This article was published as a part of the Data Science Blogathon.
Healthcare Data using AI
Medical Interoperability and machine learning (ML) are two remarkable innovations disrupting the healthcare industry. Medical Interoperability is the ability to integrate and share secure healthcare information promptly across multiple systems. Medical Interoperability, along with AI & Machine Learning, creates a huge impact on the patient population and individuals by extracting a holistic view of patients’ medical history, building smart predictive models for better decision support and novel discoveries, helping in clinical trials, precision medicine, critical care, and many more cost-effective healthcare systems.
Problem Statement
With the digital transformation, health organizations are capturing a huge amount of electronic medical records (EMR) every day. Healthcare data is complex and highly secured under various protection laws. The data is stored in various non-standard formats; unlocking this data and making sense of it is a very complex business case. Modern patients and demanding consumers need information quickly and securely. Though health information exchanges (HIE) are helping healthcare organizations to build specialized networks that rely on interoperable systems to share electronic health records (EHR) seamlessly and securely, the challenges are there due to custom build EHR, budget restrictions, complex technology to extract that information is a standard format.
Overview of our Solution
What is FHIR?
Electronic health records (EHR) are the major source of healthcare data. FHIR is Fast Healthcare Interoperability Resources, an open-source standards framework for EHR. FHIR was launched by HL7 (Health Level Seven International), a non-profit standards development organization. FHIR standard helps to exchange structured medical data across various systems.
Medical information like doctor’s notes or lab report summaries or discharge summaries, or patient histories can be converted to FHIR standard framework; then, the data are extracted, transformed, and ingested into any data analytics or search system or ML system for further processing in various healthcare AI systems. FHIR is also widely supported by healthcare software vendors.
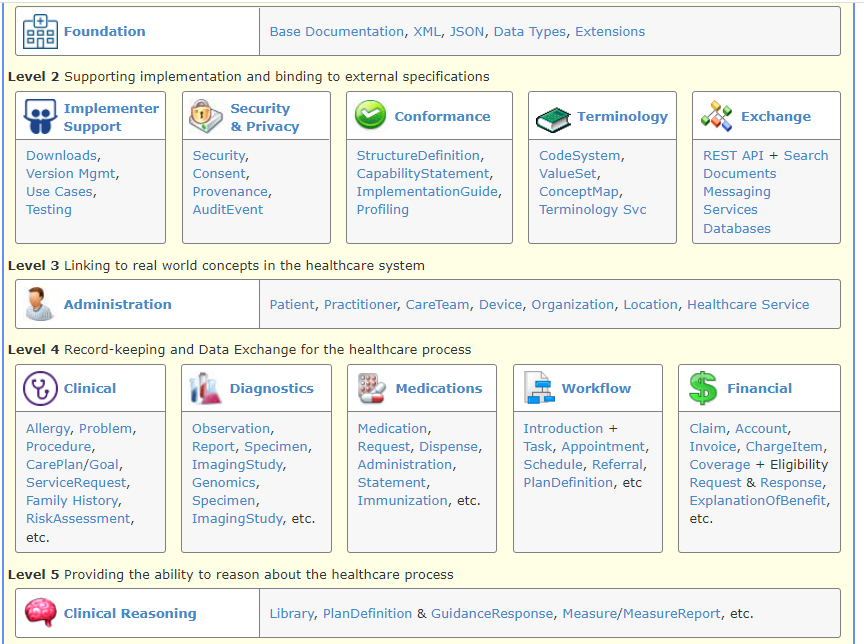
Source: http://hl7.org/fhir/
In this article, I am presenting the step-by-step approach to building a patient population analytical dashboard using Amazon Healthlake & Quicksight.
Sample dashboards can be downloaded from here.
Access Management
AWS IAM Access management and Key management system will be used. Make sure to build all the resources in one region and single account to avoid confusion.
Recommend to create a separate IAM role for this demo and grant the role required permissions – like S3full access, Healthlake full access, Quicksght Full access for simplicity.
The IAM role must have “trust relationships” with Healthlake, Sagemaker, and Quicksight.
Example trust policy is here.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "sagemaker.amazonaws.com"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"Service": "healthlake.amazonaws.com"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"Service": "quicksight.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
Architecture
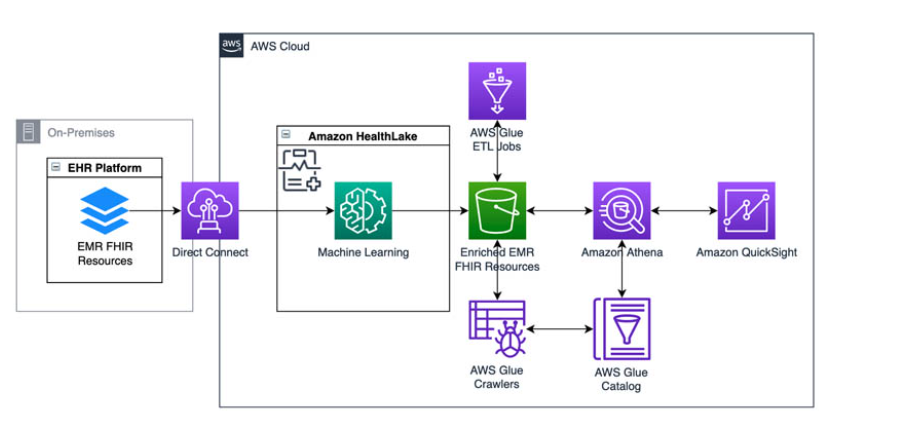
Source: https://aws.amazon.com/blogs/machine-learning/population-health-applications-with-amazon-healthlake-part-1-analytics-and-monitoring-using-amazon-quicksight/
The architecture depicts the real production use case. However, we will use Synthea to build the sample data to be used in this demo. We will enable the Healthlake feature to pre-load the Synthea data during the data store setup process.
In our demo, the Direct Connect and EHR Platform will be replaced by the Healthlake pre-load Synthea dataset.
The AWS Services will be used here:
- AWS Account
- AWS IAM Access Management
- AWS Healthlake
- AWS S3
- Sagemaker Notebook Instance (Jupyter Lab)
- Athena
- Quicksight
- AWS Glue
- CloudFormation

Cost
The cost will include the Healthlake store cost until you delete it. For 24 hrs with this data, the ~ cost is <$8.
The rest of the resources Sagemaker, Quicksight, Glue, S3, and Athena will cost <5$ each.
Hence the total cost of this demo is ~ $20 if you run this for 24 hrs.
Clean up immediately after the demo is done. Cleanup instructions are given at the end.
Healthlake Datastore Creation
Login to your AWS Account. Go to the Healthlake console and click on Create Datastore (if you are using it for the first time) Otherwise it will how the “View Data Store” tab.
Once open click on Create Data Store Tab. Enter the details as shown below :
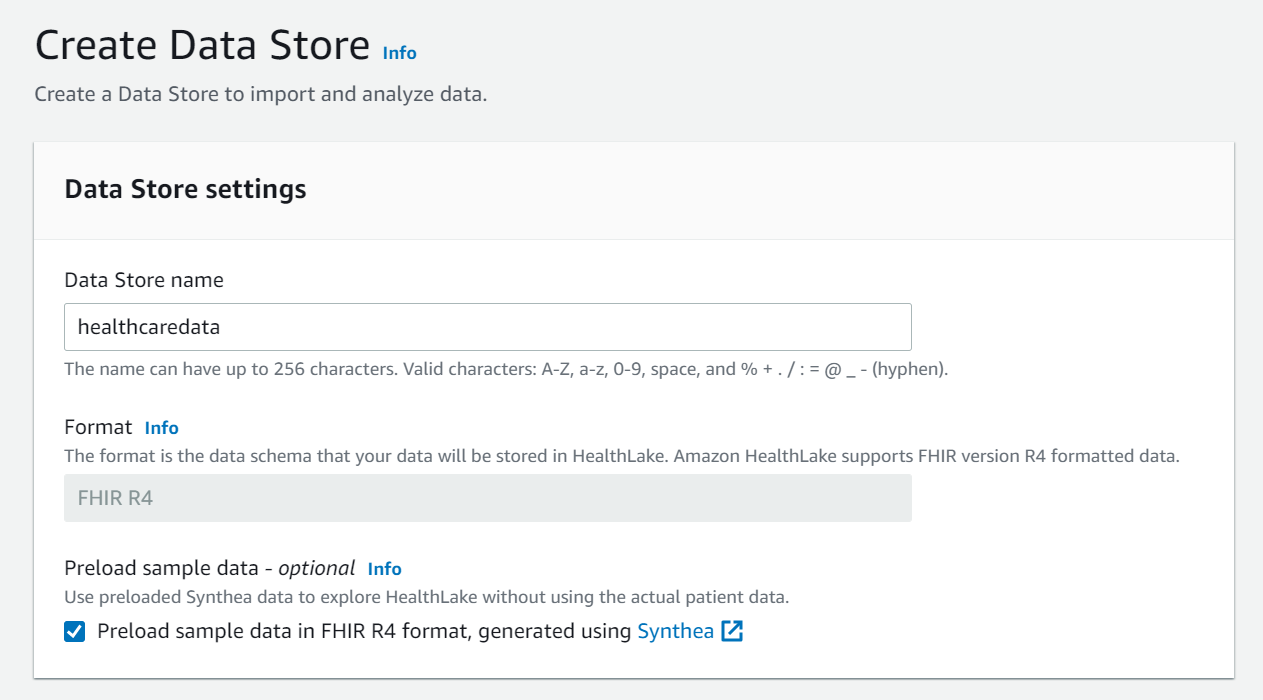
Then hit the Create Datastore tab to complete the process. The below screen will appear with the status of the Creating Data Store job.
