This article was published as a part of the Data Science Blogathon.
Introduction
As a Machine Learning Engineer or Data Engineer, your main task is to identify and clean duplicate data and remove errors from the dataset. It is good to spend some time preparing the data and making it reliable for the machine learning models. The better the quality of the data, the higher the accuracy of your model and the better the decision-making process.
Data Cleaning is not something new in machine learning. There are different techniques and packages already available on the internet today, using which you can efficiently clean and preprocess your data. However, many open-source packages are available for beginners and intermediate users. These packages are simple and free to use and clean dirty data. One such package is PyJanitor.
Pyjanitor is the most popular python package for data cleaning. As data engineers, we are always looking for ways to automate our data cleaning processes. Pyjanitor does just that by giving us the ability to clean and transform our data in Python.
This guide will cover the basics by giving you a complete guide to Pyjanitor and providing a working code of how you can start using it right away in your projects.
What is Pyjanitor?
Pyjanitor is an open-source python implementation of the R package Machine learning written on top of the popular python Pandas library. It provides a clean API for examining and removing noise from dirty datasets in machine learning. It is made for beginners and intermediate users and has a user-friendly interface and easy-to-use functions.
Creators of Pyjanitor were inspired by the simplicity and expressiveness of the Machine learning package of the R Statistical language ecosystem. They invented the Pyjanitor language to express data processing. Directed Acyclic Graph for the panda’s users. Pyjanitor allows you to fix incorrect, corrupted, formatted, redundant, or incomplete data within your dataset.
Why do Data Engineers Need Data Cleaning?
Data cleaning is a technique used by data engineers to ensure that the data used for the software or a project does not have any incorrect, corrupted, formatted, duplicate or inconsistent data points. The data engineers must ensure that the dataset collected is clean, reliable, and prepared for training purposes no matter what machine learning algorithm or use-cases are presented.
It is said that 70% of the time goes into data collection and preparing the data for training purposes. The better the data is presented to the model, the better the model will be able to learn the features from the dataset. Valuing your high data quality is critical because it is a fundamental aspect of data science analytics and a vital machine learning technique.
In most organizations, Data engineers work rigorously to fix errors and catch errors before processing by cleaning the noise from the data. They are liable to reformat and correct deformity in the dataset to ensure that all data used in the analysis will be of high grade and enables accurate decision-making.
What are the Benefits of using Pyjanitor?
Pyjanitor is an open-source package in Python built on top of the Janitor package in the R programming language. There are majorly two most significant advantages of using Pyjanitor.
First, it extends pandas with convenient data cleaning routines using method chaining. In method chaining, we combine two or more processes to decide the order of the actions taken instead of having an imperative programming style as with pandas. This concept is closely related to parallel processing.
The second most prominent advantage of using Pyjanitor is that it provides a cleaner, method-chaining, very-based API for ordinary pandas routines. Using these functions, we can perform various actions and pipeline them together.
Here is a working example of method chaining.
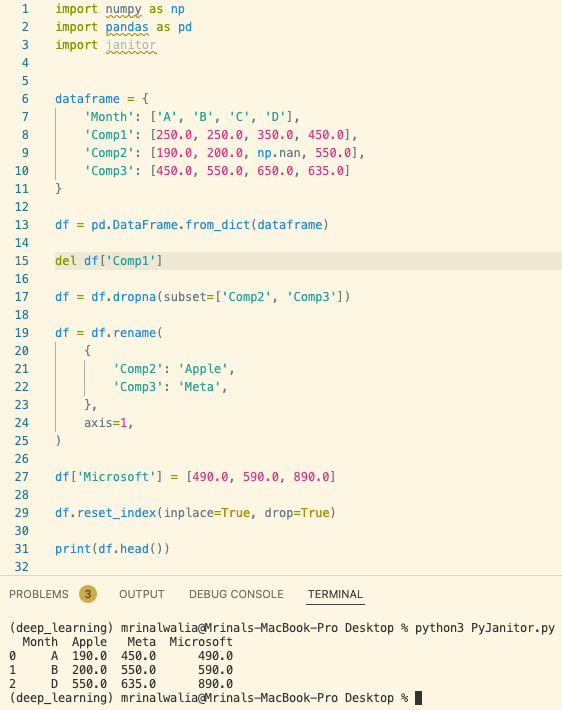
1) Here we will demonstrate how to create a pandas dataframe for a given dataset. Then we will see how to delete a column, drop rows with null values, rename columns, add a new column, and reset the index for the dataframe. In this step 1, we will use generic pandas and NumPy packages to perform all the above functions.
