This article was published as a part of the Data Science Blogathon.
Introduction
One of the most widely used applications in Deep Learning is Audio classification, in which the model learns to classify sounds based on audio features. When given the input, it will predict the label for that audio feature. These can be used in different industrial applications like classifying short utterances of the speakers, music genre classification, etc.
In this guide, we will walk through a simple demonstration of audio classification on the UrbanSound8K dataset. We will write certain audio preprocessing functions, we will extract Mel Spectrogram from audio, then pass the features to a basic convolutional neural network and start the training, specifically focusing on the classification of particular urban sounds.
Our goal is to give an audio file as the input, then our model should determine whether the audio features contain one of the target labels.
Now let us know about the dataset.
Table of contents
Dataset
UrbanSound8K dataset contains 8732 labeled urban sounds from 10 classes, that is air_conditioner, car_horn, children_playing, dog_bark, drilling, enginge_idling, gun_shot, jackhammer, siren, and street_music. It also contained a CSV file UrbanSound8k.csv which contains meta-data information about every audio file in the dataset. For more information refer here.
You can download the dataset from here.
Mel Spectrogram
The non-linear transformation of the frequency scale based on the pitch’s perception is called the Mel scale. Mel Spectrogram is nothing but an audio spectrogram with a Mel scale.
The recipe to extract Mel spectrogram is:
– Extract STFT
– Convert amplitudes to DBs
– Convert frequencies to Mel scale
.png)
Below is a basic code snippet, that shows how to extract the Mel spectrogram and display it from audio. [Do pip install librosa and execute the below code].
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
y, sr = librosa.load('test_audio.wav')
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128, fmax=8000)
fig, ax = plt.subplots()
S_dB = librosa.power_to_db(S, ref=np.max)
img = librosa.display.specshow(S_dB, x_axis='time', y_axis='mel', sr=sr, fmax=8000, ax=ax)
fig.colorbar(img, ax=ax, format='%+2.0f dB')
ax.set(title='Mel-frequency spectrogram')
plt.show()
.png)
Requirements
For this demonstration we will be using PyTorch framework.
– Install the required PyTorch version from here.
– pip install pandas
– pip install torchsummary
Now once this is ready, we can proceed to the next step, where we will write the scripts to preprocess the audios.
Preprocessing
Let us import and required modules and then create a class called UrbanSoundDataset. Inside this class, we will have a __getitem__() function where we do all the preprocessing steps and it will return the signal and the label. We will also define different preprocessing functions like _cut_if_necessary() if the length of the audio is quite long, then we will cut it to the desired length to maintain uniformity between all the audio signals. _right_pad_if_necessary() in this function we will apply padding to the audio signal. _resample_if_necessary() here we will resample the signal to the desired sampling rate. _mix_down_if_necessary() here we will convert the audio signals to a mono channel. Let us implement the functions one by one.
from torch.utils.data import Dataset
import pandas as pd
import torchaudio
import torch
import osclass UrbanSoundDataset(Dataset):
def __init__(self, annotation_files, audio_dir, transformation,
target_sample_rate, num_samples, device):
pass
def __len__(self):
pass
def __getitem__(self, item):
pass
def _cut_if_necessary(self, signal):
pass
def _right_pad_if_necessary(self, signal):
pass
def _resample_if_necessary(self, signal, sr):
pass
def _mix_down_if_necessary(self, signal):
pass
def _get_audio_sample_path(self, item):
pass
def _get_audio_sample_label(self, item):
passWe will pass the annotation file, audio directory, transformation (Mel Spectrogram), sampling rate, number of samples, and the device as the inputs to the UrbanSoundDataset class. Below we are declaring the constructors.
def __init__(self, annotation_files, audio_dir, transformation,
target_sample_rate, num_samples, device):
self.annotations = pd.read_csv(annotation_files)
self.audio_dir = audio_dir
self.device = device
self.transformation = transformation.to(self.device)
self.target_sample_rate = target_sample_rate
self.num_samples = num_samplesThen to get the count of audio files we will implement a small function that returns the count.
def __len__(self):
return len(self.annotations)Then for the _cut_if_necessary() function, we will pass the signal, then we need to check if the number of samples in the signal is greater than the user-defined number of samples if that is true, and cut the signal to the desired number of samples. Basically, the signal shape looks like (1, num_samples) so we need to check if signal.shape[1] is greater than the number of samples and cut if it’s greater.