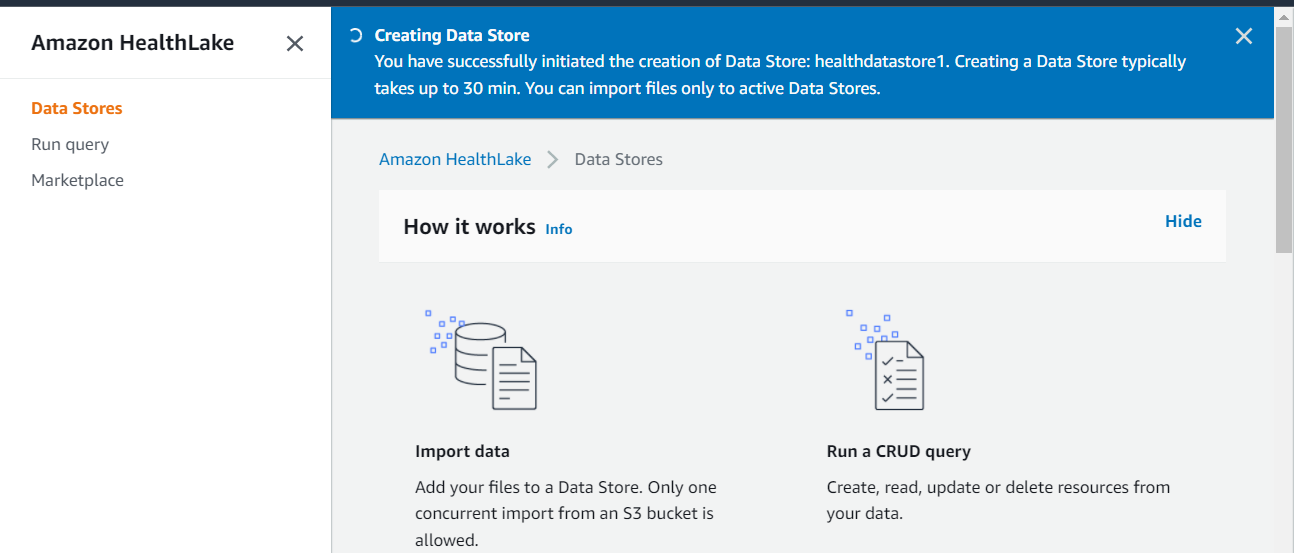
If you click the Data Store link on the left-hand side menu the status of the data store will be showing as creating, the format is FHIR R4.
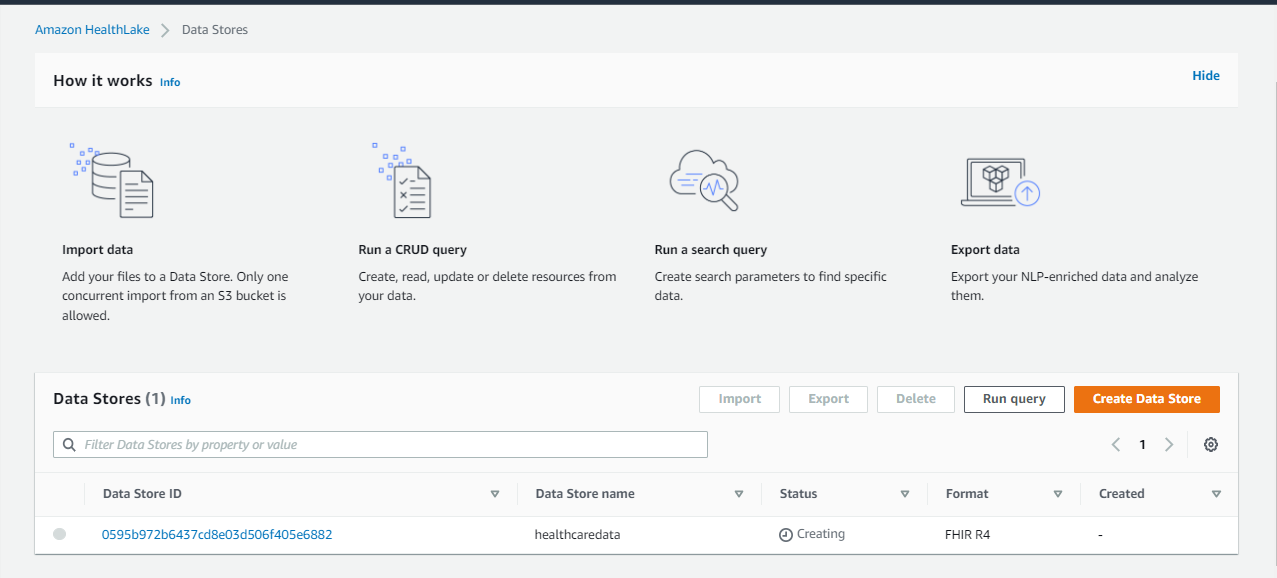
When the job is completed the status will be updated as Active.
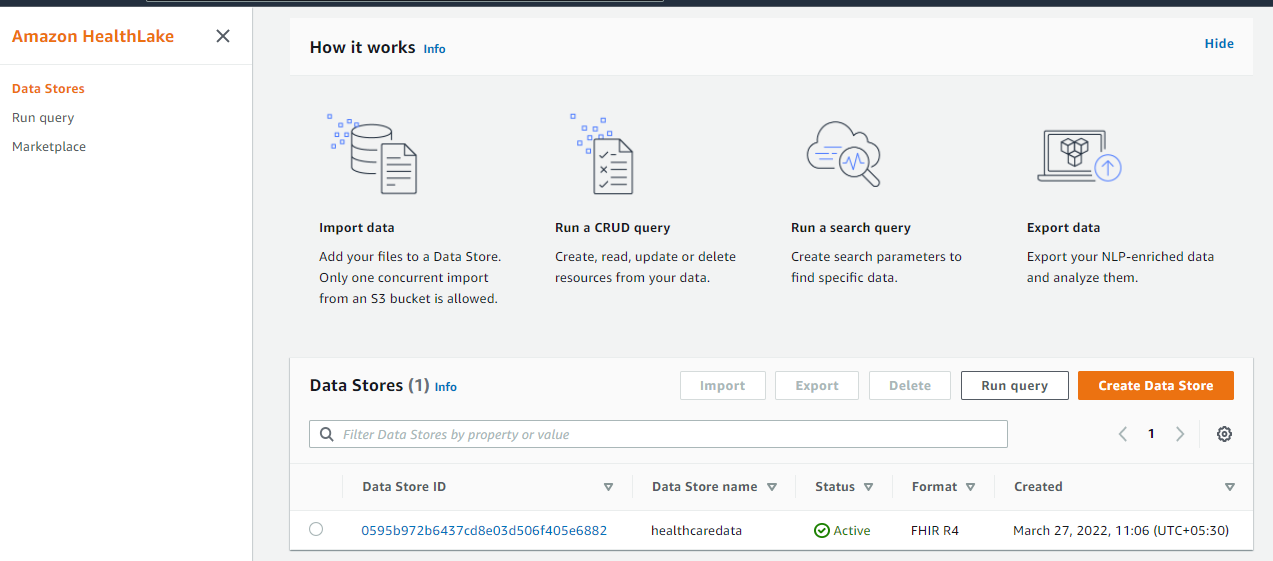
The datastore name is “healthcaredata” which will be used in this demo. Datastore id will be required for AWS CLI commands. AWS CLI commands are available to create data store, import data store, and export data store. I am using the AWS console for the setup.
Import Data to Healthlake
We have to use the Import data option in the below screen if we need to load the dataset from the AWS S3 bucket. Here we have pre-loaded the Synthea dataset in the Healthlake datastore during the creation process. Hence we will proceed with the data “Export” steps now.
