This article was published as a part of the Data Science Blogathon.
Introduction
Feature analysis is an important step in building any predictive model. It helps us in understanding the relationship between dependent and independent variables. In this article, we will look into a very simple feature analysis technique that can be used in cases such as binary classification problems. The underlying idea is to quantify the relationships between each independent variable and dependent variable at certain levels of values for each variable, this can help in identifying a subset of variables that are more important and also know about the important levels of particular feature values.
This knowledge about features can help us in deciding which features to include in the initial model. It can also help reduce the overall complexity of the predictive model by converting continuous numerical variables to categorical types by way of binning them. In particular, we will look at a supervised feature analysis approach also known as bivariate feature analysis.
Dataset
Wine Quality Dataset –
The dataset used in this article is publicly available from the UCI Machine Learning Repository,
Link: https://archive-beta.ics.uci.edu/ml/datasets/wine+quality
Attributes/Features List
 Source: Author
Source: Author
Output (Target) variable: quality (score between 0 and 10)
Let’s look at the distribution of target variable,
 Source: Author
Source: Author
A higher score means better quality of the wine.
Let’s consider scores of 8 & 9 as an excellent quality group and the rest of the scores as a non-excellent quality group.
Source: Author
Thus, our problem statement now is to predict the quality of wine as Excellent or Non-Excellent based on the available features.
Note that the classes are imbalanced here, we have very few examples of Excellent quality wines as compared to Non-Excellent ones. These kinds of situations are often encountered in problems such as credit card fraud detection, insurance claim fraud identification or disease detection. Identifying the most relevant features in these kinds of situations can help businesses prioritize & focus on important features thereby significantly improving the predictive power of the underlying model while keeping it simple.
We will use feature analysis methods to see which of these are relevant variables for determining the excellent quality wine.
Feature Analysis
We will follow a supervised feature analysis approach. In particular, we will use the target variable along with independent variables to check their relationships.
Let’s split the data as train & test sets,
After splitting the dataset into train & test sets the target distribution will look as below,

Source: Author
In order to produce the same results/numbers as above refer to the data exploration code below and set the random_state=100
In this dataset, all the features are numeric. The values of these features are continuous in nature. In order to understand how these are related to the target variable, we need to look at the buckets/level of each variable value.
The helper function below will compute several statistics in order to analyse the relationship between each bucket of values and the target variable.
Comparing Train & Test Target Percentage
Using the feature_analysis helper function above we will get a feature analysis dataframe.
all_features_list = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar', 'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol']
feature_analysis_df = feature_analysis(y='target', features=all_features_list, trn_df=trn_wine_data, tst_df=tst_wine_data, y_hat=None)feature_analysis_df = feature_analysis(y='target', features=all_features_list, trn_df=trn_wine_data, tst_df=tst_wine_data, y_hat=None)
We can see that each feature is broken down into various levels.
Table 1: Feature analysis of feature – fixed acidity
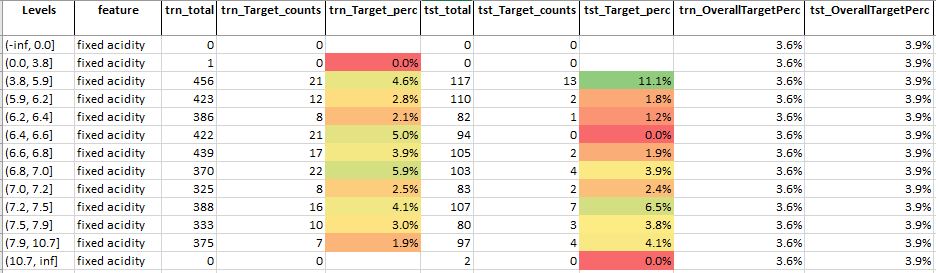
Source: Author
Since we randomly sampled train and test datasets hence the overall target percentages of train and test splits are nearly the same.
The overall target percentage is like a benchmark against which each of the levels can be compared.
The objective of this analysis is to know,
- Whether there is a trend between levels and target percentage.