import numpy as np
import pandas as pd
dataframe = {
'Month': ['A', 'B', 'C', 'D'],
'Comp1': [250.0, 250.0, 350.0, 450.0],
'Comp2': [190.0, 200.0, np.nan, 550.0],
'Comp3': [450.0, 550.0, 650.0, 635.0]
}
df = pd.DataFrame.from_dict(dataframe)
del df['Comp1']
df = df.dropna(subset=['Comp2', 'Comp3'])
df = df.rename(
{
'Comp2': 'Apple',
'Comp3': 'Meta',
},
axis=1,
)
df['Microsoft'] = [490.0, 590.0, 890.0]
df.reset_index(inplace=True, drop=True)
print(df.head())
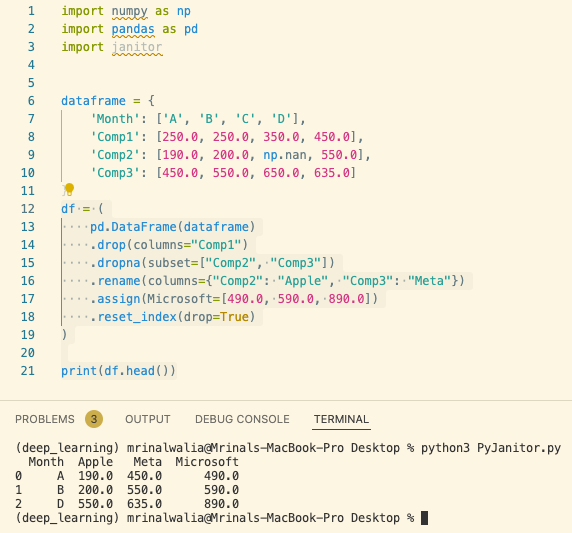
2) If you are an experienced Data Engineer with advanced knowledge of pandas and numpy, you are most likely to use a slightly more advanced functional API like the below:
import numpy as np
import pandas as pd
dataframe = {
'Month': ['A', 'B', 'C', 'D'],
'Comp1': [250.0, 250.0, 350.0, 450.0],
'Comp2': [190.0, 200.0, np.nan, 550.0],
'Comp3': [450.0, 550.0, 650.0, 635.0]
}
df = (
pd.DataFrame(dataframe)
.drop(columns="Comp1")
.dropna(subset=["Comp2", "Comp3"])
.rename(columns={"Comp2": "Apple", "Comp3": "Meta"})
.assign(Microsoft=[490.0, 590.0, 890.0])
.reset_index(drop=True)
)
print(df.head())
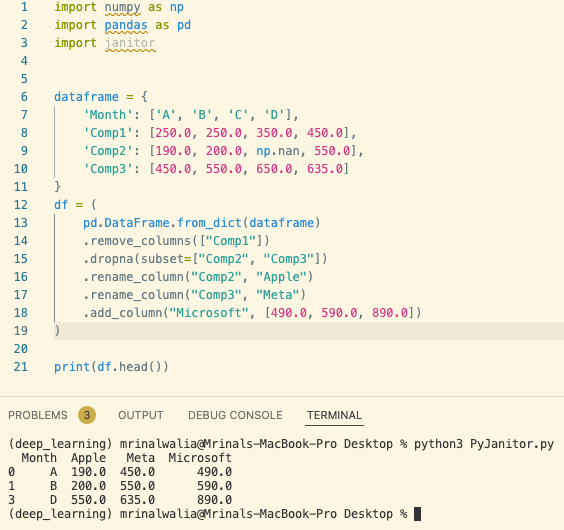
3) Now, we will see how Pyjanitor enables method chaining with method names (explicitly named as verbs) to describe the needed actions. We will repeat the same functions we did for the above two approaches.
import numpy as np
import pandas as pd
import janitor
dataframe = {
'Month': ['A', 'B', 'C', 'D'],
'Comp1': [250.0, 250.0, 350.0, 450.0],
'Comp2': [190.0, 200.0, np.nan, 550.0],
'Comp3': [450.0, 550.0, 650.0, 635.0]
}
df = (
pd.DataFrame.from_dict(dataframe)
.remove_columns(["Comp1"])
.dropna(subset=["Comp2", "Comp3"])
.rename_column("Comp2", "Apple")
.rename_column("Comp3", "Meta")
.add_column("Microsoft", [490.0, 590.0, 890.0])
)
print(df.head())
The above two advantages we have discussed help in writing cleaner code. It is also easier to remember the functions’ names, making the data preprocessing and cleaning process more straightforward.
