Introduction
Recommendation systems lie at the core of any good business. It is a very important tool that helps to attract new customers and retain existing customers by understanding their choices and recommending items which they might like. A good recommendation system greatly increases the overall experience of a user which in turn helps the business to grow. There are multiple recommender systems out there and many big corporations are out there like Netflix, Spotify and Google are still building and enhancing it to become the best. In this article, we will see how Lenskit will help us build a recommender system and how to evaluate different recommender algorithms to find the best one using the nDCG metric.
LensKit Introduction
LensKit is actually a Python library that has many tools for creating and testing recommendation systems. It is based on the Java counterpart of LensKit and ported over to Python language. With this library, we can execute, train and evaluate various recommender algorithms. With the help of the LensKit library, we can effectively help for better research into the domain of recommendation and find the best algorithm in the process.
It has an inbuilt scoring mechanism with which we can assign a score to each recommendation and find out how accurate they are or even find out the top 5 recommendations.LensKit also has a wide number of tools that can be used to implement and design new algorithms for a recommendation.
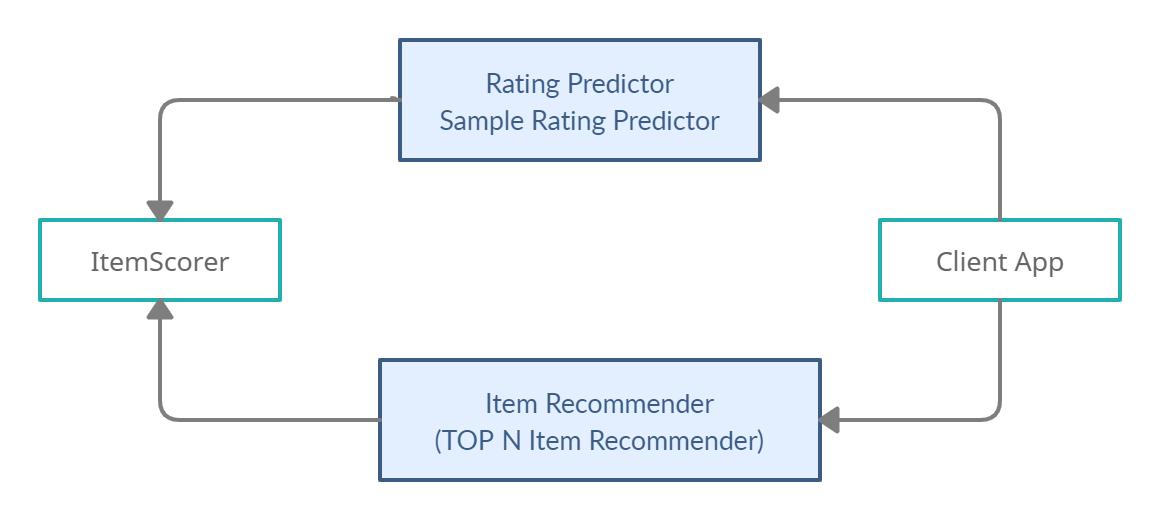
The following diagram explains the workflow of the model and the different parts of the toolkit. After using the Item Recommender system of the tool, we can provide our best recommendations. We can choose our own rating scales and accordingly give ratings to all the datasets. This rating will be compared after splitting the dataset into test and train and accordingly, a score will be assigned to the Algorithm.
We can install the library in our environment using pip and the following line of code :
Installing the libraries
!pip install LensKit !pip install surprise
Note: We will be using the surprise library for loading Dataset.
Building a Recommender System
We will be using a toolkit of Lenskit for nDCG scoring. The full form of nDCG is “Normalised Discounted Cumulative Gain” which is a measure by which we can measure the ranking quality. This metric was developed to evaluate a recommendation system and is compatible with Python DataFrame. We will be working with the 3 columns mentioned below :
- Item
- User
- Rating
We will load the dataset from the scikit-surprise library and then we will continue the Data Exploration
Loading the Dataset
Code :
import surprise
import pandas as pd
data = surprise.Dataset.load_builtin('ml-100k')
ddir = surprise.get_dataset_dir()
r_cols = ['user', 'item', 'rating', 'timestamp']
ratings = pd.read_csv(f'{ddir}/ml-100k/ml-100k/u.data', sep='t', names=r_cols,
encoding='latin-1')
ratings.head()
We can see that we have the columns of user, item, rating and timestamp.
Importing and Instantiating the Algorithm
Code :
from lenskit.datasets import ML100K from lenskit import batch, topn, util, topn from lenskit import crossfold as xf from lenskit.algorithms import Recommender, als, item_knn as knn import pandas as pd %matplotlib inline algo_ii = knn.ItemItem(20) algo_als = als.BiasedMF(50)
We import the necessary methods and initialise two algorithms :
- KNN
- Biased Matrix Factorization
Now we will create a recommendation function and using the LensKit tools, we can also evaluate at the time of creation to save some memory space. To get a proper estimation, we will first generate a recommendation and then eventually evaluate it and compare it with the other algorithm.
