
Image Source: Author
Introduction
A common problem with machine learning and deep learning models is ‘Overfitting.’ This means that the model accuracy is very high on the training dataset but fails to do so on the unknown data. To address the challenge of overfitting, we can increase the size of the dataset, i.e., exposing the model to new data for a better generalization. Additional data is not always available, can be challenging to gather, and is time-consuming and expensive. In such a situation, data scientists use a process called ‘Data Augmentation (DA).’ Using data augmentation, we can expand the size of the real data by several augmentation techniques. This process is beneficial in projects with smaller datasets and models that experience overfitting. Data augmentation helps in improving model accuracy.
Machine learning and deep learning models can use data augmentation. It is possible to augment image, text, audio, and video type of data. Several deep learning frameworks – Keras, Tensorflow, Pytorch, and more have built-in functionality for augmentation, while many open-source python libraries are developed especially for augmentation.
Augmentation techniques for different data types –
Image: The augmentation techniques for images allow scaling, flipping, rotating, cropping, change in brightness/contrast/sharpness/blur, color filtering, and many more.
Text: The augmentation techniques for text support NLP tasks by word/sentence shuffling, word replacement with synonyms, paraphrasing, and so on.
Audio and Video techniques can manipulate the data by introducing noise, changing speed, etc.
Image and Text Data Augmentation
Computer vision projects in healthcare, agriculture, manufacturing, automotive, etc., deal with image processing and seem to benefit from image data augmentation. Similarly, Natural Language Processing (NLP) applications with deep learning techniques benefit from text data augmentation.
This article focuses on image and text augmentations. All the generated augmented images and texts are unique, and we can use a combination of augmentation techniques to build a diverse dataset for model training.
It is important to understand that augmenting a dataset is efficient and easy using tools but choosing an appropriate option for augmentation or a combination of techniques requires a good understanding of the real dataset at hand and some level of experience.
There are multiple python data augmentation libraries for image and text, but we will explore the library ‘Augly’ and some augmentation techniques in this article.
What is AugLy?
AugLy is a recently launched Python open-source project by Facebook for data augmentation. AugLy aims to increase the robustness of AI models during training and evaluation. The library includes four modes (audio, video, image, and text) and provides over 100 data augmentation methods.
When working on a machine learning or deep learning project involving audio, video, image, or text datasets, this library can increase the data and improve the model’s performance.
How does AugLy Works?
The four modes AugLy library use the same interface. A function-based technique, as well as a class-based approach, can be used for data augmentation. Intensity functions define how intense the changes in the image will be. When the AugLy function is called, these are defined using parameters. For a deeper understanding of how the data was converted, the function gives information after transformation for the user.
Let us now look at some of the data augmentation techniques available with AugLy.
Image Data Augmentation with AugLy
We will start with the installation of AugLy by using the pip command –
pip install augly
The above command just downloads the required prerequisites for using the image and text modalities. To install additional dependencies for audio and video formats, use the following command –
pip install augly[av]
pip does not install python-magic. To install it, run the following command. It is necessary for some environments to run AugLy.
pip install python-magic-bin
If you are running this tutorial on Google Colab and experience a ‘No matching distribution found for python-magic-bin’ error, then use this command instead.
!sudo apt-get install python3-magic
For the image sub-library of AugLy, we will import the ‘imaugs’ submodel from ‘augly. utils,’ which is used to import the image for this example.
import os import augly.image as imaugs import augly.utils as utils from IPython.display import display
Here we define the image path for augmentation. We will use a sample image of a bird.
# Image path setting input = '/content/bird.jpg'
Image Scaling
AugLy’s’scale()’ function of imaugs can be used to scale the image. The approach requires an important parameter defining the image indicating a small or a large image. The image will be small if it is set to a low value. Otherwise, the image is enlarged.
# Image Scaling with small factor image = imaugs.scale(input, factor=0.1) display(image)

# Image Scaling with large factor image = imaugs.scale(input, factor=0.7) display(image)

Image Blurring
Using this option, we can reduce the image sharpness creating a blurred image.
# Image Blurring image = imaugs.blur(input, radius = 4.0) display(image)

Image Brightness
With this option, the brightness of the input image can be modified.
# Increasing Image Brightness image = imaugs.brightness(input, factor=1.2) display(image)

Image Darkness
We can reduce the brightness to make an image darker with the same brightness feature.
# Making Image Darker image = imaugs.brightness(input, factor=0.3) display(image)

Image contrast
We can change the contrast of the image using the following command.
# Changing Image Contrast image = imaugs.contrast(input, factor=2.7) display(image)

Image Flipping- Horizontal and Vertical
Using these commands, we can flip the image both horizontally and vertically.
#horizontal flip image_h = imaugs.hflip(input) display(image_h)
#vertical flip image_v= imaugs.vflip(input) display(image_v)

Image Grayscale
For changing the image to grayscale, we can use the following command –
#Grayscale image image = imaugs.grayscale(input) display(image)