Pyjanitor vs. Other Data Cleaning Packages
There are many other data cleaning libraries based on top of Python. Most of these libraries can be easily downloaded and are part of the open-source community.
Note: The motive behind this comparison is not to show that one library is better than the other or Pyjanitor is better among all libraries. My justification behind this comparison is to present my readers with all the available options and deliver them the best information possible. Based on your understanding, this comparison will help you decide which one suits your needs and which one you should select for your subsequent project.
1) Dora: Dora is an open-source library in Python that is used to improve the exploratory data analysis techniques and automate tasks that take a lot of time and processing. Dora provides various functions for feature extraction, data cleaning, feature selection, etc.
- Official Documentation = https://github.com/NathanEpstein/Dora
- Github Link = https://github.com/NathanEpstein/Dora
- Github Stars = 586
- Github Forks = 60
- Language = Python3
- How To Install = pip install Dora
2) PrettyPandas: PrettyPandas is an open-source pandas dataframe styler class. It was created to help you create report quality tables with a straightforward API. Like Pyjanitor, PrettyPandas also supports chaining commands, and it works seamlessly with the Pandas Style API.
- Official Documentation = https://prettypandas.readthedocs.io/en/latest/
- Github Link = https://github.com/HHammond/PrettyPandas
- Github Stars = 388
- Github Forks = 21
- Language = Python3
- How To Install = pip install prettypandas
3) DataCleaner: DataCleaner is an open-source python tool that automatically cleans datasets and prepares them for analysis. The data need to be in a format that pandas data frames can handle, and the rest is taken care of by DataCleaner.
- Official Documentation = https://github.com/rhiever/datacleaner
- Github Link = https://github.com/rhiever/datacleaner
- Github Stars = 993
- Github Forks = 202
- Language = Python3 & Shell
- How To Install = pip install datacleaner
4) Tabulate: Tabulate is an open-source library and a command-line utility tool for pretty print tabular data in Python. It is used to print small tables without hassle, tabular author data for lightweight plain-text markups, and the readable presentation of mixed textual and numeric data.
- Official Documentation = https://pypi.org/project/tabulate/
- Github Link = https://github.com/astanin/python-tabulate
- Github Stars = 1.2K
- Github Forks = 102
- Language = Python3
- How To Install = pip install tabulate
5) Pyjanitor: Pyjanitor is an open-source python implementation of the R package Janitor written on top of the popular python Pandas library. It provides a clean API for examining and removing noise from dirty datasets in machine learning. It is made for beginners and intermediate users and has a user-friendly interface and easy-to-use functions.
- Official Documentation = https://pyjanitor-devs.github.io/pyjanitor/
- Github Link = https://github.com/pyjanitor-devs/pyjanitor
- Github Stars = 888
- Github Forks = 142
- Language = Python3, jupyter notebook
- How To Install = conda install -c conda-forge pyjanitor
Pyjanitor: Installation, Implementation & Useful Functions
This section will see how to install Pyjanitor on your systems, then we will see some essential functionalities of the Pyjanitor Package, and we will see Pyjanitor in action. At last, I will show you how you can contribute and add new functionality to Pyjanitor effortlessly, and you can become an open-source contributor.
How to Install Pyjanitor?
There are three different ways to install Pyjanitor based on your systems and personal preferences. Let us see them one by one below:
- Pyjanitor is available under the PyPI library and can be installed from your terminal by simply entering the following command: pip install pyjanitor
- Pyjanitor is also available under the conda package manager, and it can be installed by opening the conda shell and entering the following command: conda install pyjanitor -c conda-forge
- The last approach to installing pyjanitor is using the pipenv environment manager. For using this approach, you need to enable prereleases dependencies: pipenv install –pre pyjanitor
Note: Pyjanitor is a python implementation of the Janitor library in R language. Hence, to run Pyjanitor on your systems, you need to have Python 3.6 or higher installed on your systems.
Useful Pyjanitor Functions For Data Engineers
Currently, Pyjanitor has a lot to offer to its user. However, it is open to assistance, and you can contribute to its code. We will see how to contribute to Pyjanitor at the end, but for now, let’s see the functions Pyjanitor has to offer.
- It can clean column names, including multi-indexes.
- It can remove empty rows and columns from the dataset.
- It can identify duplicate and redundant values in the data.
- It can encode columns as categorical values.