def _cut_if_necessary(self, signal):
# signal -> (1, num_sample)
if signal.shape[1] > self.num_samples:
signal = signal[:, :self.num_samples]
return signalThen for _right_pad_if_necessary(), we will do a similar procedure, here we will compare signal.shape[1] with the user-defined number of samples if it is less then we will pad the missing number of samples with zeros. We will use torch.nn.fucntional.pad(). This will return a padded signal.
def _right_pad_if_necessary(self, signal):
len_signal = signal.shape[1]
if len_signal < self.num_samples: # apply right pad
num_missing_samples = self.num_samples - len_signal
last_dim_padding = (0, num_missing_samples)
signal = torch.nn.functional.pad(signal, last_dim_padding)
return signalThen for _resample_if_necessary(), we will check if the sampling rate is equal to the user-defined sampling rate, if not then we will use torchaudio.transforms.Resample() give the target sampling rate and then pass the signal to it, this will return a resamples signal.
def _resample_if_necessary(self, signal, sr):
if sr != self.target_sample_rate:
resampler = torchaudio.transforms.Resample(sr, self.target_sample_rate)
signal = resampler(signal)
return signalThen for _mix_down_if_necessary() here we will convert all the audio to a mono channel in order to have the same input dimensions for the model while training. Some audios may have multiple channels, here if you check the shape of the signal, it will be in the form of (channels, num_smaples), then we need to check if the channel’s that is signal.shape[0] is greater than one, if yes reduce it to one by using the torch.mean(). This will return the signal with a mono channel.
def _mix_down_if_necessary(self, signal):
# signal = (channels, num_samples) -> (2, 16000) -> (1, 16000)
if signal.shape[0] > 1:
signal = torch.mean(signal, dim=0, keepdim=True)
return signalIn order to get the audio sample-path and its label, we will implement two small functions, which will return the audio path and its corresponding label.
def _get_audio_sample_path(self, item):
fold = f"fold{self.annotations.iloc[item, 5]}"
path = os.path.join(self.audio_dir, fold, self.annotations.iloc[item, 0])
return pathdef _get_audio_sample_label(self, item):
return self.annotations.iloc[item, 6]Now, the main part is implementing the __getitem__() function. First, we will get the audio sample-path, and then using torchaudio.load() we will load the audio, then we will pass the signal and sampling rate to the resampling function, then reduce the channel to mono, and then cut if required, and then pad if necessary, later we will apply the transformation and return the preprocessed signal and its label.
def __getitem__(self, item):
audio_sample_path = self._get_audio_sample_path(item)
label = self._get_audio_sample_label(item)
signal, sr = torchaudio.load(audio_sample_path)
signal = signal.to(self.device)
signal = self._resample_if_necessary(signal, sr)
signal = self._mix_down_if_necessary(signal)
signal = self._cut_if_necessary(signal)
signal = self._right_pad_if_necessary(signal)
signal = self.transformation(signal)
return signal, labelFor testing all the functions follow the below code snippet, where we declare our transformation method as Mel spectrogram and pass all the required parameters and then you can check the shape of the signal, it should be (1, Num_of_mels, Num_samples). Example shapes can be (1, 64, 10).
