The field of Deep Learning has materialized a lot over the past few decades due to efficiently tackling massive datasets and making computer systems capable enough to solve computational problems. Convolutional Neural Networks in Deep Learning have ushered in a new era, with old techniques proving inefficient, particularly for problems like Pattern Recognition, Object Detection, Image Segmentation, and other image processing tasks. CNNs are among the most deployed deep learning neural networks.
This article was published as a part of the Data Science Blogathon.

Table of contents
Background of CNNs
Around the 1980s, CNNs were developed and deployed for the first time. A CNN could only detect handwritten digits at the time. CNN was primarily used in various areas to read zip and pin codes etc.
The most common aspect of any A.I. model is that it requires a massive amount of data to train. This presented one of the biggest problems that CNN faced at the time, and as a result, they only found use in the postal industry. Yann LeCun was the first to introduce convolutional neural networks.
Kunihiko Fukushima, a renowned Japanese scientist, invented the recognition system, a simple neural network used for image identification. He developed this system based on the earlier work done by LeCun.
What is CNN?
In the field of deep learning, the convolutional neural network (CNN) ranks among the class of deep neural networks that analysts primarily deploy for image recognition and analysis.
Convolutional Neural Networks use a very special method known as convolution.
The mathematical definition of convolution describes a mathematical operation applied to two functions that produces a third function, showing how the shape of one function influences and modifies the other function.

The Convolutional neural networks(CNN) consists of various layers of artificial neurons. Artificial neurons, similar to the neuron cells that the human brain uses to pass various sensory input signals and other responses, function as mathematical tools that calculate the sum of various inputs and produce an output in the form of an activation value.
The behaviour of each CNN neuron is being defined by the value of its weights. When being fed with the values (of the pixel), the artificial neurons of a CNN recognizes various visual features and specifications.
Activation Maps and Feature Recognition
When we give an input image into a CNN, each of its inner layers generates various activation maps. Activation maps point out the relevant features of the given input image. Each of the CNN neurons generally takes input in the form of a group/patch of the pixel, multiplies their values(colours) by the value of its weights, adds them up, and input them through the respective activation function.
Hierarchical Feature Extraction
The first (or maybe the bottom) layer of the CNN usually recognizes the various features of the input image such as edges horizontally, vertically, and diagonally. The output of the first layer is being fed as an input of the next layer, which in turn will extract other complex features of the input image like corners and combinations of edges. The deeper one moves into the convolutional neural network, the more the layers start detecting various higher-level features such as objects, faces, etc
CNN’s Basic Architecture
A CNN architecture consists of two key components:
• A convolution tool that separates and identifies the distinct features of an image for analysis in a process known as Feature Extraction
• A fully connected layer that takes the output of the convolution process and predicts the image’s class based on the features retrieved earlier.
The CNN consists of three types of layers:
- Convolutional layers
- Pooling layers
- Fully-connected (FC) layers.
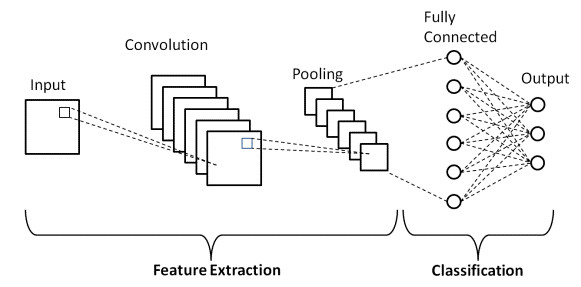
Convolution Layers
This is the very first layer in the CNN that is responsible for the extraction of the different features from the input images. The convolution mathematical operation occurs between the input image and a filter of a specific size M×M in this layer.
The Fully Connected
The Fully Connected (FC) layer comprises weights and biases along with neurons and connects the neurons between two separate layers. The last several layers of a CNN architecture usually position themselves before the output layer.
Pooling layer
The Pooling layer is responsible for the reduction of the size(spatial) of the Convolved Feature. This decrease in computing power requires a significant reduction in the dimensions to process the data.
There are two types of pooling
- Average pooling
- Max pooling
A Pooling Layer is usually applied after a Convolutional Layer. This layer’s major goal is to lower the size of the convolved feature map to reduce computational expenses. This achieves a reduction in connections between layers and allows independent operation on each feature map. There are numerous sorts of Pooling operations, depending on the mechanism utilised.