- On average, how does a feature is relevant based on the presence of the target as compared to the overall target percentage
Let’s look at each feature individually,
For feature fixed acidity we see that (Refer Table 1),
- As the levels are increasing the target percentage is getting lower
- This suggests that the more acidic nature of the wine makes it poor
- Although values between the range 3.8-5.9 have a good correlation with the target it’s not the case for the corresponding train target percentage
- This feature may not be that relevant or important for predicting the quality of wine
For feature alcohol, we see that
- There is a clear increasing trend here, as the levels are increasing we see the target percentage improves
- This suggests that wine with more alcohol improves its quality
- Also, note that the last levels have significantly more target percentage as compared to the overall target percentage
- This feature could be most relevant or important for predicting the quality of wine
Table 2: Feature analysis of feature – alcohol
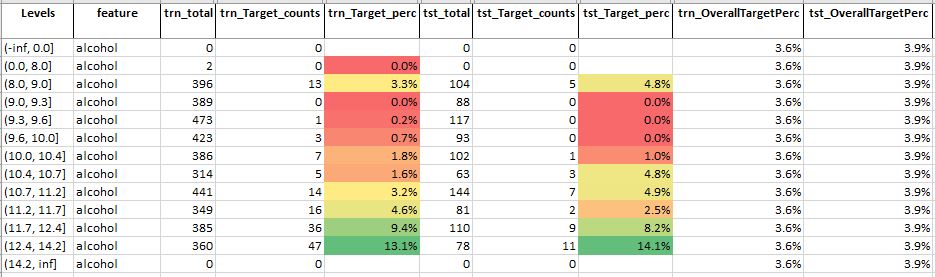
Source: Author
For feature sulphates, we see that
- On average, the levels have less than the overall target percentage
- Only the third level has the percentage of the targets slightly more than the overall train target percentage
- This feature may not be that relevant or important for predicting the quality of wine
Table 3: Feature analysis for feature – sulphates
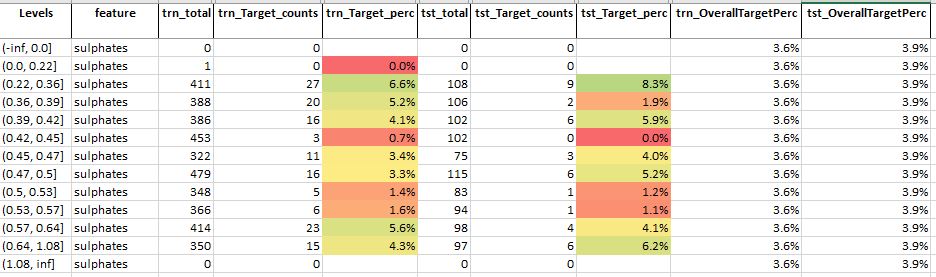
Source: Author
For feature pH, we see that
- There is a slight trend
- As the levels are increasing the target percentage is also increasing but the increase is not much compared to the overall target percentage
- This suggests that this feature is slightly important for predicting the quality of wine
Table 4: Feature analysis for feature – pH
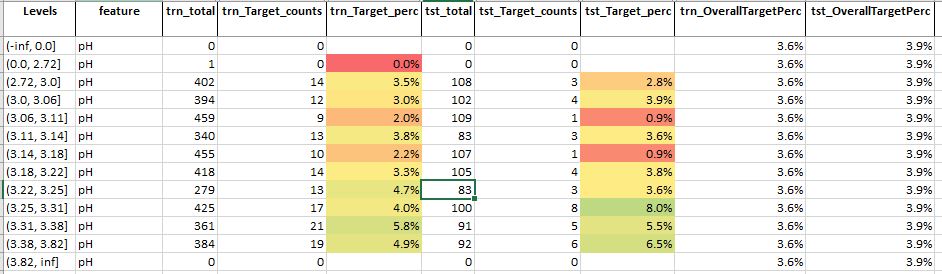
Source: Author
For feature volatile acidity, we see that
- The percentage of the target in each level is only slightly better than the overall target percentage
- This suggests, this feature may not be that relevant or important for predicting the quality of wine
Table 5: Feature analysis for feature – volatile acidity
