This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we will be looking for a very common yet very important topic i.e. SQL also pronounced as Ess-cue-ell. So this time I’ll be answering some of the factual questions about SQL which every beginner needs to know before getting started with SQL database programming. Here we will not only discuss the technicalities of the SQL but also some functional knowledge that helps one to know their role and responsibility while working with database design and data analysis.
What is SQL?

SQL stands for Structured Query language, whenever we used hear "SQL" the straightaway first thing that comes to our mind is – designing the database SQL is not only about designing and creating a database but it can be a very important tool in the case of drawing insights from the database itself, SQL sometimes turns out to be an underrated skill when it comes to making business-based decisions but it is one of the important tools to make some reliable and efficient decisions.
Some basic database operations that SQL can perform:
- Creating a database
- Adding new data to the existing database
- Updating the existing data/schema
- Segmenting the data (Group By clause with aggregate function)
- Ordering the data based on the requirements (Order By clause)
Difference Between Database Administrator and Database Analyst

Peeps are often confused when they hear a job role like database administrator or database analyst though both kinds of technical person have to work with database only so the foundation may be same the task and the role defined for them is different. In this section, we will discuss the key difference between both the role and task which they perform.
1. Database Administrator
As this article is centric on SQL for data analytics so the below-mentioned points can be considered as something which data analysts need not perform because it is not/her goal.
- The abbreviation of a database administrator is DBA and he is the person who takes the complete responsibility to handle, control, and manipulate the data when I say to manipulate the data so here I mean that an individual can
update,deletethe data and also canchange the schemabe based on the requirements and authorities given to them.
- He/she is also responsible to keep the database up to date i.e. keep visiting the database design and updating it based on current scenarios.
- The individual who has a certain authority can manage the database accessibility which means he/she will handle the authority of accessibility to the database from other users and thus helps in maintaining security.
2. Database Analyst
Now, this is something to look for because here the roles and responsibilities that I’ll discuss will be based on the role of a database analyst.
- Where DBA handles the database design after that data analysis tasks are performed by the database analyst and his/her key responsibilities are to extract the key insights related to business and give the solution based on the historic data.
- When the DBA is updating the data in the database on the usual basis then he is not the right person to be responsible to filter out the data because that is one of the key jobs in the profile of a data analyst as he/she is responsible to extract all the data from the database and use effective queries to filter out only certain chunks of data according to certain requirements
- One of the most important roles of data analysts is to clean the data as all the data which gets updated in the database is not the relevant data hence it becomes essential to clean and transform it for further analysis.
How is SQL Used in Data Engineering?

Before understanding the use of SQL in data engineering we first need to understand that what is the role of a Data Engineer. The key role of data engineers are:
- Finding key insights: One of the works for data engineers is to find the relevant insight from the whole database.
- Interpreting data: Sometimes the data which is extracted from the database is not understandable so cleaning and transforming the same is done by a data engineer.
- ETL Process: An expanded form of ETL is extracting, loading, and transforming the data, and in this process, the data engineer plays a key role.
The last point discussed as the role is where the SQL has been used extensively i.e. The whole process of ETL: Extracting, Loading, and Transformation of data.
Basic SQL Queries
So in this section, we will be discussing some basic SQL queries that each Data Engineer should know. So the queries that we will be working on are listed below.
- SELECT and FROM
- DISTINCT
- WHERE clause
- Order By
- As
1) SELECT and FROM
This keyword forms one of the most basic SQL queries and at the same time very important too because without these keywords doesn’t matter how much analysis we have done and how many segments we have created the record will not be shown. Yes, you guessed that right! this query will be responsible to retrieve the data from the database based on some conditions.
Note: In this article, I’ll be working on the database which has ‘students‘ related data.
- Database name: “STM”
- Columns in the database:
- employee
- students
Now, let’s see an example of SELECT and FROM statement:
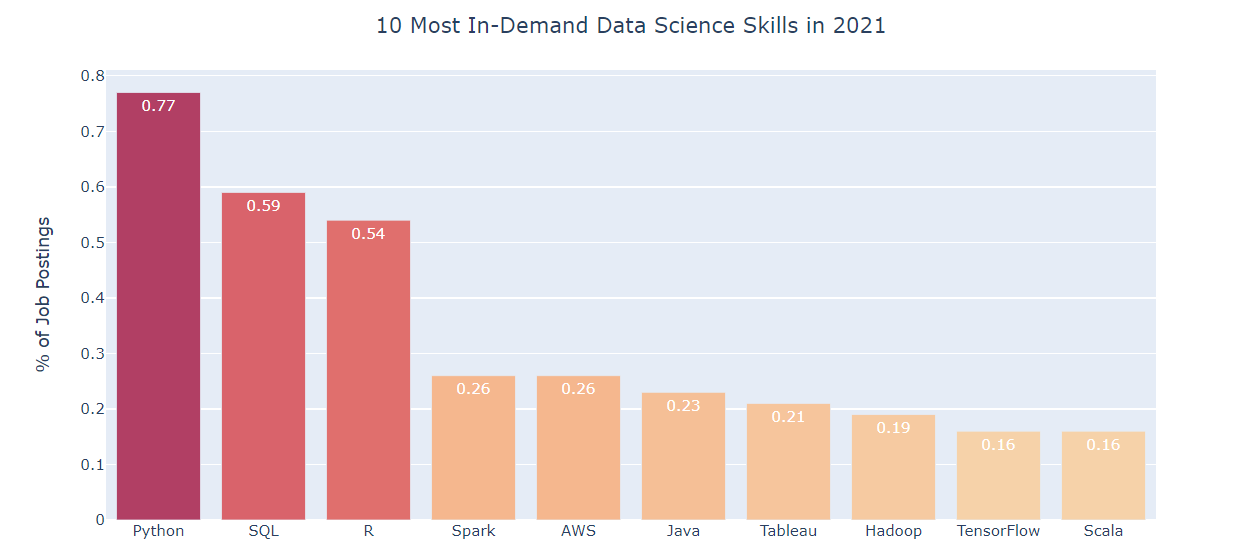
SELECT * FROM employee;
where “employee” is the name of the table
Output:
Inference: So from the above output it is clear that we have retrieved the whole table by using * just after the SELECT statement. I know the question will arise here what if we want only selected fields from the table?
It’s very easy just to replace the * with the name of the fields/field that you want to retrieve.
Syntax:
SELECTfield_1,field_2FROM Table_name;
2) Distinct
A distinct statement will return the records from the fields which only have unique values.
Let’s see an example:
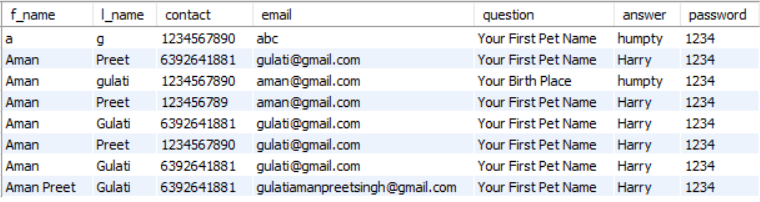
SELECT distinctf_nameFROM employee;
Output:

Inference: If we compare the above output and the previous output so we can see that in the previous output the f_name column was showing all the records i.e., even the repeated values as well (Aman) but when we have used DISTINCT so it has removed all the redundant values and returned only the unique values.
3) Where Clause
This is the ultimate clause that will help us to filter the records based on some logical conditions and it will return only those records which will satisfy those logical conditions.
In this particular example, we will be working on the student’s table. So first see that table’s schema and what data it has.
SELECT * FROM students;
Output:
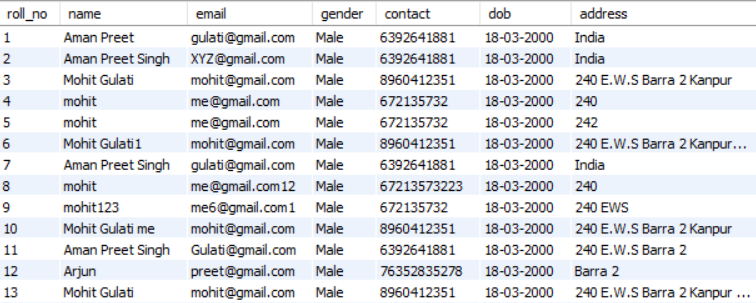
Now let’s see the example of where clause on the same table:
SELECTname
Output:

Inference: From the above output we can see that the “name” and “email” field is retrieved from the above query but the main thing to notice is that the data that we can see is the filtered data that has been filtered with the help of WHERE clause based on the logical condition which was that only Male‘s data will be retrieved.
4. Order By Clause
The Order By is a query keyword that helps us to sort the records either in the form of ascending order or descending order. Keeping the theoretical part away let’s just simply see the example for the same.
SELECT * FROM students ORDER BY roll_no DESC;
Output:
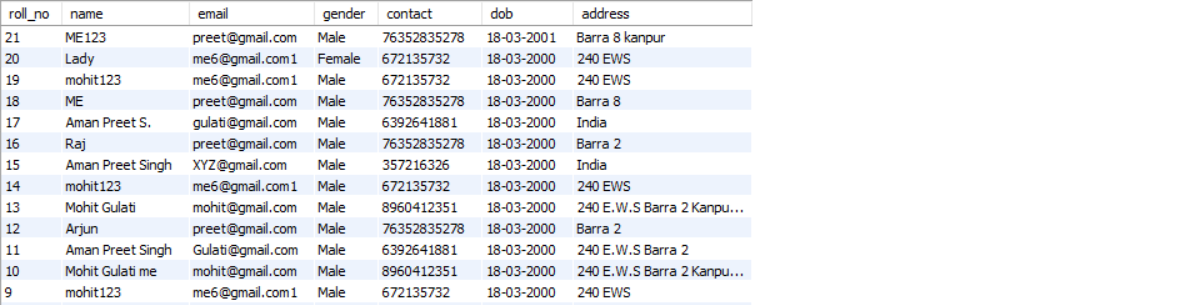
Inference: In the above output we can see that the data is sorted in the descending order by using the ORDER BY clause and DESC and if we want to sort back in the ascending order then we will replace the DISC with ASC though we need to know one thing that the ascending order is set by default.
5) AS
As is the keyword which is formally known as Aliases in SQL and mostly procedural oriented language. Aliases allow us to assign the custom name to a field.
Let’s see an example:
SELECT
Output:

Inference: In the above output if we will see the field name or email it is now changed to student_email because we use the ALIAS (AS) to change the name of the column though it won’t create any changes in the records this query is basically to make our SQL code more readable and understandable when we are using some complex queries.
Conclusion
Finally, we have come to the last section in which we will walk through whatever we have learned in this article.
- Firstly we discussed a very basic topic about the introduction of SQL and what the word SQL means!
- Then we leveled up and got through the roles and responsibilities of Data admin and Data analyst.
- Along with that we also discussed, how SQL is used in data engineering.
- Then finally we got our hands dirty when we practice some basic SQL queries.
Here’s the repo link to this article. Hope you liked my article on Introduction to SQL for Data Engineering. If you have any opinions or questions, then comment below.
Connect with me on LinkedIn for further discussion.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





