DataFrame is the most popular data type in Spark, inspired by Data Frames in the panda’s package of Python. DataFrame is a tabular data structure, that looks like a table and has a proper schema to them, that is to say, that each column or field in the DataFrame has a specific datatype. A DataFrame can be created using JSON, XML, CSV, Parquet, AVRO, and many other file types. If required, a field in DataFrame can be used to create an entirely new DataFrame, all thanks to the nested schema that it supports.
After going through this article, the reader will have an idea of how the schema of the data frame can be used while parsing data. There are a lot of different file formats and each of them has its own pros and cons. In most use cases, the output file format differs from the input file format, and so issues like ambiguous column names and special characters in columns are a very common problem. This article will help the reader with an alternate way of solving such issues. These methods shown in this article are very useful but are less used as this is an unconventional way of solving such issues.
Datatypes in Spark
Spark supports all the traditional data types like String, Long, Int, Double, etc. A lot of documentation is available on them online. I will speak of 2 particular datatypes in Spark which are Struct and Array, which are very useful while working with semi-structured data like a JSON or an XML. In this guide, I will take a sample JSON and show you how a schema can be manipulated in Scala to handle data better when it is too complicated to work with.
So, let’s start with creating a JSON record and create a DataFrame from it.
import org.apache.spark.sql.types._
val sample_json_1="""{"a":{"b":"1","c":"2","d":[1,2,3,4,5],"e":{"key1":"value1","key2":"value2","key3":"value3"}},"d":1,"g":2}"""
val df_a=spark.read.json(sc.parallelize(Seq(sample_json_1)).map(_.toString))
val sch_a=df_a.schema

Now that we have the data frame and its schema, let’s see what operations are allowed on the schema.
Struct Data Types of Spark
A schema is a Struct of a list or array of StructFields. Struct is a data type that is defined as StructType in org.apache.spark.sql.types package. StructField is also defined in the same package as StructType. As per Spark’s official documentation, a StructField contains a lot of attributes but we will focus on just 3 of the attributes, which are field name, field data type, and field nullability. The field name and field datatype attributes are mandatory. To know all the attributes that it supports, please refer to the official documentation. Now to start with operations that can be done on a schema.
Listing fields, Their Names, and Indexes
You can get the list of all field names from the schema using either the “names” or “fieldNames” method on the schema as shown below
sch_a.names sch_a.fieldNames

Sometimes, it is not enough just to have the field names as the schema contains all the information of those fields. So to get the fields with all their attributes using the “fields” method.
sch_a.fields
To get the index of the field in the schema, “fieldIndex” can be used.
sch_a.fieldIndex("a")

DataTypes in StructFields
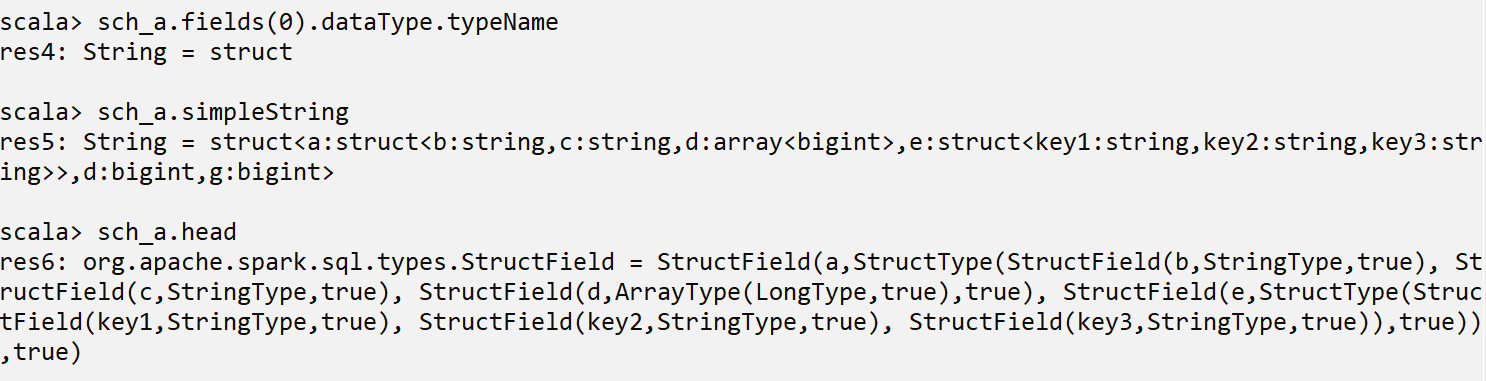
As mentioned earlier, StructField contains a datatype. This data type can contain a lot of fields and their data type in it, we will see it later in the guide. To get the data type of a field in the schema.
sch_a.fields(0).dataType.typeName
Datatypes as simple strings that can be used with Hive. These strings can be used as it is while writing the create table statement to define the datatype of the columns in that Hive table.
sch_a.simpleString
You can also go look for the first element in the schema using head operation.
sch_a.head
Adding New Fields to Schema
To add a new field to the schema it can either use the method “add” or the short hand “:+” as shown below
val add_field_to_schema=StructType(sch_a.add(StructField("newfield",StringType)))
val add_field_to_schema=StructType(sch_a:+StructField("newfield",StringType))