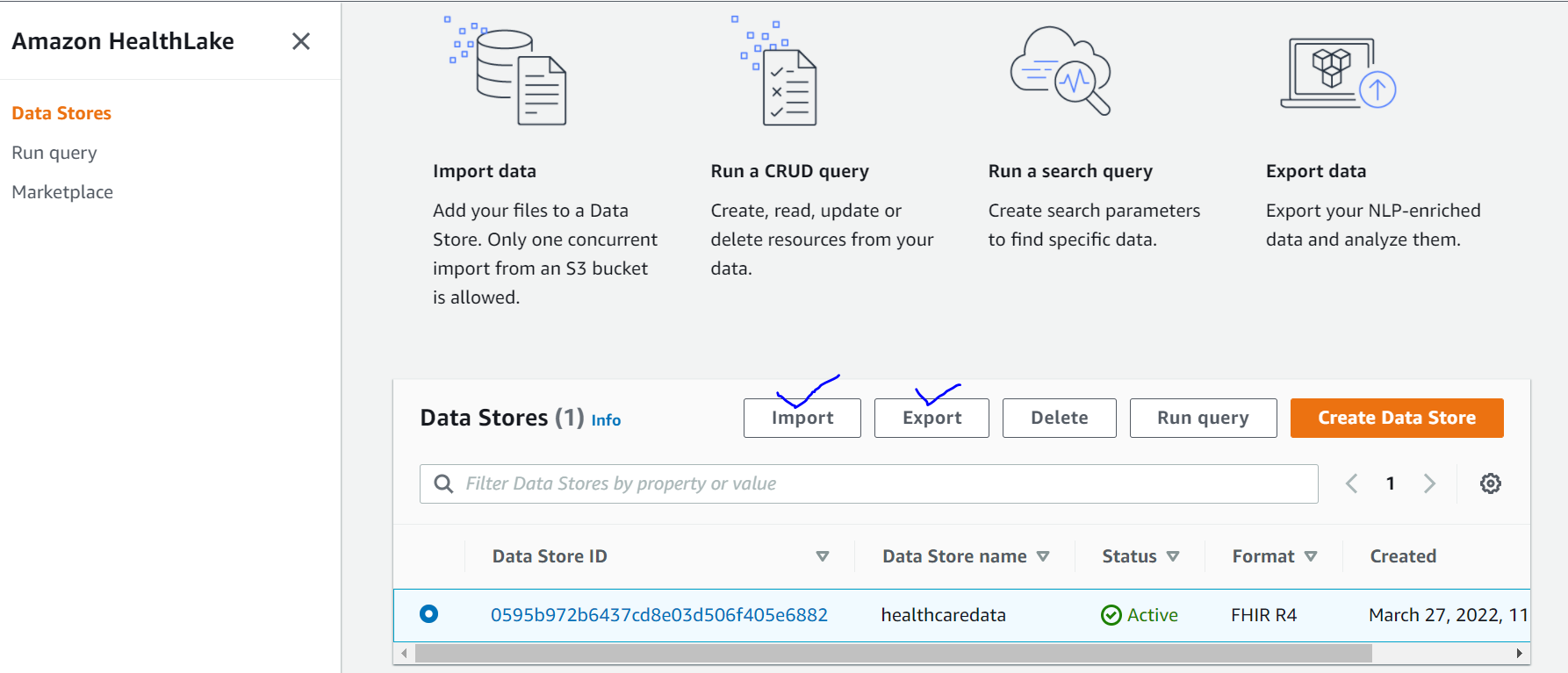
Export Healthlake Data
- Click the Export Data Tab
- Enter the data source location as an S3 bucket. I have created an s3 bucket named “healthlakedata” to store the export data in s3://healthlakedata
- Select the AWS KMS Key by searching the list or create a new AWS KMS Key which will encrypt the data in the Healthlake data store.
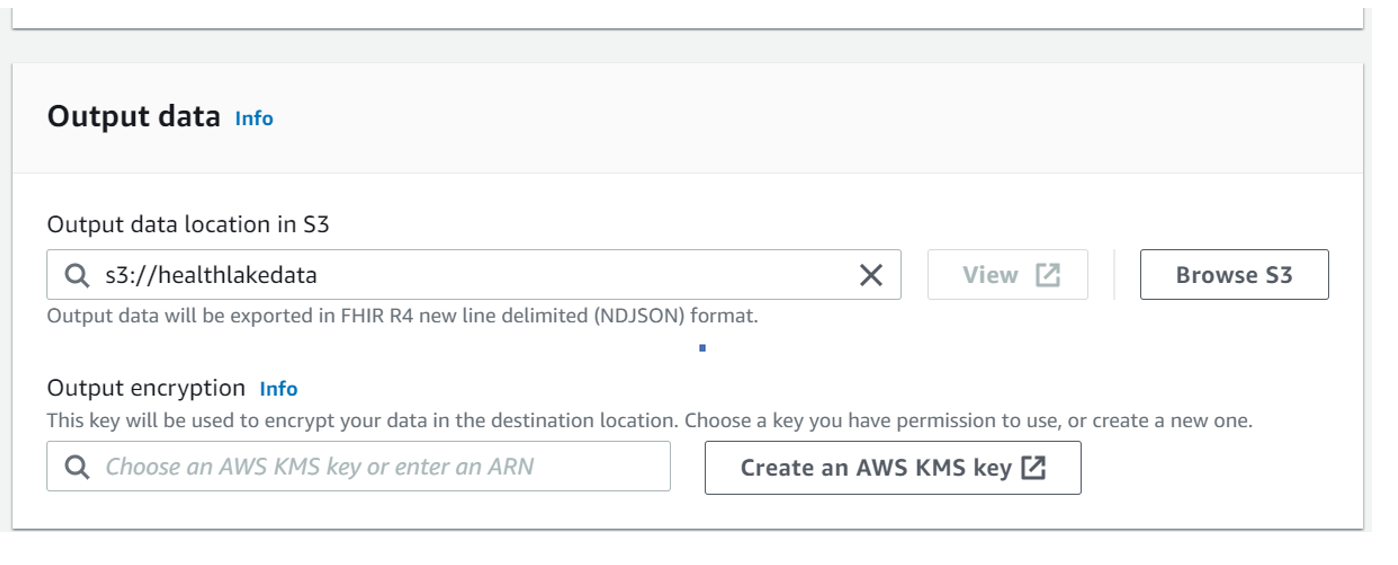
- Next enter the Access permission as shown below. I used the existing IAM role. You can create your new IAM role for this demo. Make sure the IAM Role is having permission on s3Full access, SagemakerFull access, Healthlake full access, Quicksight full access. The access can be controlled at the granular level. For the sake of simplicity, I have set up full access to the AWS services which will be used in this demo.
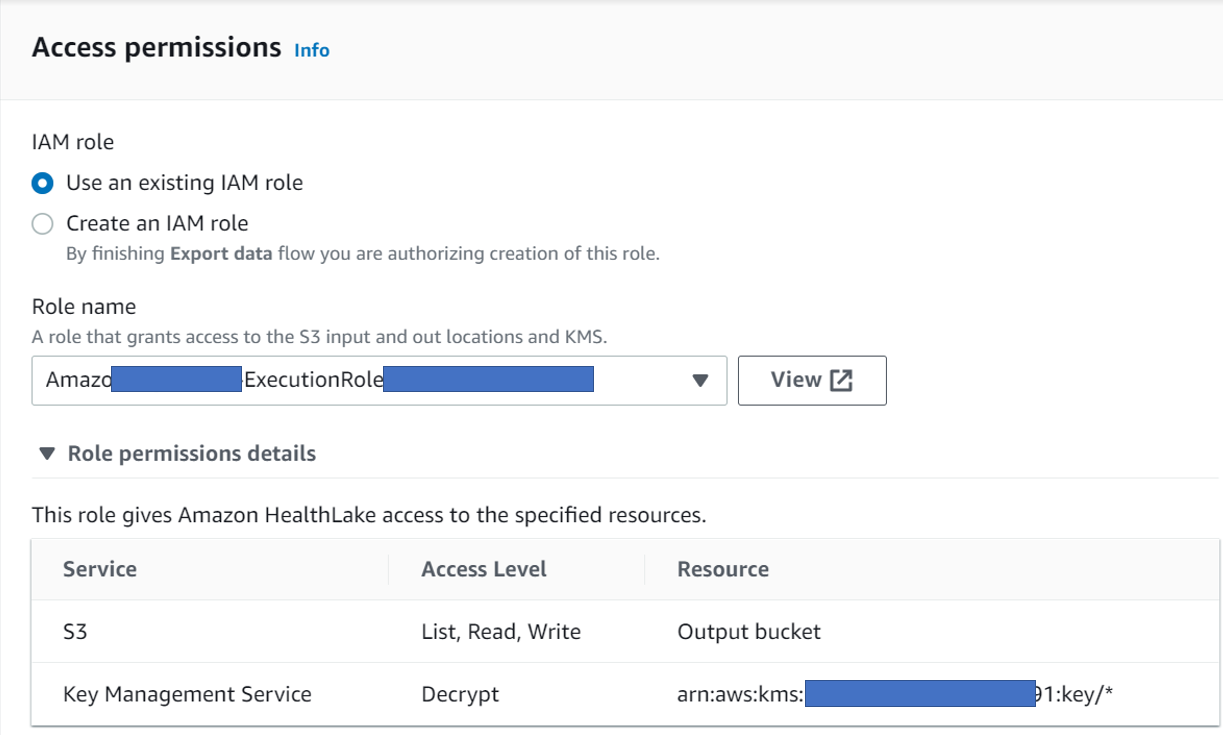
- The IAM role automatically grants Healthlake the Decrypt permission on the S3 bucket along with reading, list & write permission as shown below.
Once done, click the Export Data button to finish the action.
- On top of the screen, the message will be displayed that the job is successfully initiated & it will display the export job: .
