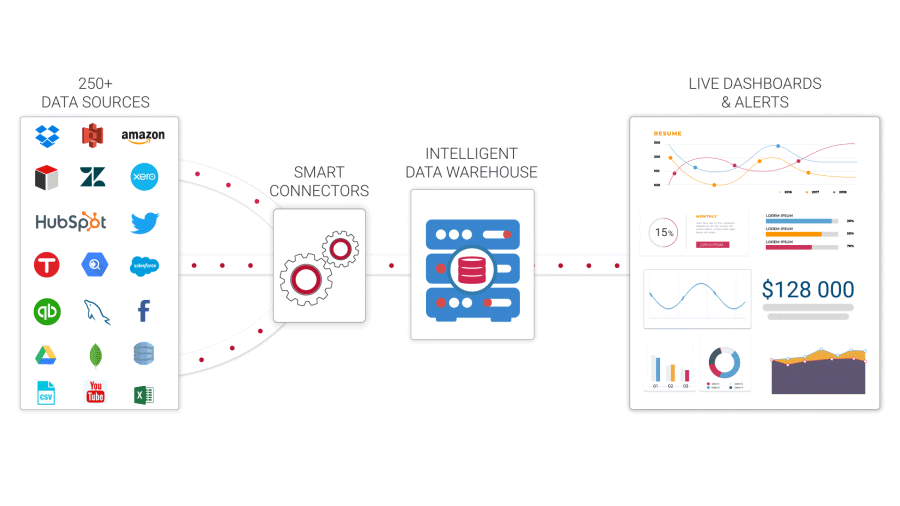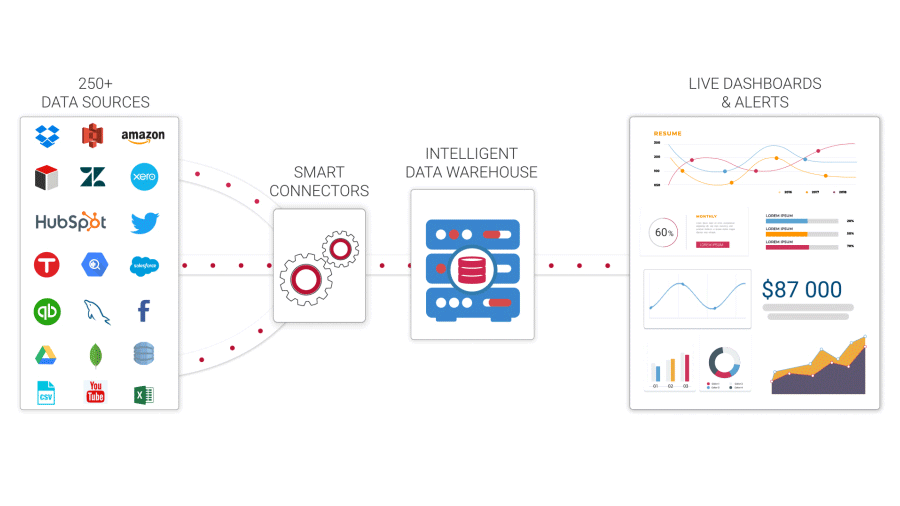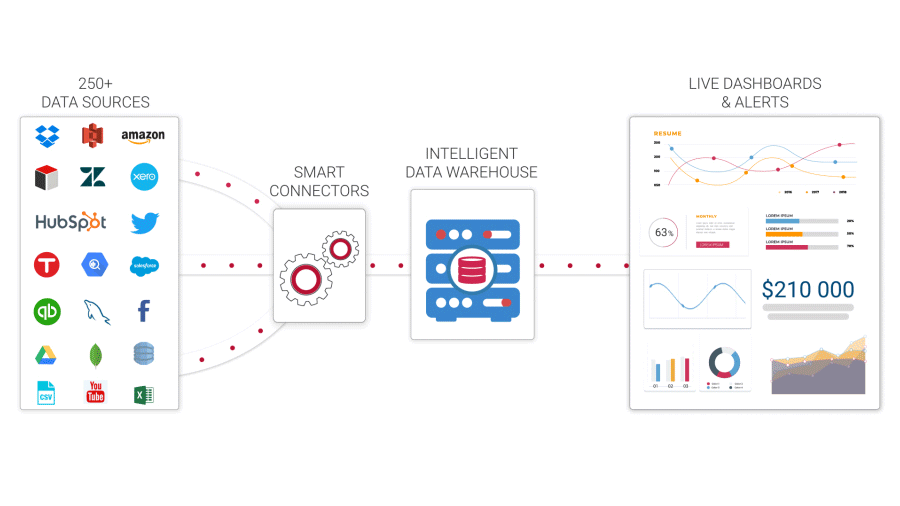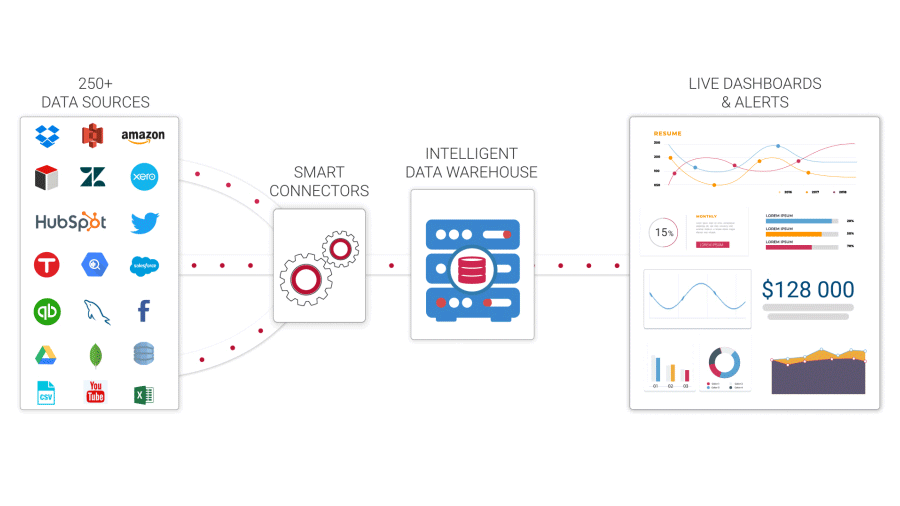
Without data warehouses, data scientists would have consider data directly from the production database, which could result in different answers to the same inquiry, as well as delays and interruptions. The data warehouse, which serves as an organization’s single source of truth, streamlines reporting and analysis, decision-making, and metrics forecasting.