Deleting a Field From Schema
To remove a field from the schema “diff” method can be used as shown below. The field “g” is being removed from the schema.
val del_field_from_schema = StructType(sch_a.diff(Seq(StructField("g",LongType))))

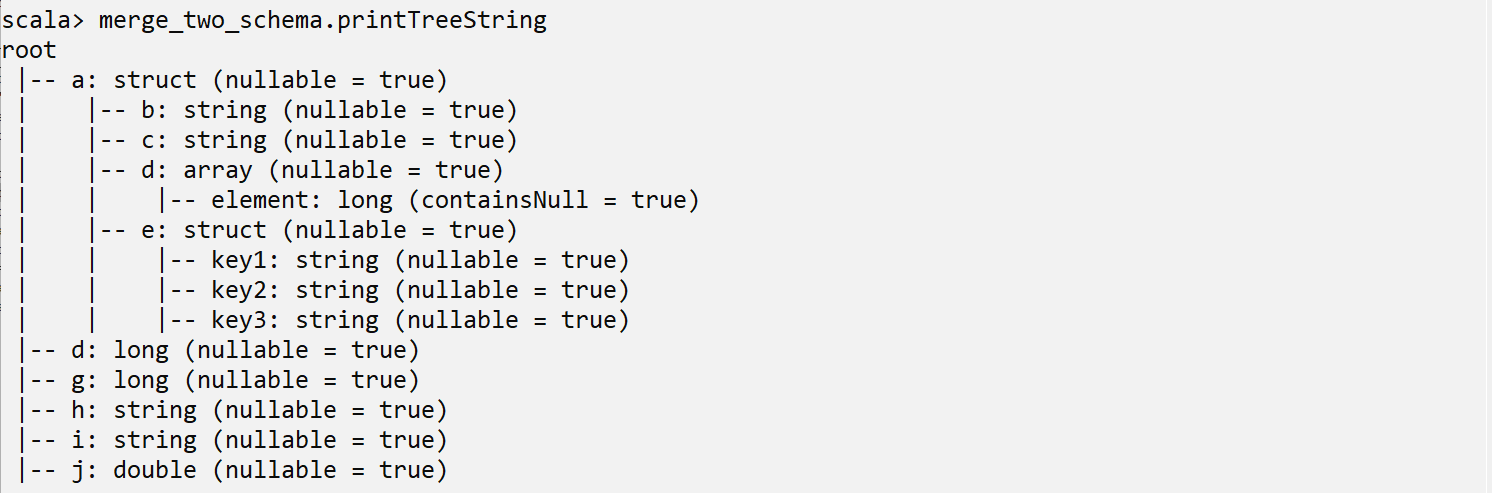
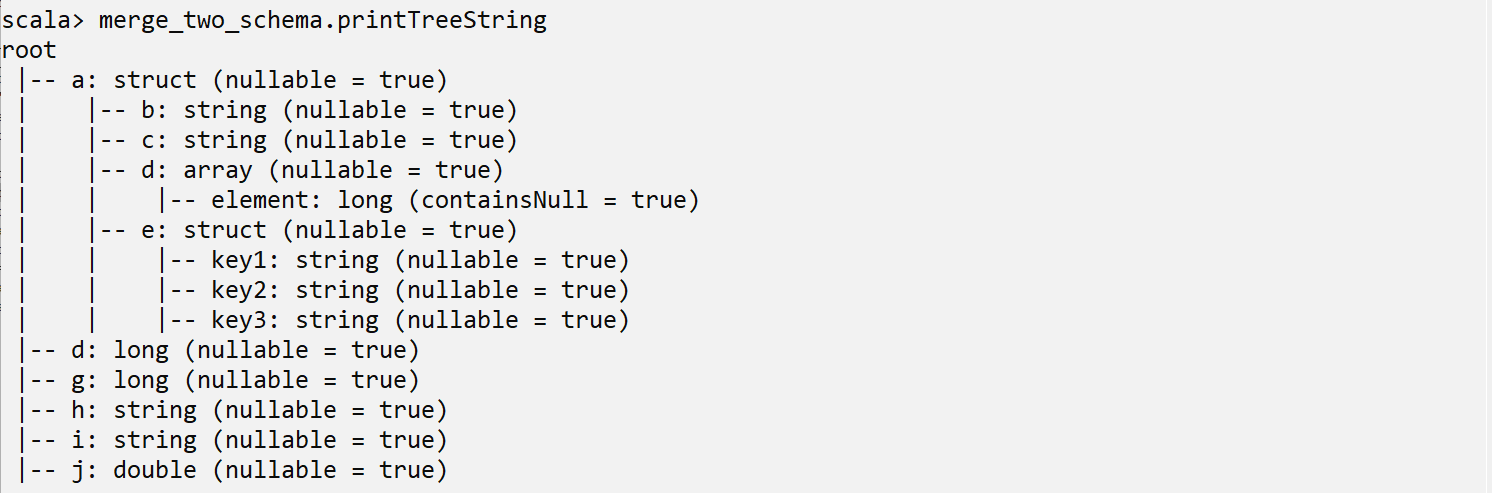
Concatenating 2 Schemas
Let say you have 2 schema and you need to merge them in 1 single schema. To do the same, follow below code block, where I am creating an additional DataFrame, so that we can have 2 schema to merge them.
val jsonb="""{"h":"newfield","i":"123","j":45.78}"""
val df_b=spark.read.json(sc.parallelize(Seq(jsonb)).map(_.toString))
val sch_b=df_b.schema