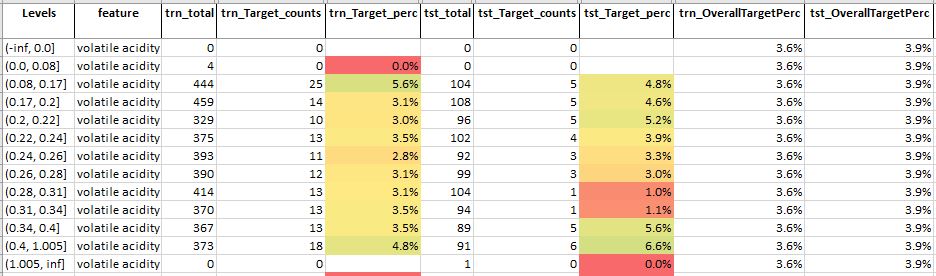
Source: Author
For feature citric acid, we see that
- There is no uniform trend between increasing levels & target percentage
- We do see a slight increase in the target percentage in the mid-levels
- This suggests that this could be a somewhat important feature and a mild level of citric acid helps to improve the quality of wine
Table 6: Feature analysis for feature – citric acid
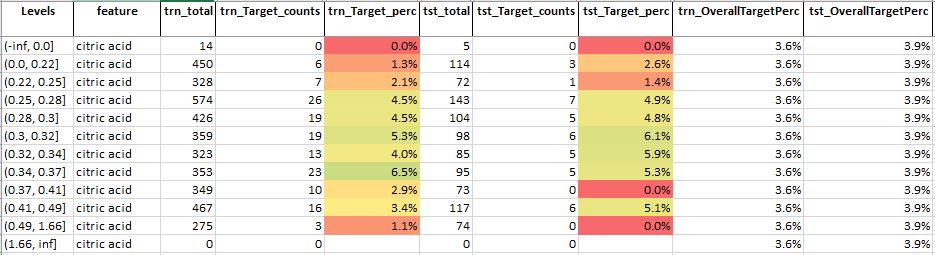
Source: Author
For feature residual sugar, we see that
- Similar to the observation made for the citric acid feature here also we see that the mid-level values are more suitable for good quality wine
- Also, note that compared to citric acid here the mid-level values show a higher target percentage
- This suggests that this feature could be a somewhat important feature – better than citric acid – for predicting the quality of wine
Table 7: Feature analysis for feature – residual sugar
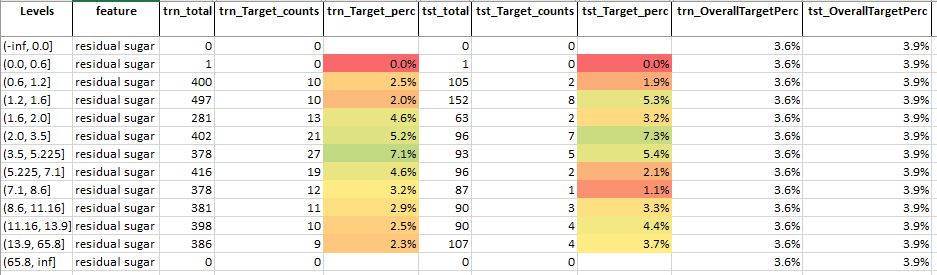
Source: Author
For feature chlorides, we see that
- Here the first few levels have a higher target percentage compared to the overall target percentage
- This suggests that this could be a slightly important variable
Table 8: Feature analysis technique for feature – chlorides
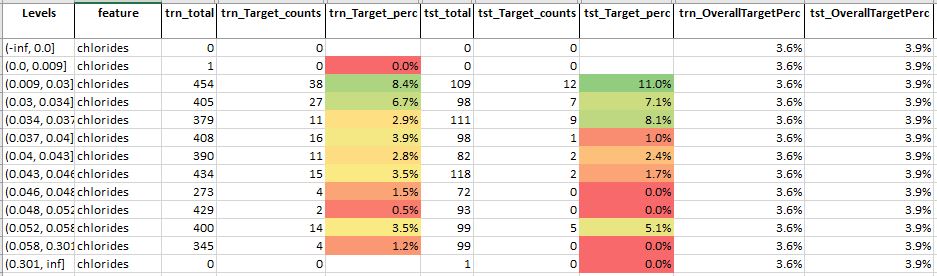
Source: Author
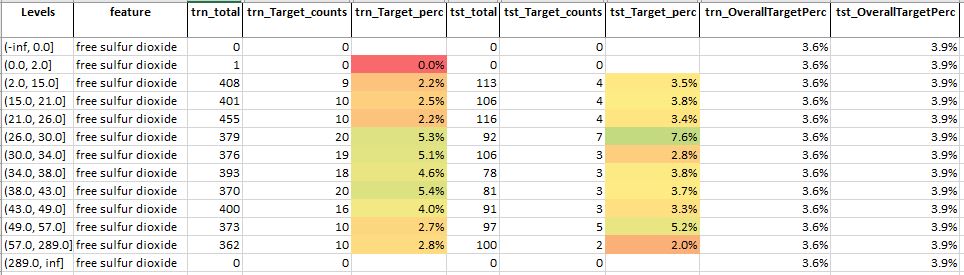
For feature free sulphur dioxide, we see that
- On average, the train target percentage is not that higher than the corresponding overall target percentage for different levels
- This suggests that this feature may not be much relevant or important for predicting the quality of wine
Table 9: Feature analysis technique for feature-free sulphur dioxide
Source: Author
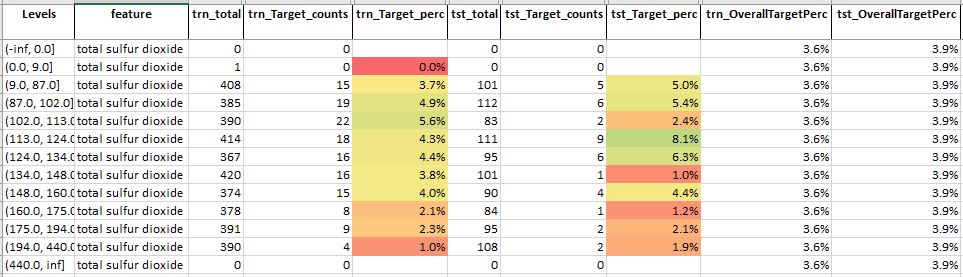
For feature total sulphur dioxide, we see that
- The Mid-level values do have a higher test target percentage than the overall target percentage but corresponding train target percentages are just slightly better than the overall target percentage
- This suggests that if this feature is included in the model will introduce somewhat of variance as the test data is seeing slightly different target percentage compared to train data