Image Degradation- (Salt and Pepper Noise)
To add noise to the input image, use-
# Degrading Image Pixels image = imaugs.shuffle_pixels(input, factor=0.3) display(image)

Image Skewing
This feature helps to skew the image at a random angle.
# Image skew image = imaugs.skew(input) display(image)

Image Perspective Transform
We can perform image transformation by defining the sigma value i.e., standard deviation. A higher sigma value would mean a more intense image transformation.
# Image Perspective Transform aug = imaugs.PerspectiveTransform(sigma=20.0) image=aug(input) display(image)

Image Aspect Ratio
Using this technique, we can manipulate the aspect ratio, i.e., height and width of the image.
#Changing Aspect Ratio aug = imaugs.RandomAspectRatio() image=aug(input) display(image)

Image Cropping
It is possible to crop the image to the necessary pixel size using the following command –
# Cropping Image image = imaugs.crop(input,x1=0.2,x2=0.8,y1=0.2,y2=0.8) display(image)

Creating Memes with AugLy
Using the ‘meme format()’ technique, AugLy can be used to create a meme. This approach generates an image that represents a meme by providing both text and an image. For example, the image used includes the text ‘LOL.’ The code snippet below runs the ‘meme format()’ function and transforms the image.
# Creating a meme
display(
imaugs.meme_format(
input,
caption_height=75,
meme_bg_color=(0, 0, 0),
text_color=(255, 255, 255),
)
)

Parameters like ‘caption_height’, ‘meme_bg_color,’ and ‘text_color’ are used to customize how the meme is displayed. The RGB colour for black is (0, 0, 0), while the RGB colour for white is (256, 256, 256).
Converting Images to Screenshots
The ‘Compose()’ method is used to change the appearance of an image. This function takes a few more parameters for the new conversion like saturation and the type of overlay to apply for the image.
# Applying several transformations together to create a new image
aug = imaugs.Compose(
[
imaugs.Saturation(factor=0.7),
imaugs.OverlayOntoScreenshot(
template_filepath=os.path.join(
utils.SCREENSHOT_TEMPLATES_DIR, "web.png"
),
),
imaugs.Scale(factor=0.9),
]
)
display(aug(input))
AugLy provides many more augmentation techniques. You can explore these by using the command below, learning about them, and using them with your images.
help(imaugs)

Text Data Augmentation with AugLy
The first step is to import a text modality that includes text data augmentation methods.
import augly.text as textaugs
Then, make a sample text input.
# Sample text txt = "Hello, Good Morning! How are you?"
In each text, the ‘simulates_typos’ function can be used to augment text data with misspellings, keyboard distance, and swapping approaches.
aug_tx = textaugs.simulate_typos(txt) print(aug_tx)
We can add punctuation marks in each input text.
print(textaugs.insert_punctuation_chars(txt))
The ‘replace bidirectional’ approach of AugLy reverses each word or a part of a word in each input text and uses bidirectional markings to produce it in its original sequence. It reverses each word individually, preserving the word order even when a line wraps.
print(textaugs.replace_bidirectional(txt))
AugLy’s ‘Replace Upside Down’ function flips words in the text upside down depending on the granularity.
print(textaugs.replace_upside_down(txt))
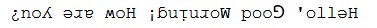
Conclusion
In this article, we covered the role of data augmentation in improving machine learning and deep learning models. Further, we saw different image and text augmentation techniques. The AugLy library supports several augmentation techniques. We have explored a few of these from the AugLy library.
Key takeaways from this article:
- Data shortage can be overcome by data augmentation as it allows expanding the dataset from available real data.
- Data Augmentation can improve the model performance and makes it more reliable.
- Image, Text, Audio, and Video formats of data can be augmented using the data augmentation libraries. There are several open-source Python libraries developed specifically for data augmentation.
- AugLy, an open-source data augmentation library developed by Facebook is a good choice for the different types of data as it supports more than 100 augmentation techniques and is easy to use for beginners.
That’s it!
I hope you enjoyed reading this article. The code for the above-discussed augmentations is available on my GitHub repository. You can try the augmentations shared in this article or explore other augmentations from the AugLy library.
Read the latest articles on our blog.
Author Bio
Devashree holds an M.Eng degree in Information Technology from Germany and a background in Data Science. She likes working with statistics and discovering hidden insights in varied datasets to create stunning dashboards. She enjoys sharing her knowledge in AI by writing technical articles on various technological platforms.
She loves travelling, reading fiction, solving Sudoku puzzles, and participating in coding competitions in her leisure time.
You can follow her on LinkedIn, GitHub, Kaggle, Medium, Twitter.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Devashree has an M.Eng degree in Information Technology from Germany and a Data Science background. As an Engineer, she enjoys working with numbers and uncovering hidden insights in diverse datasets from different sectors to build beautiful visualizations to try and solve interesting real-world machine learning problems.
In her spare time, she loves to cook, read & write, discover new Python-Machine Learning libraries or participate in coding competitions.