- Please note the job id for future reference or to track the status.
- We can confirm that the export job succeeded by running the following AWS CLI command:
aws healthlake describe-fhir-export-job --datastore-id --job-id
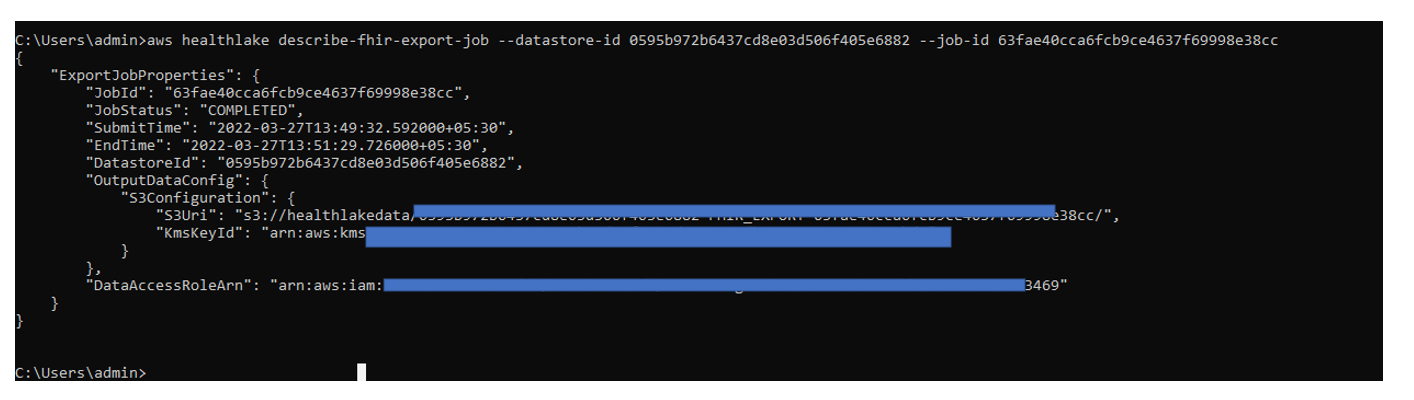
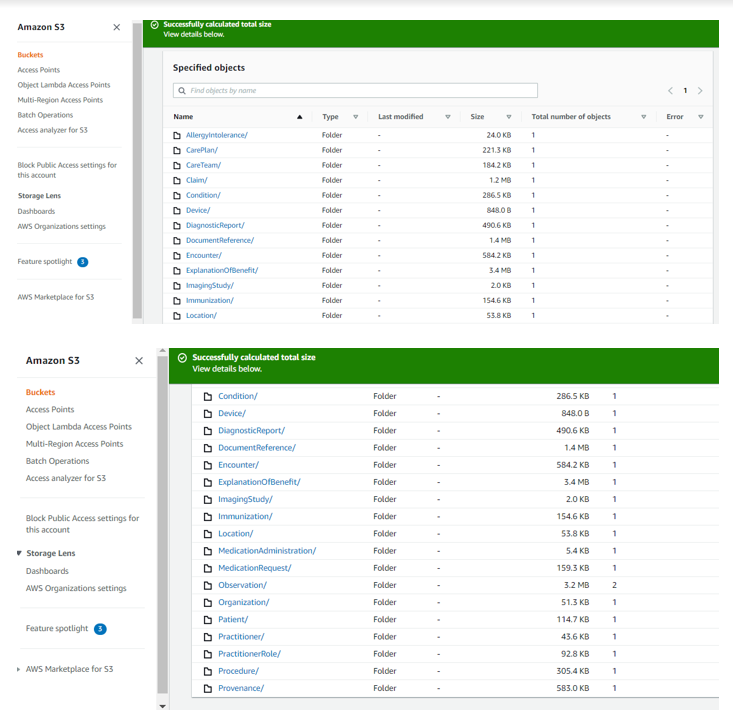
Once the export job is finished, the FHIR data will be stored in the specified S3 bucket.
Data Transformation
We will also set up the one Sagemaker instance using the Cloudformation Template for Step 1. Then Data transformation workflow will be set up using AWS Glue and Cloudformation Template for Step 2. Let’s follow the steps below :
Download two set up Cloudformation stacks and save them in your local drive from here :
Then create a stack in AWS using AWS CloudFormation Console.
Click on Create Stack and enter the details below to create the Cloudformation Template for Step 1:
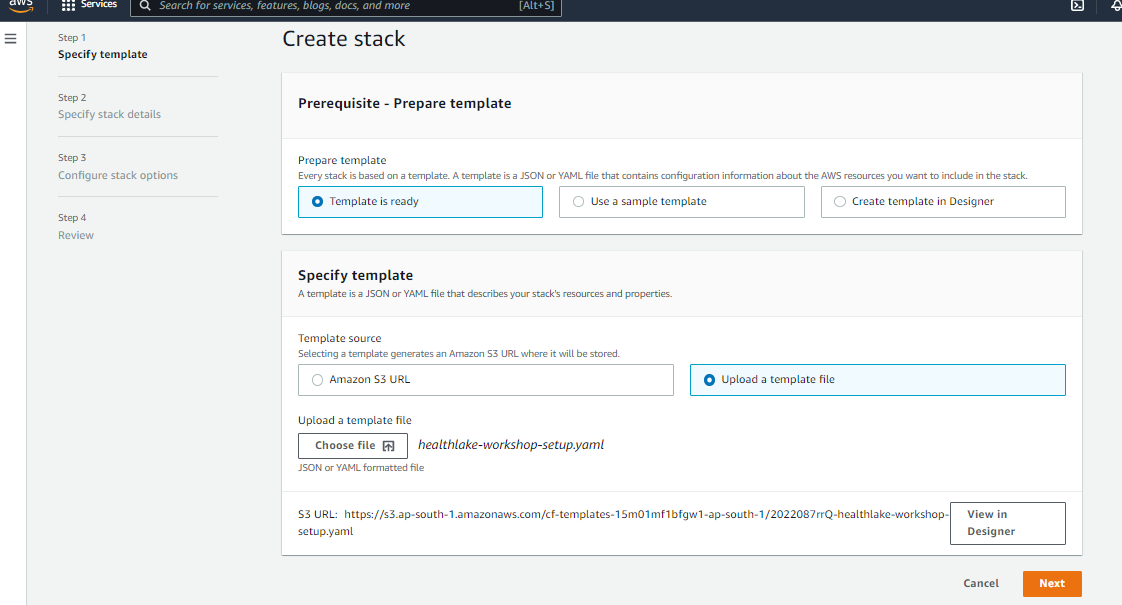
- Then click on the Next button and again the Next button and reach the Review Page.
- Acknowledge the creation of necessary resources by IAM role by clicking the check box. Click on Create Stack.
- Once the stack will be created check the Output ad Resources created by the stack.
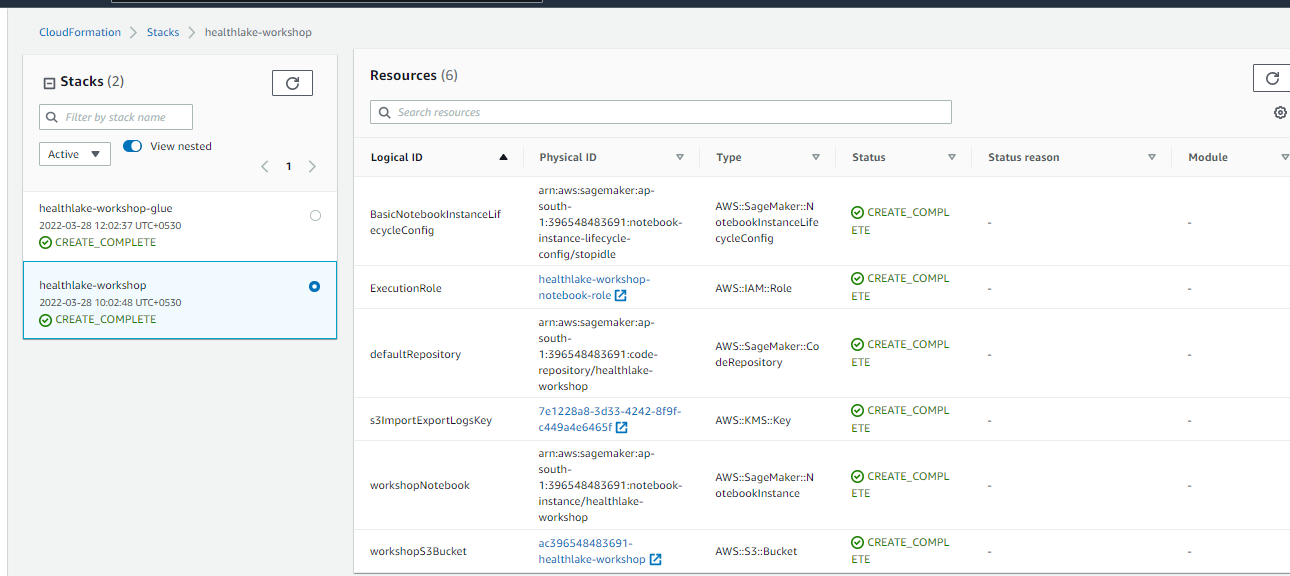
The above stack will create one Sagemaker Notebook instance named ” healthlake-workshop” as shown below.