Four essential components are combined to create a data warehouse:
- Data warehouse storage.
- Metadata.
- Access tools.
- Management tools.
Data Engineering: Moving Beyond Just Software Engineering
Software engineering is well-known for its programming languages, object-oriented programming, and operating system development. However, as businesses experience a data explosion, traditional software engineering thinking fails to process big data. Data engineering helps firms to collect, generate, store, analyze, and manage data in real-time or in batches. We can achieve this while constructing data infrastructure, all thanks to a new set of tools and technologies.
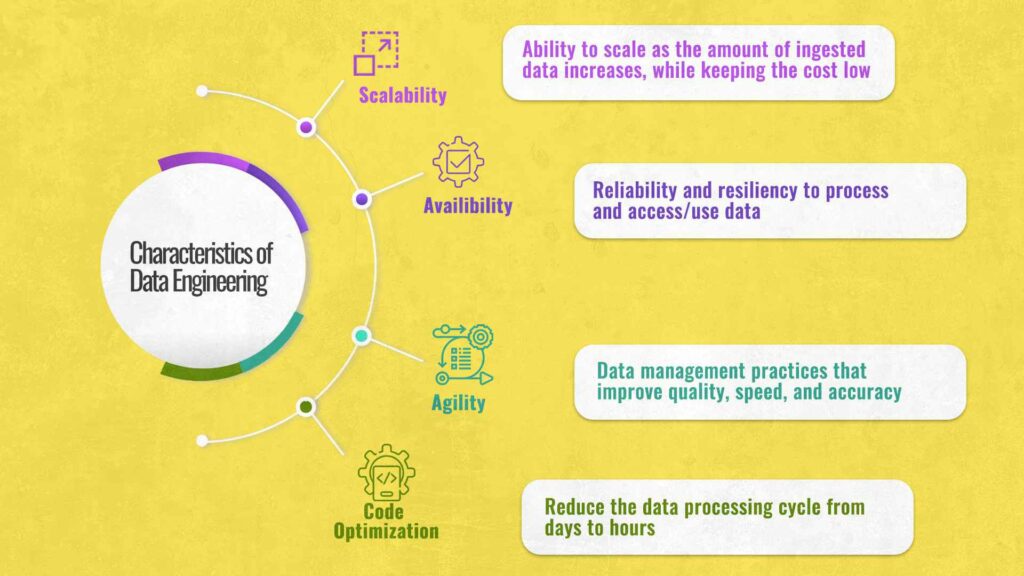
Traditional software engineering approaches entail mostly stateless software design, programming, and development. Data engineering, on the other hand, focuses on scaling stateful data systems and dealing with various levels of complexity. In terms of scalability, optimization, availability, and agility, there are also disparities in the complexity of the two fields.
Sample Python Code
MongoDB is a document-based NoSQL database that scales effectively. We’ll begin by importing relevant Python libraries.
Here’s how to make a database and populate it with data:
import pymongo
client = pymongo.MongoClient("mongodb://localhost:27017/")
# Note: This database is not created until it is populated by some data
db = client["example_database"]
customers = db["customers"]
items = db["items"]
customers_data = [{ "firstname": "Bob", "lastname": "Adams" },
{ "firstname": "Amy", "lastname": "Smith" },
{ "firstname": "Rob", "lastname": "Bennet" },]
items_data = [{ "title": "USB", "price": 10.2 },
{ "title": "Mouse", "price": 12.23 },
{ "title": "Monitor", "price": 199.99 },]
customers.insert_many(customers_data)
items.insert_many(items_data)
Conclusion
There’s no denying that data engineering is a fast-growing field. It is, however, a new space. The entire landscape of business operations is being challenged by data engineering. And, we can’t predict a better time for prospective individuals to dive into this ever-evolving subject.
- Data engineers’ role is to assist organizations in moving and processing data, not to do it themselves.
- From monolith to automated, decentralized, self-serve data micro warehouses, data architecture follows a predictable evolutionary path.
- Connector integration is an important step in this evolution. Also, it increases workload and necessitates automation to compensate.
- The demand for automated data management will grow as regulatory scrutiny and privacy regulations become more stringent.
- Data ecosystems are now unable to achieve full decentralization due to a lack of refined, non-technical tooling.
Read the latest articles on our blog. Please feel free to leave a remark below if you have any queries or concerns about the blog.
Thank you.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A graduate in Computer Science and Engineering from Tezpur Central University. Currently, I am pursuing my M.Tech in Computer Science and Engineering in the Department of CSE at NIT Durgapur. I expect to Postgraduate in the spring, 2022. A Grounded and Solution-oriented Computer Engineer with a wide variety of experiences. Adept at motivating self and others. Passionate about programming and educating the next generation of technology users and innovators.