The following code will help to generate the recommendations in a modular format and can be reused for multiple algorithms. It will take the algorithm_name, Algorithm, train and test data as the input parameters.
Function Code :
def eval(aname, algo, train, test):
fittable = util.clone(algo)
fittable = Recommender.adapt(fittable)
fittable.fit(train)
users = test.user.unique()
recs = batch.recommend(fittable, users, 100)
recs['Algorithm'] = aname
return recs
Fitting the Recommendations
We can use the function to generate recommendations by a simple for loop which loops over the algorithms using the same dataset for a consistent scoring mechanism.
Code :
all_recs = []
test_data = []
for train, test in xf.partition_users(ratings[['user', 'item', 'rating']], 5, xf.SampleFrac(0.2)):
test_data.append(test)
all_recs.append(eval('ItemItem', algo_ii, train, test))
all_recs.append(eval('ALS', algo_als, train, test))
Output :

Note: You can ignore the warnings as they are regarding the runtime problems which are caused during the runtime of the code due to a large dataset
Evaluating the Recommendations
Now we will move on to the results and compare them but first, we will merge them into one DataFrame.
Code :
all_recs = pd.concat(all_recs, ignore_index=True) all_recs.head()
Output :
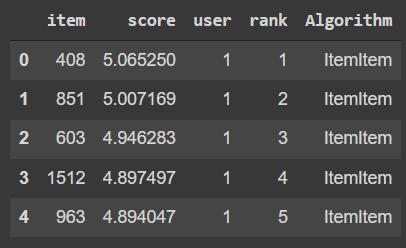
We can see that their output can be added to the dataset and we have a specific score with each item and the algorithm used to recommend those values. To get better results we can concatenate all the test data together into one singular Data Frame.
Code :
test_data = pd.concat(test_data, ignore_index=True) test_data.head()
Output :
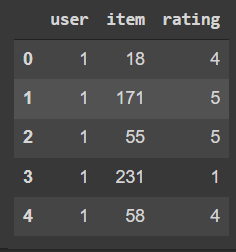
Now we will use a toll known as RecListAnalysis to analyse our recommendation which will help us to list all our recommendations and tests accordingly. We will use this to evaluate the nDCG values.
Code :
rla = topn.RecListAnalysis() rla.add_metric(topn.ndcg) results = rla.compute(all_recs, test_data) results.head()
Output :
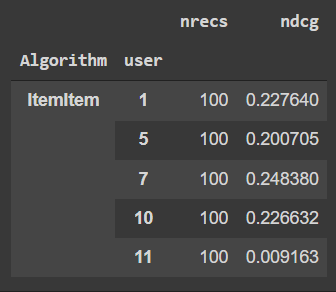
We have got out nDCG values in a proper DataFrame format which has been evaluated by the two algorithms and we will evaluate which algorithm has given us the best overall nDCG value
Code :
results.groupby('Algorithm').ndcg.mean()
Output :
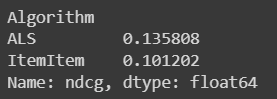
Now we will visualise our output and find the result.
Code :
results.groupby('Algorithm').ndcg.mean().plot.bar()
Output :
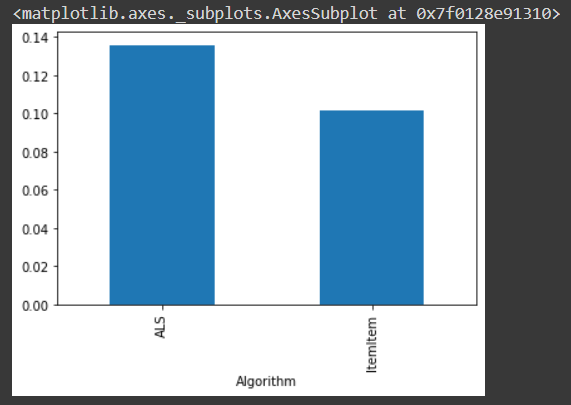
After analysing the two algorithms, we can find out that the ALS or Alternative Least Square algorithm is having the larger nDCG value.
Conslusion
So in this article, we discussed two algorithms and found out the better recommendation algorithm but this can be scaled to multiple algorithms and multiple datasets to find out the best overall algorithm or at least one algorithm which can excel over one. Feel free to do more research and tag me in future articles/code regarding this and will be more than eager to continue with this work.
Code link :
https://colab.research.google.com/drive/1nVfcvEuNDbRNzM2jztctX8eTolPz3JZt?usp=sharing
Lenskit Documentation link : https://lkpy.readthedocs.io/en/stable/
If you liked this article, then feel free to check out more articles here.
Arnab Mondal (LinkedIn)
Senior SDE: Python Developer | Freelance Tech Writer
I love to code and create new software for any purpose. I also love to play MMO and RTG games. Other hobbies include Exploring new places and restaurants and making new friends. Feel free to ping me on LinkedIn for any new ideas or same and if you need any help with any code too.