To check this, open the Amazon SageMaker console, On the left-hand side panel clicks on Notebook instances :
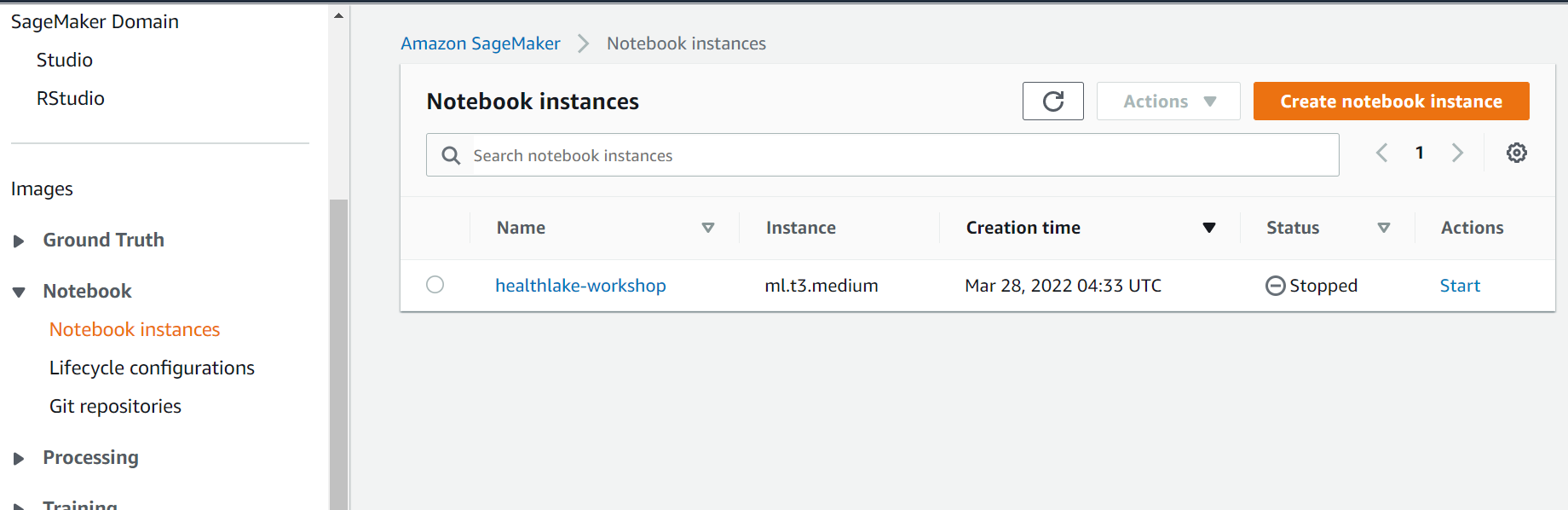
The Stack will start the notebook. Hence it will appear with the status “Inservice”. Make sure to stop the instance after the demo.
- Open healthlake-workshop with JupyterLab instance
- Select File -> New -> Terminal and open a new terminal
- “Cloudformation Template for Step 1” stack clone the required repository which will be used in this step. The repository will be found under the Jupyter lab instance.
We will now Upload the DocumentReference resource parser script to the S3 bucket. The parser script is available in the cloned repository as described above.
- This script will be uploaded in the same bucket where data was exported from the HealthLake datastore.
- We will run the below command in the JupyterLab terminal to upload the script:
The above steps are shown in the below “healthlake-workshop” Jupyter Lab Screen screen.
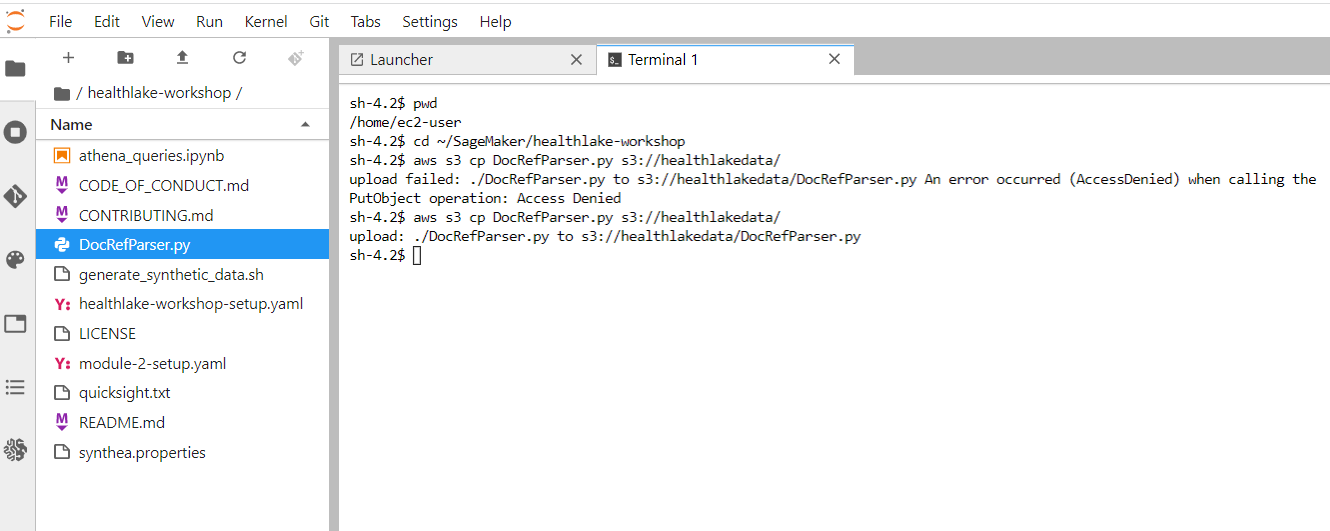
The command is :
cd ~/SageMaker/healthlake-workshop aws s3 cp DocRefParser.py s3:///
Set up GLUE Workflow
Now we will set up the second Cloudformation stack to set up the GLUE workflow.
- Go to CloudFormation Stack console, click on create a stack, enter the below details, and hit the next button.
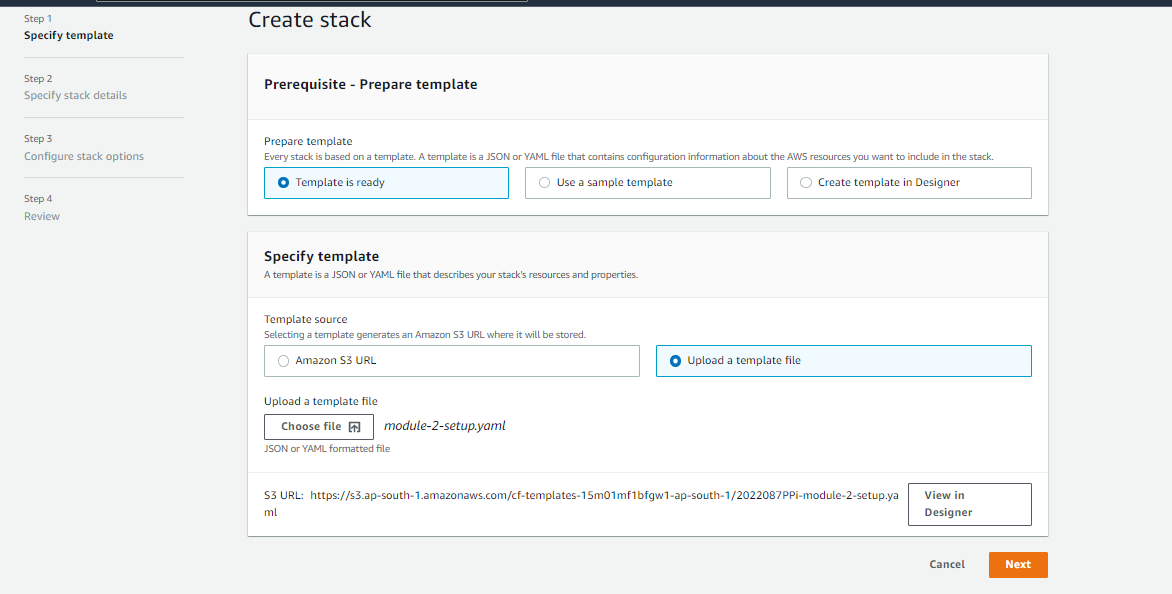
- Then enter the below details and hit the next button.