Max Pooling extracts the largest element from the feature map. Average Pooling calculates the average of the elements in a predefined-sized image segment. Sum Pooling calculates the total sum of the components in the predefined section. The Pooling Layer is typically used to connect the Convolutional Layer and the FC Layer.
Dropout
To avoid overfitting (when a model performs well on training data but not on new data), a dropout layer removes a few neurons from the neural network during the training phase, resulting in a smaller model.
Activation Functions
- They learn and approximate any form of variable-to-variable association that is both continuous and complex.
- It gives the network non-linearity. The ReLU, Softmax, and tanH serve as some of the most commonly used activation functions.
Training the convolutional neural network
The process of adjusting the value of the weights is defined as the “training” of the neural network.
Initialization and Dataset
Firstly, the CNN initiates with the random weights. During the training of CNN, the neural network receives a large dataset of images labeled with their corresponding class labels (cat, dog, horse, etc.). The CNN processes each image with randomly assigned values and then makes comparisons with the class label of the input image.
If the output does not match the class label(which mostly happen initially at the beginning of the training process and therefore makes a respective small adjustment to the weights of its CNN neurons so that output correctly matches the class label image.

The corrections to the value of weights occur through a technique known as backpropagation. Backpropagation optimizes the tuning process and simplifies adjustments for better accuracy. Each run of the training of the image dataset is called an epoch.
Gradual Improvement Over Epochs
The CNN goes through several epochs during training, adjusting its weights incrementally. After each epoch, the network becomes more accurate at classifying and predicting the correct class for the training images. Over time, as the CNN improves, the weight adjustments become smaller.
After training the CNN, we use a test dataset to verify its accuracy. The test dataset consists of labeled images that the training process does not include. Each image feeds into the CNN, and the output compares to the actual class label of the test image. Essentially, the test dataset evaluates the prediction performance of the CNN
If a CNN accuracy is good on its training data but is bad on the test data, it is said as “overfitting.” This happens due to less size of the dataset (training)
Limitations
- They (CNN) use massive computing power and resources for the recognition of various visual patterns/trends that is very much impossible to achieve by the human eye.
- One usually needs a very long time to train a convolutional neural network, especially with a large size of image datasets.
- One generally requires very specialized hardware (like a GPU) to perform the training of the dataset
Python Code implementation for Implementing CNN for classification
Importing Relevant Libraries
import NumPy as np
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import TensorFlow as tf
tf.compat.v1.set_random_seed(2019)Loading MNIST Dataset
(X_train,Y_train),(X_test,Y_test) = keras.datasets.mnist.load_data()Scaling The Data
X_train = X_train / 255
X_test = X_test / 255
#flatenning
X_train_flattened = X_train.reshape(len(X_train), 28*28)
X_test_flattened = X_test.reshape(len(X_test), 28*28)Designing The Neural Network
model = keras.Sequential([
keras.layers.Dense(10, input_shape=(784,), activation='sigmoid')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train_flattened, Y_train, epochs=5)Output:
Epoch 1/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.7187 - accuracy: 0.8141 Epoch 2/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.3122 - accuracy: 0.9128 Epoch 3/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.2908 - accuracy: 0.9187 Epoch 4/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.2783 - accuracy: 0.9229 Epoch 5/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.2643 - accuracy: 0.9262
Confusion Matrix for visualization of predictions
Y_predict = model.predict(X_test_flattened)
Y_predict_labels = [np.argmax(i) for i in Y_predict]cm = tf.math.confusion_matrix(labels=Y_test,predictions=Y_predict_labels)
%matplotlib inline
plt.figure(figsize = (10,7))
sn.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Truth')Output
.png)
Conclusion
So in this article, we covered the basic Introduction about CNN architecture and its basic implementation in real-time scenarios like classification. We also covered other key terminologies related to CNN like pooling, Activation Function, Dropoutetc. We also covered about limitations regarding CNN and the training of CNN.
Thank you so much for taking your precious time to read this blog. Feel free to point out any mistake(I’m a learner after all) and provide respective feedback or leave a comment.
Dhanyvaad!!
Email: [email protected]
Frequently Asked Questions
Q1. What is the overview of CNN?
A. A Convolutional Neural Network (CNN) is a deep learning architecture designed for image analysis and recognition. It employs specialized layers to automatically learn features from images, capturing patterns of increasing complexity. These features are then used to classify objects or scenes. CNNs have revolutionized computer vision tasks, exhibiting high accuracy and efficiency in tasks like image classification, object detection, and image generation.
Q2. What is the basic principle of CNN?
A. The fundamental principle of Convolutional Neural Networks (CNNs) is hierarchical feature learning. CNNs process input data, often images, by applying a series of convolutional and pooling layers. Convolutional layers employ small filters to convolve across the input, detecting spatial patterns. Pooling layers downsample the output, retaining important information. This enables the network to progressively learn hierarchical features, from simple edges to complex object parts. The learned features are then used for classification or other tasks. CNNs’ ability to automatically learn and abstract features from data has made them exceptionally effective in image analysis, with applications spanning various fields.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion
Aspiring Data Scientist | M.TECH, CSE at NIT DURGAPUR