- It can split the dataset into features and targets for machine learning tasks.
- It can add new columns to the dataset.
- It can remove columns from the dataset.
- It can rename columns from the dataset.
- It can merge numerous columns into a single column.
- It can convert Matlab, excel, and unit data to Python DateTime format.
- It can expand a single column having delimited categorical values into dummy encoded variables.
- It can concatenate and de-concatenate columns depending upon a delimiter.
- It can do syntactic sugar for filtering the dataset based on the queries on a column.
- It has experimental submodules for finance, biology, chemistry, engineering, and pyspark.
Pyjanitor API Reference
Pyjanitor provides general API references for its functions across various domains. Some of them are below:
- API references for biology and bio-informatics-oriented data cleaning functions.
- API references for chemistry and chem-informatics-oriented data cleaning functions.
- API references for engineering-specific data cleaning functions.
- API references for finance-specific data cleaning functions.
- API references for machine learning specific tasks and functions.
- API references for misc mathematical operators.
- API references for time series-specific data cleaning functions.
- API references for misc internal Pyjanitor helper functions.
- API references for functions to augment XArray data arrays and datasets with additional features.
How to Implement Pyjanitor for Data Cleaning?
The idea behind implementing the Pyjanitor’s API is a two-fold:
- You can simply copy the R package function names. Enable the Pythonic use with method chaining or with pandas piping.
- Or you can add other utility functions that make it easy to do data cleaning and preprocess in pandas.
For implementation, we will use the same dataset we have used earlier while showing the working examples of method chaining.
import numpy as np
import pandas as pd
dataframe = {
'Month': ['A', 'B', 'C', 'D'],
'Comp1': [250.0, 250.0, 350.0, 450.0],
'Comp2': [190.0, 200.0, np.nan, 550.0],
'Comp3': [450.0, 550.0, 650.0, 635.0]
In general, there are three ways to use the Pyjanitor package.
1) The authors first recommended using the Pyjanitor’s functions as if they were native to pandas.
# After import, all functions are registered as a part of pandas import janitor # remove column names and duplicate rows df = pd.DataFrame.from_dict(dataframe).clean_names().remove_empty()
2) The following approach is to use the functional API of the janitor package.
from janitor import clean_names, remove_empty df = pd.DataFrame.from_dict(dataframe) df = clean_names(df) df = remove_empty(df)
3) The last approach is to use the pipe() method for chaining.
from janitor import clean_names, remove_empty df = ( pd.DataFrame.from_dict(dataframes) .pipe(clean_names) .pipe(remove_empty) )
How to Contribute and Add New Functionality?
In this section, we will see how you can contribute to Pyjanitor.
Keeping the simplicity and ease of users in mind, any developer or student can contribute a new feature to Pyjanitor, and you would be surprised to know that it is not that difficult. Follow the below steps to define a function, add a test case and send a feature request.
Step 1: The first contribution step is defining a custom function or a feature. This function should express a data processing or a data cleaning routine. Also, it should accept a dataframe as the first argument, and in return, it should output a modified dataframe. See the example code below to understand it better:
# Python library to write your own flavor of Pandas import pandas_flavor as pf @pf.register_dataframe_method def custom_data_cleaning_function(dataframe, argument1, argument2, ...): # Put data processing function here. return dataframe
Note: Pyjanitor uses pandas_flavor to register the features natively on a pandas dataframe. Check here for more details on pandas_flavor.
Step 2: Once you have defined a function, the next step is to contribute a test case to ensure that the function you have created is working as intended. You can follow the official contributions docs to add a test case.
Step 3: If you want to request a feature, you can post it as an issue on their GitHub page under the issue tracker page. It would be even good if you could put it in a PR, and Pyjanitors teams would be more than happy to guide you through the codebase. Amid this, you could easily contribute to the codebase of Pyjanaitor.
Note: As Pyjanitor is an open-source project currently managed by volunteers, any feature request you make will be prioritized accordingly due to no financial support. It sees what maintainers encounter as a need on their daily tasks and jobs, and Pyjanitor requests temper expectations accordingly.
Conclusion
Pyjanitor is a Python package that helps data engineers clean their data. It includes powerful data cleaning utilities and is designed to work with Pandas, NumPy, and Scikit-learn. No matter how fantastic machine learning algorithms you apply, if your data is incorrect or inconsistent, it can lead to false conclusions. So to avoid trouble, do not ingest a bunch of dirty data and clean it using Pyjanitor because your results are going out to be correct.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus