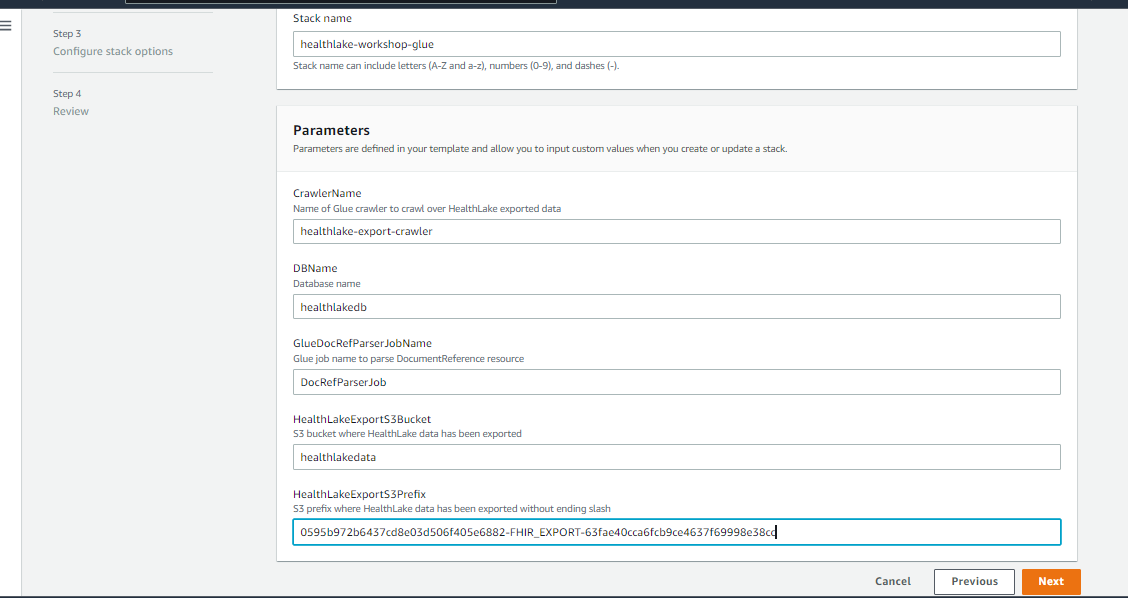
- Once we will reach the Review screen as shown below, acknowledge and hit the “Create Stack” button.
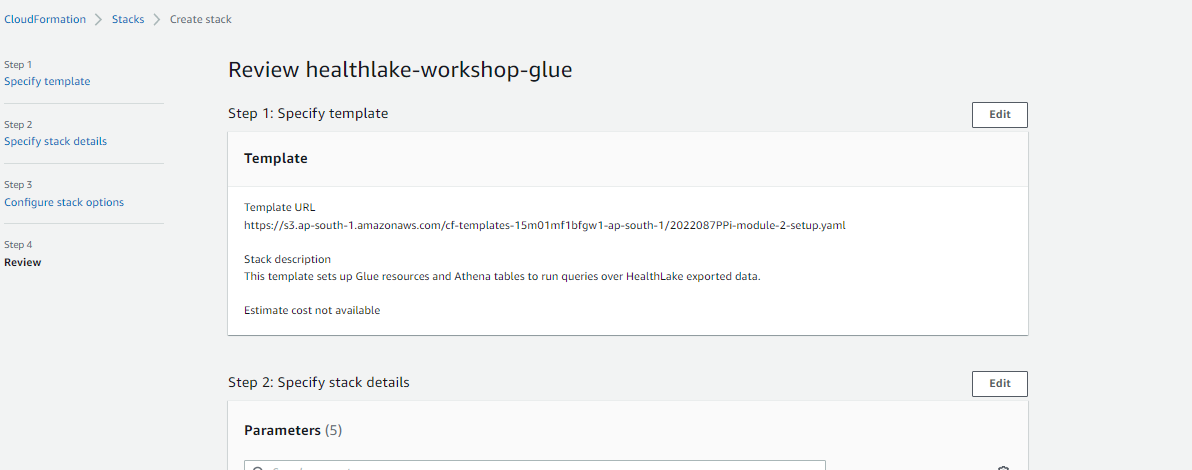
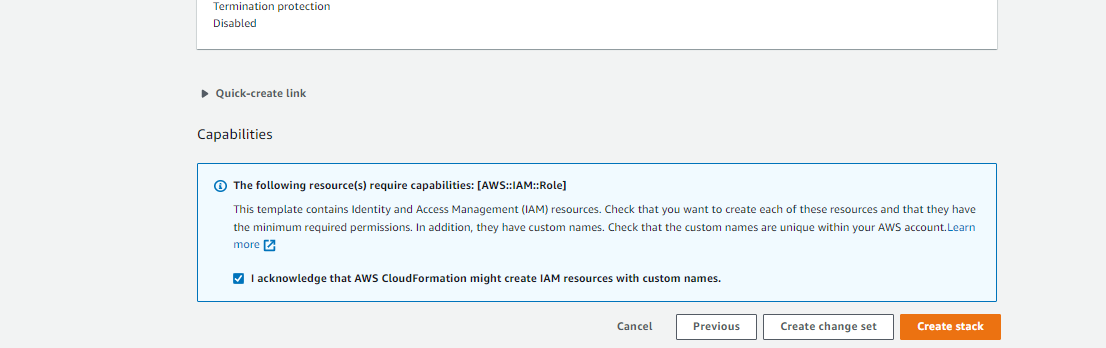
The stack will be created along with the resources as shown below:
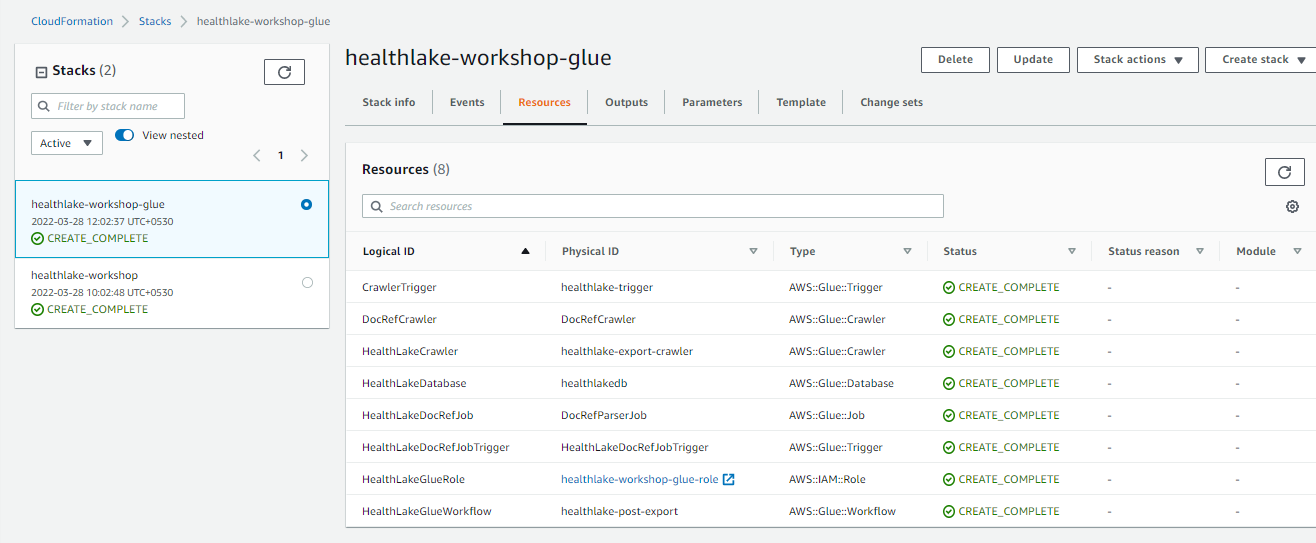
Run the Glue Workflow
Once the stack is created successfully and resources are verified let’s open the GLUE console and open the workflow on the left-hand side panel.
Select the workflow “healthlake-post-workflow” to see the graphical representation of the workflow.
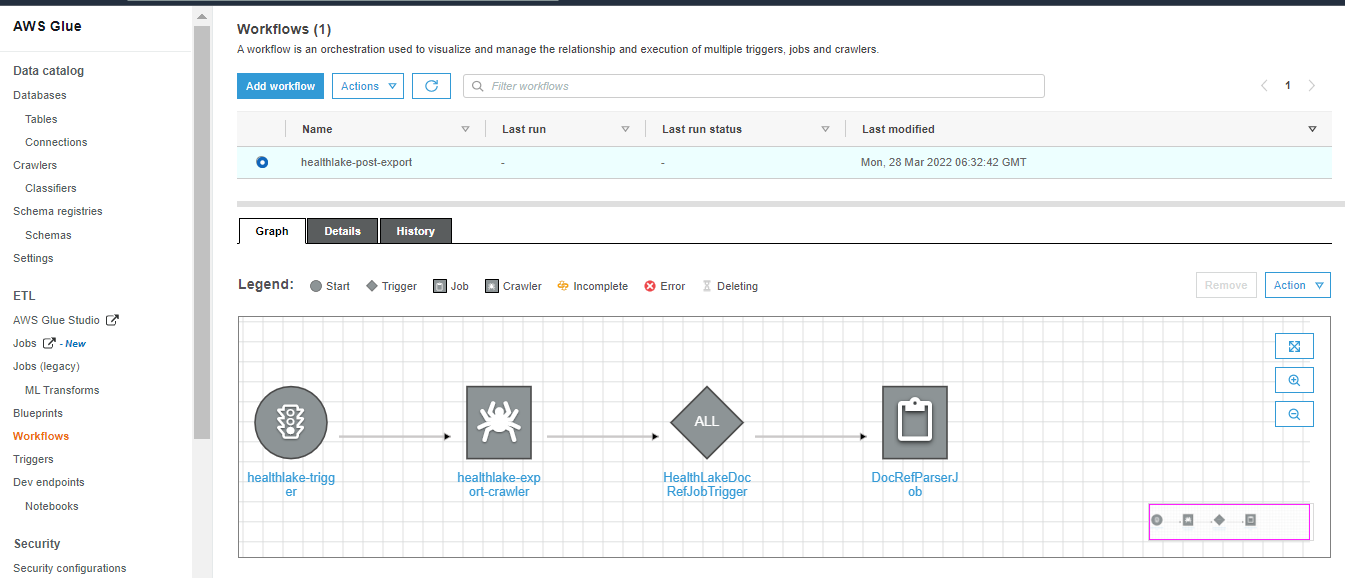
- Now select the Trigger from the left-hand side menu and select the Trigger “healthlake-trigger”.
