This article was published as a part of the Data Science Blogathon.
Introduction
We can clearly see that sentiment analysis is becoming more popular as e-commerce, SaaS solutions, and digital technologies advance. We’ll go through how this works and look at some of the most common corporate applications. We’ll also discuss the analysis’ existing issues and limitations.
Sentiment analysis examines how a text expresses emotion. Customer feedback, survey replies, and product reviews are all frequent uses. This can be useful in various situations, including social media monitoring, reputation management, and customer service. For example, Analyzing thousands of product reviews might provide important feedback on pricing and product features.

The desire of people to interact with businesses, as well as the overall brand perception, is significantly influenced by public opinion. 93 percent of shoppers think online reviews influence their purchasing decisions, according to a Podium survey. After reading a few negative reviews, users may be less willing to give you a chance. They won’t look into whether or not the feedback was genuine. They’ll pick a different path. In this setting, companies that keep a close eye on their reputation can handle problems quickly and improve operations based on feedback. In the information era, such analysis enables the accurate measurement of people’s attitudes toward a company.
What is Sentimental Analysis?
Sentiment analysis, also known as opinion mining, is a natural language processing (NLP) technique for determining the positivity, negativity, or neutrality of data. It is frequently used on textual data to assist organizations in tracking brand and product sentiment in consumer feedback, and better understanding customer demands.

The tools assist businesses in extracting information from unstructured and unorganized text found on the internet, such as emails, blog posts, support tickets, webchats, social media channels, forums, and comments. To replace manual data processing, algorithms use rule-based, automatic, or hybrid techniques. Automatic systems learn from data using machine learning techniques, whereas rule-based systems execute sentiment analysis based on predetermined, lexicon-based rules. Both methodologies are combined in hybrid sentiment analysis.
While there are many different types of sentiment analysis techniques, fine-grained sentiment analysis, emotion detection, aspect-based sentiment analysis, and intent analysis are the most popular.
Types of Sentiment Analysis
Polarity categorization is an important part of sentiment analysis. The overall sentiment expressed by a paragraph, phrase, or word is referred to as polarity. This polarity can be measured using a “sentiment score,” which is a numerical rating. This score can be calculated for the complete text or for a single phrase.
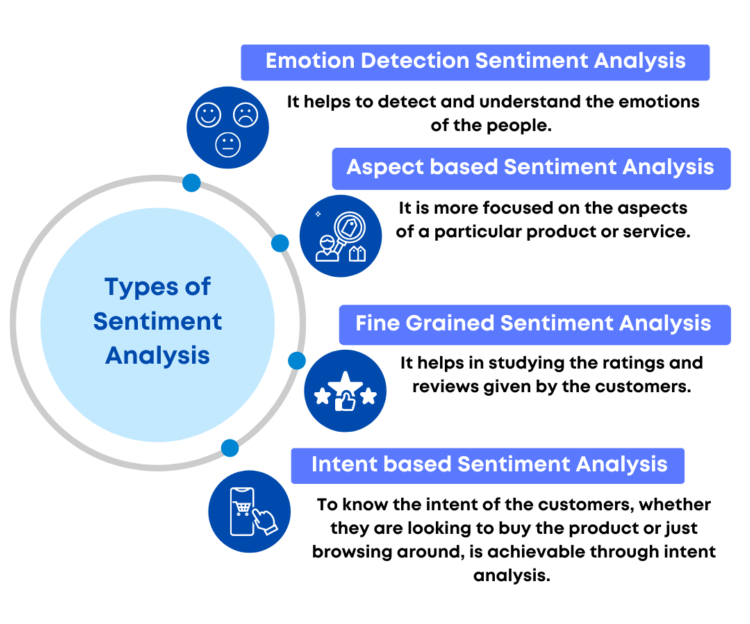
Depending on how you wish to interpret client feedback and inquiries, you can define and customize your categories to match your sentiment analysis needs. Meanwhile, these are some of the most common methodologies for sentiment analysis:
- Fine-grained Sentiment Analysis: breaks down polarity into smaller groups, usually highly positive to very negative, to provide a more specific level of polarity. This can be compared to a 5-star rating system in terms of opinion.
- Aspect-based Sentiment Analysis (ABSA): When it is related to a specific property or feature described in the text, it is most useful. ABSA is the process of discovering these traits or features and their sentiment. These features are referred to as “themes” at Thematic.
- Emotion detection: Rather than detecting positive and negative emotions, emotion detection detects specific emotions. Happiness, frustration, shock, anger, and grief are only a few examples.
- Intent-based: Intent-based analysis distinguishes between facts and opinions in a text. An online comment indicating dissatisfaction with changing a battery, for example, can motivate customer service to contact you to remedy the problem.
Why is it Important?
Sentiment analysis is snappily getting a pivotal tool for monitoring and understanding sentiment in all forms of data, as humans communicate their studies and passions more openly than ever ahead. Brands can discover what makes guests happy or unhappy by automatically assessing consumer input, similar to commentary in check replies and social media discourses. This enables them to knitter products and services to meet the requirements of their guests.

The following are some of the advantages:
- Sorting Data at Scale: Can you imagine going through thousands of tweets, customer service discussions, or survey responses by hand? There is simply too much corporate data to process manually. Sentiment analysis aids firms in efficiently and cost-effectively processing large amounts of unstructured data.
- Real-Time Analysis: Sentiment analysis can detect key concerns in real-time, such as whether a social media PR crisis is escalating. Is a disgruntled consumer about to leave? Sentiment analysis models can assist you in quickly identifying these types of circumstances so that you can take appropriate action.
- Consistent criteria: When it comes to determining the sentiment of a text, it’s estimated that just 60-65 percent of the time, people agree. Text sentiment tagging is a highly subjective process impacted by human experiences, thoughts, and beliefs. Companies can apply the same criteria to all of their data by adopting a centralized sentiment analysis system, which helps them enhance accuracy and generate better insights.
How does Sentiment Analysis Work?
The artificially intelligent bots are programmed to detect whether a message is favorable, negative, or neutral based on millions of pieces of text. Sentiment analysis divides communication into topic chunks and assigns each one a sentiment score.
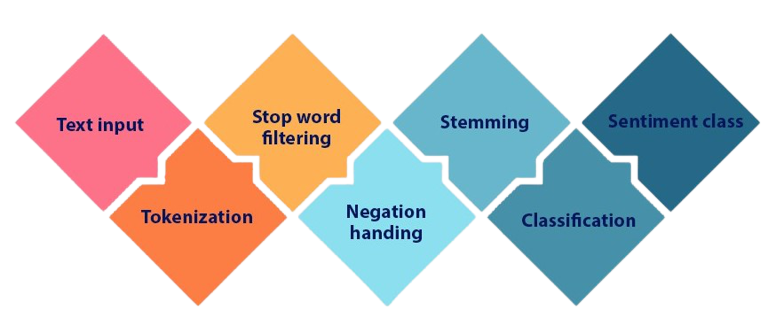
The process for basic sentiment analysis of text documents is simple:
- Break down each text document into its individual components (sentences, phrases, tokens, and parts of speech).
- Identify each phrase and component that carries a sentiment.
- Each phrase and component should be given a sentiment score (from -1 to +1).
- For multi-layered sentiment analysis, combine scores (Optional).
Deep Learning & Sentiment Analysis
Deep learning is worth investigating further since it produces the most accurate sentiment analysis. Traditional machine learning techniques, which involve manual work to define categorization features, dominated the area until recently. They also frequently overlook the significance of word order, and NLP has been changed by deep learning and artificial neural networks.
Well, the structure and function of the human brain-inspired deep learning systems. The accuracy and efficiency of sentiment analysis improved due to this technique. When using deep learning, a neural network can learn to self-correct when it makes a mistake. Errors in traditional machine learning require human involvement to correct.
Challenges with Sentiment Analysis
Inaccuracies in training models are usually the source of problems with sentiment analysis. Objectivity, or neutral-sentiment comments, are an issue for systems and are frequently mistaken. For example, if a consumer received the wrong color item and left a review like “The product was blue,” it would be categorized as neutral rather than negative.
Detecting sentiment might be difficult when systems can’t understand the context or tone. When the context is not provided, answers to polls or survey questions like “nothing” or “everything” are difficult to categorize. They could be characterized as positive or negative depending on the question. Similarly, irony and sarcasm are difficult to teach and often result in mislabeled emotions.
People’s statements can be conflicting. The majority of evaluations will include both good and negative feedback, which may be managed by analyzing sentences one at a time. However, the more informal the medium, the more likely people are to mix diverse points of view in a single sentence, making it harder for a computer to comprehend.
Use Cases
Organizations can utilize sentiment analysis technologies for a variety of purposes, including:
- Brand reputation management
- Customer feedback
- Crisis prevention
- Market research
- United Airlines
- Politics
Basic Python Implementation
NLTK is a standard Python package that comes with ready-to-use functions and utilities. It’s one of the most popular computational linguistics and natural language processing packages. In NLTK, a dataset is referred to as a corpus, and a corpus is essentially a set of sentences used as input. We’ll begin by importing some relevant Python libraries.
# Load and prepare the dataset
import nltk
from nltk.corpus import movie_reviews
import random
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
# Define feature extractor
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000]
def document_features(document):
document_words = set(document)
features = {}
for word in word_features:
features['contains({})'.format(word)] = (word in document_words)
return features
# Training of Naive Bayes classifier featurests = [(document_featres(d), c) for (d,c) in documents] train_set, test_set = featuresets[100:], featuresets[:100] classifier = nltk.NaiveBayesClassifier.train(train_set) # Test the classifier print(nltk.classify.accuracy(classifier, test_set)) classifier.show_most_informative_features(5) Output: Most Informative Features
contains(winslet) = True pos : neg = 8.3 : 1.0
contains(illogical) = True neg : pos = 7.3 : 1.0
contains(captures) = True pos : neg = 6.9 : 1.0
contains(turkay) = True neg : pos = 6.2 : 1.0
contains(doubts) = True pos : neg = 5.7 : 1.0
|
Conclusion
- Because of their potential applicability to a variety of samples, analysis, and opinion mining have become increasingly important in both commercial and research applications.
- The tools assist businesses in extracting information from unstructured and unorganized text found on the internet.
- You can define and customize your categories to match your sentiment analysis needs, depending on how you wish to interpret client feedback.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A graduate in Computer Science and Engineering from Tezpur Central University. Currently, I am pursuing my M.Tech in Computer Science and Engineering in the Department of CSE at NIT Durgapur. I expect to Postgraduate in the spring, 2022. A Grounded and Solution-oriented Computer Engineer with a wide variety of experiences. Adept at motivating self and others. Passionate about programming and educating the next generation of technology users and innovators.







Thanks for breaking this down. It was very helpful. nftbeyond.com