Table 10: Feature analysis technique for feature total sulphur dioxide
Source: Author
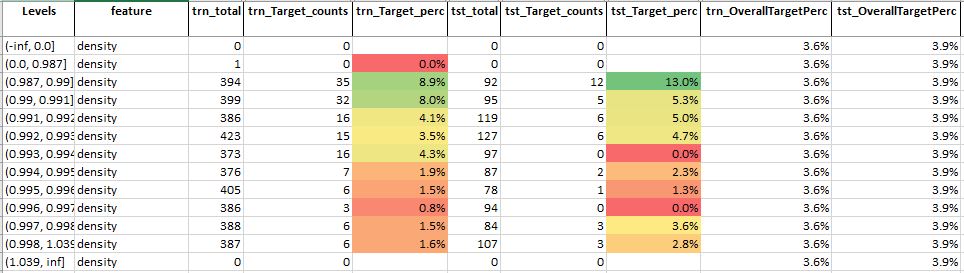
For feature density, we see that
- Similar to chlorides here also we see initial levels show a higher train target percentage compared to the overall train target percentage
- This suggests that this could be a slightly important variable
Table 11: Feature analysis for feature density
Source: Author
Great, we covered all the features!
The above analysis is very simple in nature but greatly helps us in giving a first-hand overview of the nature of the individual features & also the important levels too!
Conclusion
- A simple yet effective way to do the initial level of feature analysis is by simply analysing the key stats at each level of feature values.
- A supervised feature analysis approach described here can be applied to a variety of binary classification problems with all kinds of features – be it numeric or categorical.
- This simple feature analysis technique outlined here can complement the feature selection process and describes a very easy & visual way to look at the relationships between dependent & independent variables.
In particular, this simple analysis of comparing the target percentages in each level of feature values gave us a lot of insights. It helped us identify important features such as high alcohol value, it also helped us identify the important levels of certain features such as initial level of values for features chlorides and sulphates.
This analysis can further help in compressing the levels and bin the features to only include important levels thereby converting the continuous feature into a categorical type thereby reducing the overall complexity of the model.
Hope you will find this feature analysis technique useful in your work! Read the latest articles on our blog.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.






Hi, sir. I found this article very helpful. I'm new to python and there are no resources using the feature analysis function and i love how you explained it. do you mind sharing the complete code? Hope you can help me with this request, sir.