Now, to merge the schema of “df_a” and “df_b” data frames, the “++” operator can be used. It can also be used to merge 2 lists or arrays.
val merge_two_schema=StructType(sch_a++sch_b)
Working with Subfields
Now with the basic operations taken care of, let’s take an example where we want to read the JSON “Jason” in a data frame but we want to keep the field “a.e” as a string, you can see that initially when we read the JSON “Jason” into a data frame, the field “a.e” has been read as a Struct.
This can be done simply by changing the data type of the said field in the schema. To start with, if you look carefully at the output of the “sch_a.fields” output, you can see, there are only 3 elements namely “a”, “d” and “g”. Each element is a StructField and so consists of a field name and field datatype. The datatype of field “a” is StructType, which contains its children. So to make any changes to the data type of field “a.e”, we have to first get datatype of field “a”
val subfield_a=sch_a.fields(sch_a.fieldIndex("a")).dataType.asInstanceOf[StructType]

Now that we have the subfields of field “a” separated in a variable, we can update the data type of field “e”. unfortunately, there is no direct way of doing that, so we will remove the element first and then add it with the new data type.
val subfield_a_datatype_e=subfield_a.fields(subfield_a.fieldIndex("e")).dataType
val subfield_a_updated=StructType(subfield_a.diff(Seq(StructField("e",subfield_a_datatype_e))):+StructField("e",StringType))

Let’s understand that this newly updated subfield should be updated in the parent schema, as the datatype of field “a” before using it to read the “Jason” JSON, for the changes to reflect
val sch_a_update=StructType(sch_a.diff(Seq(StructField("a",subfield_a))):+StructField("a",subfield_a_updated))
In the below screenshots, you can see the difference between the outputs, when using the read with the modified schema, the json values in the “a.e” field remains unparsed and are read as string instead of Struct.


JSON of Schema
There are 2 more methods that I would like to specify, these are “json” and “prettyJson”, both of these are used to convert the Struct value into a json, I found them helpful with different use cases. You can explore them as well, below is an example

Conclusion
This guide is an attempt to show the readers that, just working with the schema can help implement a lot of functionalities, which may seem too complicated to implement, when they thought of it only from the data’s perspective. I hope this helps you with your projects. You can reach out to me on LinkedIn with your views and queries.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