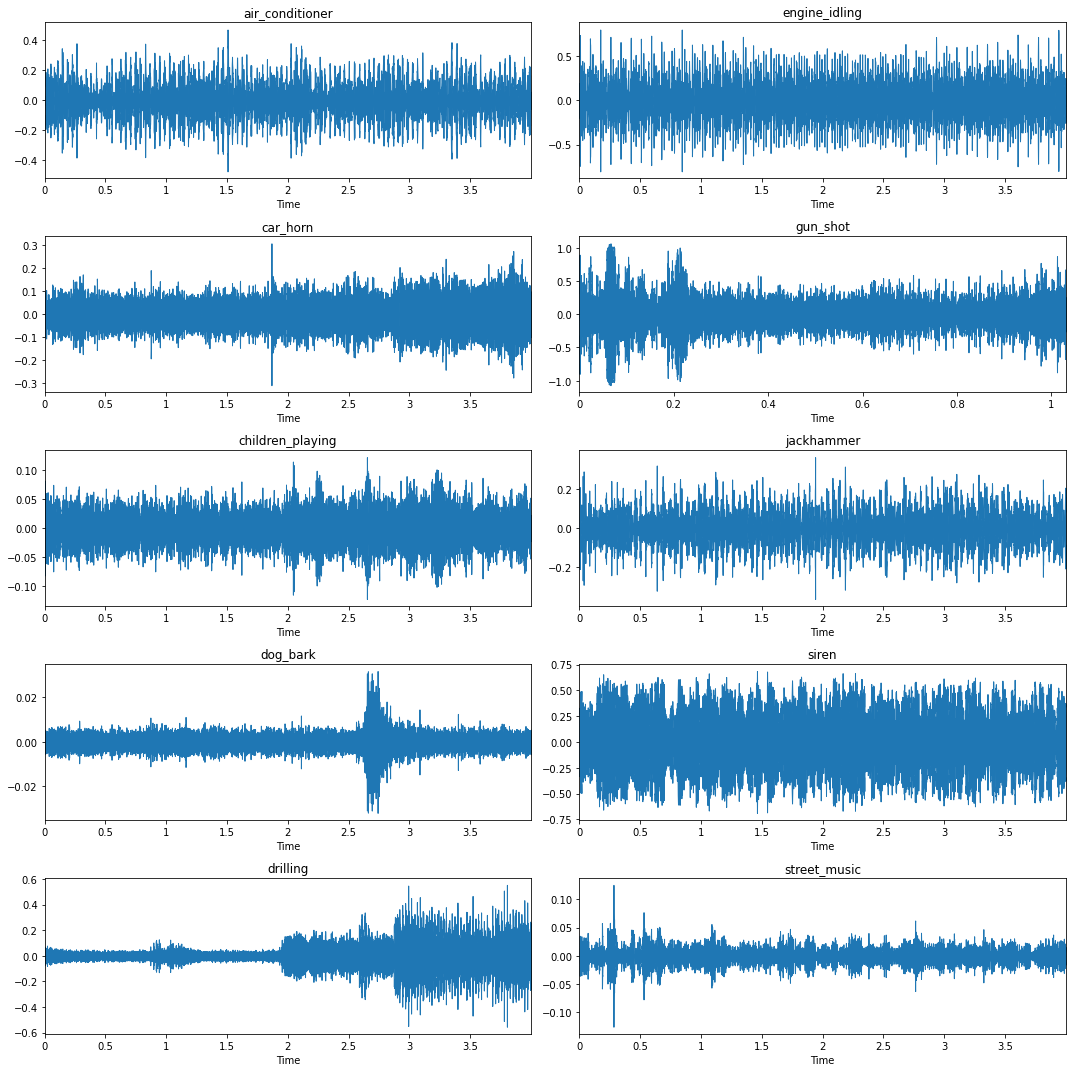
if __name__ == "__main__":
ANNOTATIONS_FILE = 'UrbanSound8K/metadata/UrbanSound8K.csv'
AUDIO_DIR = 'UrbanSound8K/audio'
SAMPLE_RATE = 22050
NUM_SAMPLES = 22050
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print(f"Using device {device}")
mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=SAMPLE_RATE,
n_fft=1024,
hop_length=512,
n_mels=64
)
usd = UrbanSoundDataset(ANNOTATIONS_FILE, AUDIO_DIR, mel_spectrogram,
SAMPLE_RATE, NUM_SAMPLES, device)
print(f"There are {len(usd)} samples in dataset")
signal, label = usd[1].png)
For more insights regarding the dataset, you refer to this notebook here.
Now let us build out CNN for training.
CNN Model
I hope you know how to build a CNN model using PyTorch. Here we will have a very basic CNN model so that we can get an intuition of training the model for audio classification.
First, we will create a class, our basic model will have four CNN blocks, a flatten layer, a linear layer, and finally softmax. The input channel of the first layer should be one, as we will pass the audio files with the only mono channel, then we will create three similar CNN block and then flatten it and pass it to the linear layer and since we have 10 classes in the dataset, the linear layer will output 10 probabilities, then we will pass it to the softmax to get the proper prediction. We will write a forward() which takes the input data and returns prediction.
from torch import nn
from torchsummary import summaryclass CNNNetwork(nn.Module):
def __init__(self):
super().__init__()
# 4 CNN block / flatten / linear / softmax
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=3,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=32,
out_channels=64,
kernel_size=3,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv4 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.flatten = nn.Flatten()
self.linear = nn.Linear(in_features=128*5*4, out_features=10)
self.softmax = nn.Softmax(dim=1)
def forward(self, input_data):
x = self.conv1(input_data)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.flatten(x)
logits = self.linear(x)
predictions = self.softmax(logits)
return predictions
if __name__=="__main__":
cnn = CNNNetwork()
summary(cnn.cuda(), (1, 64, 44))
# (1, 64, 44) is the shape of the signal which we obtain in dataset.py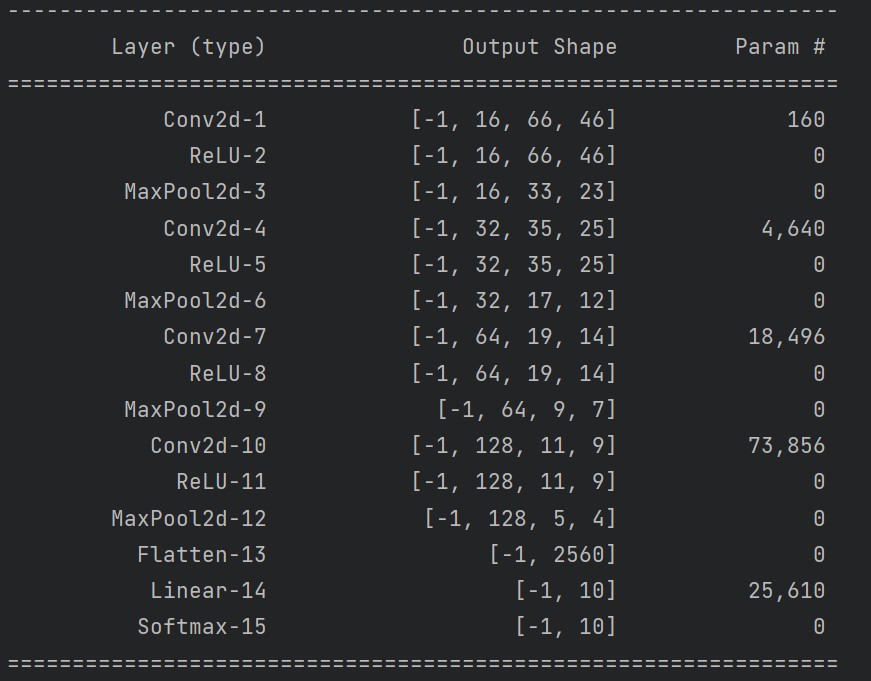
Now let us go for the training part.
Training
First, let us import and required modules and then declare the required variables. We will have a batch size of 128, we will train it for 50 epochs with a learning rate of 0.001.
import torch
from torch import nn
import torchaudio
from torch.utils.data import DataLoader
from dataset import UrbanSoundDataset
from modelcnn import CNNNetworkBATCH_SIZE = 128
EPOCHS = 50
LEARNING_RATE = 0.001
ANNOTATIONS_FILE = ‘UrbanSound8K/metadata/UrbanSound8K.csv’
AUDIO_DIR = ‘UrbanSound8K/audio’
SAMPLE_RATE = 22050
NUM_SAMPLES = 22050
Now, we will create a Dataloader function that takes training data and batch size as input and returns the train dataloader.
def create_data_loader(train_data, batch_size):
train_dataloader = DataLoader(train_data, batch_size=batch_size)
return train_dataloaderThen we will create a function called train_single_epoch() which takes out the CNN model, data loaders, loss function, optimizer, and the device (GPU or CPU) as the inputs. We will send both input and target labels to the training device and then pass the input to the model and then calculate loss and do back propagation.
def train_single_epoch(model, data_loader, loss_fn, optimizer, device):
for input , target in data_loader:
input, target = input.to(device), target.to(device)
# loss
predcition = model(input)
loss = loss_fn(predcition, target)
# backpropogation
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Loss: {loss.item()}")Now the main train function, here we will loop through the number of epochs and start training the model.
def train(model, data_loader, loss_fn, optimizer, epochs, device):
for i in range(epochs):
print(f"Epoch {i+1}")
train_single_epoch(model, data_loader, loss_fn, optimizer, device)
print("-----------------------------------------------")
print("Training completed!!")To run the training, follow the below code snippet, we will use GPU to train our model. First, we will instantiate the dataset, then we will get the preprocessed data using the UrbanSoundDataset class which we created. Then we will pass that data to the create_data_loader() function along with the batch size. Define the CNN model and we will be using CrossEntropy loss with Adam optimizer. All these parameters are passed to the train function and then we will save the model. Run the script and it will start the training.
if __name__ == "__main__":
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print(f"Using device {device}")
# instantiate dataset
mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=SAMPLE_RATE,
n_fft=1024,
hop_length=512,
n_mels=64
)
usd = UrbanSoundDataset(ANNOTATIONS_FILE, AUDIO_DIR, mel_spectrogram,
SAMPLE_RATE, NUM_SAMPLES, device)
train_dataloader = create_data_loader(usd, BATCH_SIZE)
cnn = CNNNetwork().to(device)
print(cnn)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=LEARNING_RATE)
# train
train(cnn, train_dataloader,loss_fn, optimizer, EPOCHS,device)
# save model
torch.save(cnn.state_dict(), "saved_model/soundclassifier.pth")
print("Trained model saved at soundclassifier.pth")Now once the training is complete, in order to do the inferencing follow the below code snippet.
Import the required modules and also create a list with the ten class names.
import torch
import torchaudio
from dataset import UrbanSoundDataset
from modelcnn import CNNNetwork
from train import AUDIO_DIR, ANNOTATIONS_FILE, NUM_SAMPLES, SAMPLE_RATEclass_mapping = [
"air_conditioner",
"car_horn",
"children_playing",
"dog_bark",
"drilling",
"engine_idling",
"gun_shot",
"jackhammer",
"siren",
"street_music"]
Now define a predict function that takes model, input, target label, and class mapping as input. Here we will pass the input to the training model and get the output class mapping and then compare it with the actual target label.
def predict(model, input, target, class_mapping):
model.eval()
with torch.no_grad():
predictions = model(input)
# Tensor (1, 10) -> [ [0.1, 0.01, ..., 0.6] ]
predicted_index = predictions[0].argmax(0)
predicted = class_mapping[predicted_index]
expected = class_mapping[target]
return predicted, expectedRun the inference script and check if the model is performing well.
if __name__ == "__main__":
# load back the model
cnn = CNNNetwork()
state_dict = torch.load("saved_model/soundclassifier.pth")
cnn.load_state_dict(state_dict)
# load urban sound dataset
mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=SAMPLE_RATE,
n_fft=1024,
hop_length=512,
n_mels=64
)
usd = UrbanSoundDataset(ANNOTATIONS_FILE, AUDIO_DIR, mel_spectrogram,
SAMPLE_RATE, NUM_SAMPLES, "cpu")
# get a sample from the us dataset for inference
input, target = usd[0][0], usd[0][1] # [num_cha, fr, t]
input.unsqueeze_(0)
# make an inference
predicted, expected = predict(cnn, input, target,
class_mapping)
print(f"Predicted: '{predicted}', expected: '{expected}'")You can try with more deep CNN, or go for a transfer learning approach. Play with different batch sizes and learning rates to improve the model performance.
The full code is available here.
Conclusion on Audio classification
This is the basic demonstration of end-to-end audio classification using deep learning. This can be applied to a wide range of applications where you have to deal with the audio classification problem. You can even build complex models to get better results from a particular audio data. Here many of the preprocessing techniques that are used here will be relevant to more complicated audio-related problems such as speaker diarization, automatic speech recognition, etc. Similarly, you can use it for language classification, emotion classification, and many more.
The following are some key takeaways from the article:
– Basic knowledge of how to implement audio classification using deep learning.
– Different audio preprocessing steps and functions can be applied to any audio data.
– Understanding of the audio classification pipeline.
– Given a trained model, inferencing to get the desired results.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I thrive on the thrill of the challenge, tackling complex problems and crafting innovative AI solutions that make a difference. Whether it's optimizing or building sustainable AI ecosystems, I believe in harnessing the power of AI for the greater good. Let's brainstorm, collaborate, and change the world, one byte at a time.