- Select “Action” and “Start” the trigger which will run the above Glue workflow.
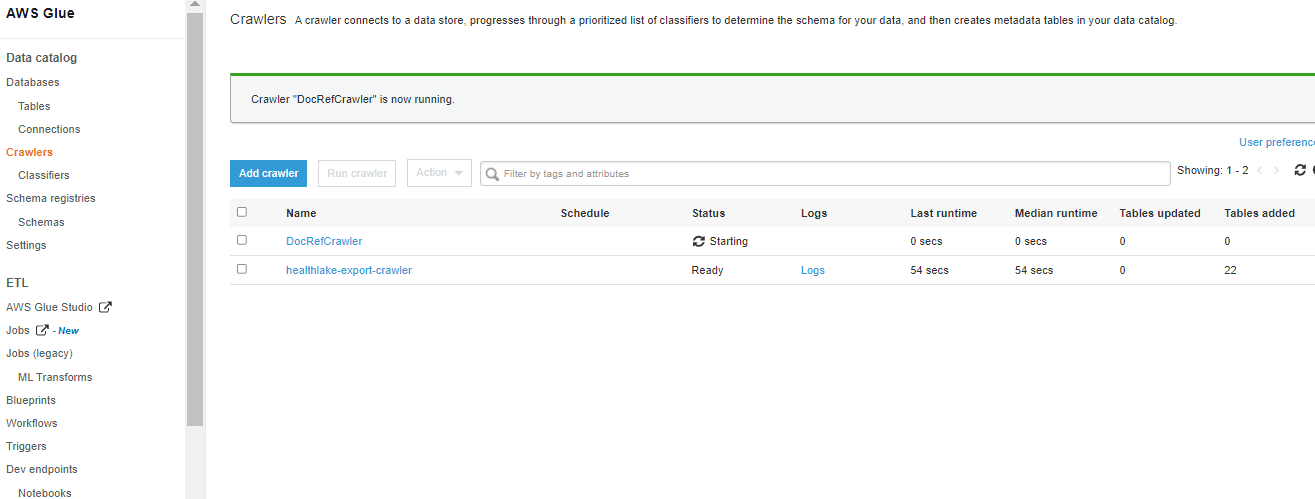
The workflow will create a “Crawler” as shown below “DocRefCrawler”.
.The Crawler crawl through the Healthlake export S3 bucket and extracts the schema and creates metadata along with data in the AWS Glue Data catalog.
Once the Glue job is completed successfully the below tales will be created in healthlakedb.
Let’s look at the export data extracted from Healthlake and understand the Glue workflow.
The Healthlake export process uses the NLP technique and extracts medical entities from the textual narratives and discharge summaries and stores them in an S3 bucket. Clinical notes are stored in the DocumentReferene folder in the S3 bucket which contains one ndjson file named DocumentReferene.ndjson. The FHIR extension fields in the JSON file associates each patient’s record with the extracted entity. Thus the data is indexed and tagged and stored in the HealthLake S3 bucket in a normalized format. The data is in NDJSON format, one folder is created per resource.
Glue workflow uses one python script to parse the “extension” tag of DocumentReference.ndjson and create the DocumentReference-0.csv file. Then crawler will crawl through DocumentReference-0.csv in a folder called ‘ParsedDocRef’ and create a table called “parseddocref” along with other tables (as shown below) in the “healthlakedb” database.
Thus “parseddocref” stores the unstructured data in a structured format and is used in the Quiksight dashboard to build insight into these unstructured data.
Set up Amazon Athena
Amazon Athena is a serverless, low latency interactive query service that works with S3 to analyze data using standard SQL.
We have to point Athena to S3, define the schema, and query through standard SQL. We can analyze the data by SQL query and can extract the data from multiple tables with join and proper where clause.
Athena is also integrated with GLUE Data Catalogue, crawling through various data sources and defining schemas, creating metadata for the modified dataset.
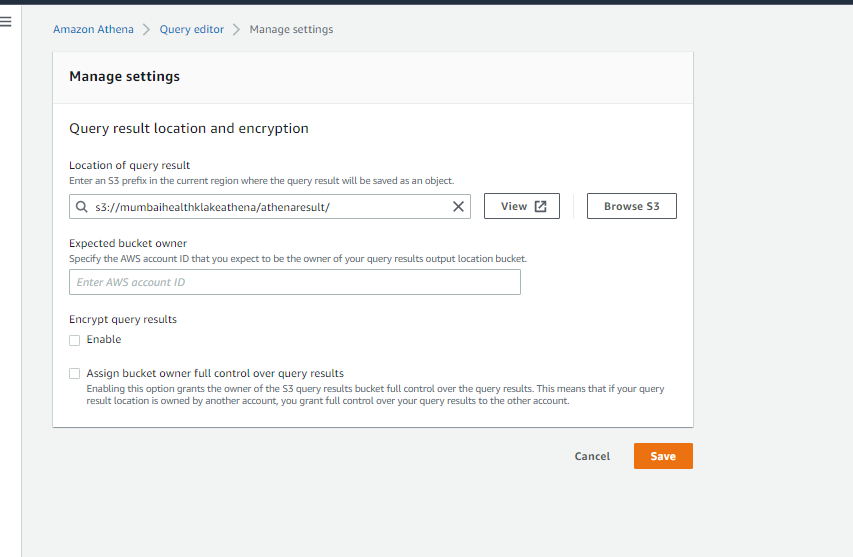
Navigate to Athena Console and click on the ‘Settings’ button on the top right.
Enter “s3:///athena/” as “Query result location” . Athena will store the query results in this bucket.
Now select query editor, select the healthlakedb as shown below.
Next, we will create two tables “condition_patient_encounter” by joining the Condition, Patient, and Encounter tables
create table healthlakedb.condition_patient_encounter as
SELECT DISTINCT p.name[1].family AS patient_name,
p.id as patient_id,
p.gender,
cast (p.birthdate AS date) AS birthdate,
p.maritalstatus.text as maritalstatus,
p.deceaseddatetime as deceaseddatetime,
enc.id as encounter_id,
enc.period.start AS start_enc,
enc.period."end" AS "end_enc",
enc.type[1].coding[1].display as encounter_type,
cond.clinicalstatus.coding[1].code as clinicalstatus,
cond.category[1].coding[1].display as category,
cond.code.coding[1].display as condition
FROM healthlakedb.patient p
FULL OUTER JOIN healthlakedb.encounter enc
ON ("split"("enc"."subject"."reference", '/')[2] = "p"."id")
FULL OUTER JOIN healthlakedb.condition cond
ON ("split"("cond"."encounter"."reference", '/')[2] = "enc"."id")
And “parseddocref_patient_encounter” by joining the parseddocref, Patient, and Encounter tables.
create table parseddocref_patient_encounter as
SELECT distinct p.name[1].family as patient_name, p.id as patient_id,
enc.period.start as start_enc, enc.period.start as end_enc,
enc.type[1].text as encounter_type, pdr.code_description as parsed_condition,
pdr.code_score, pdr.entity_score
FROM healthlakedb.patient p
FULL OUTER JOIN healthlakedb.encounter enc
ON ("split"("enc"."subject"."reference", '/')[2] = "p"."id")
FULL OUTER JOIN healthlakedb.parseddocref pdr
ON ("split"("pdr"."encounter_id", '/')[2] = "enc"."id")
Once done verify by viewing these two tables as shown below
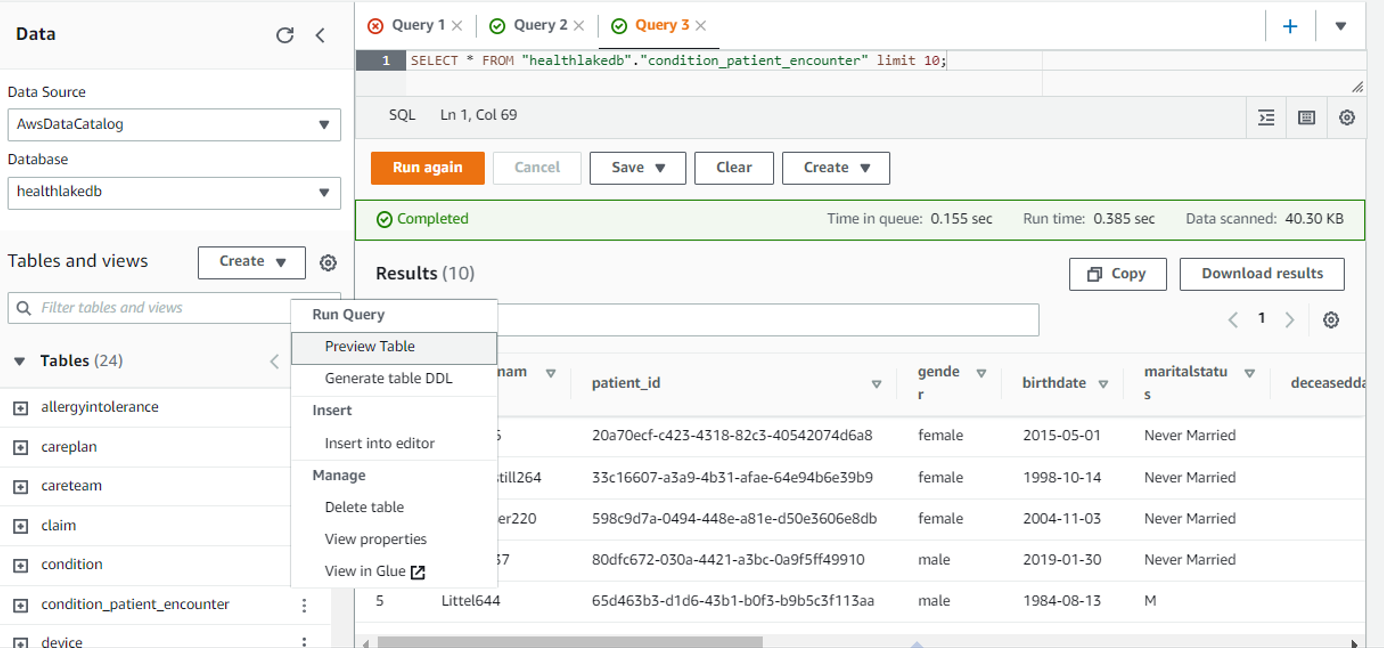
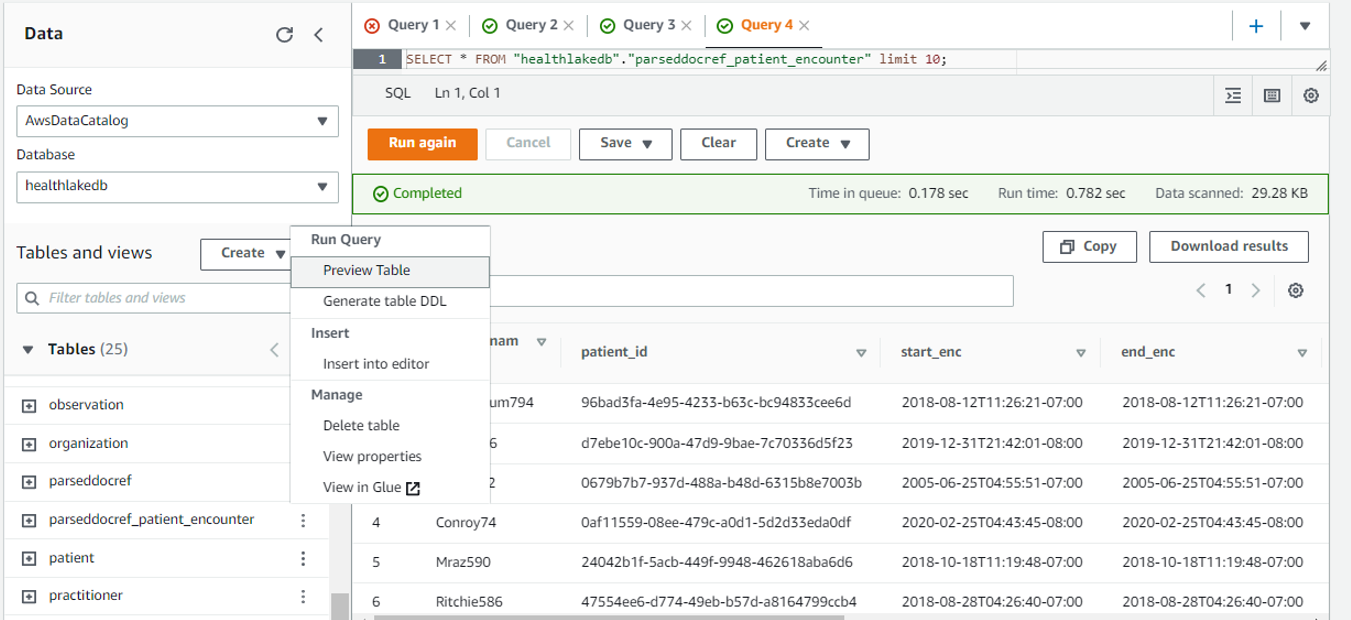
Health Population Dashboard with QuickSight
Setup S3 permission for Quicksight
- Login to Quiksight account on AWS Console.
- Create a new account id if log in for the first time.
- We will link Athena as a Quiksight data source. When called from Quicksight, Athena will query data files in the S3 bucket.
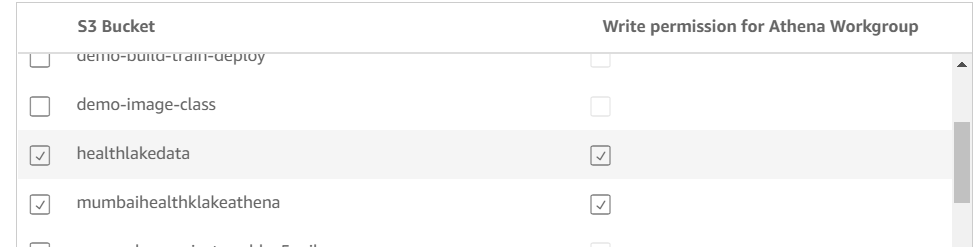
- To perform this activity, QuickSight must have access to the S3 bucket where Athena is set up in the above steps. Also, Quiksight and S3 must be in the same region.
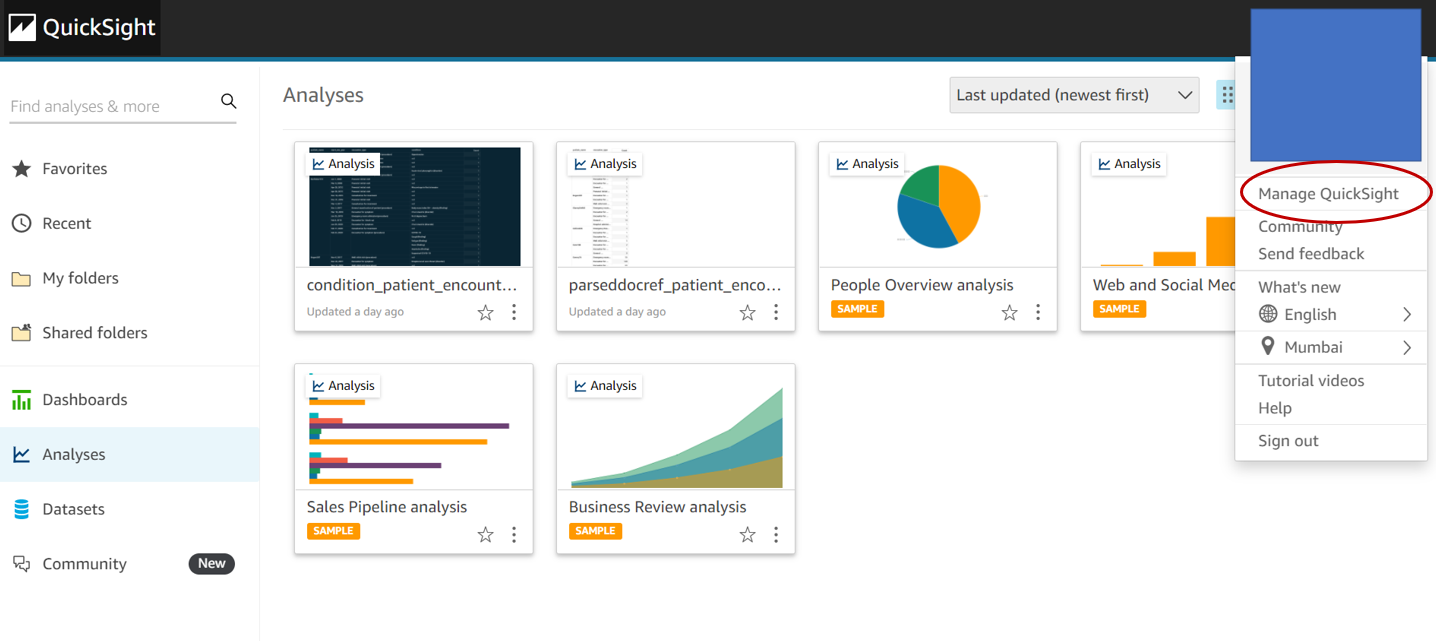
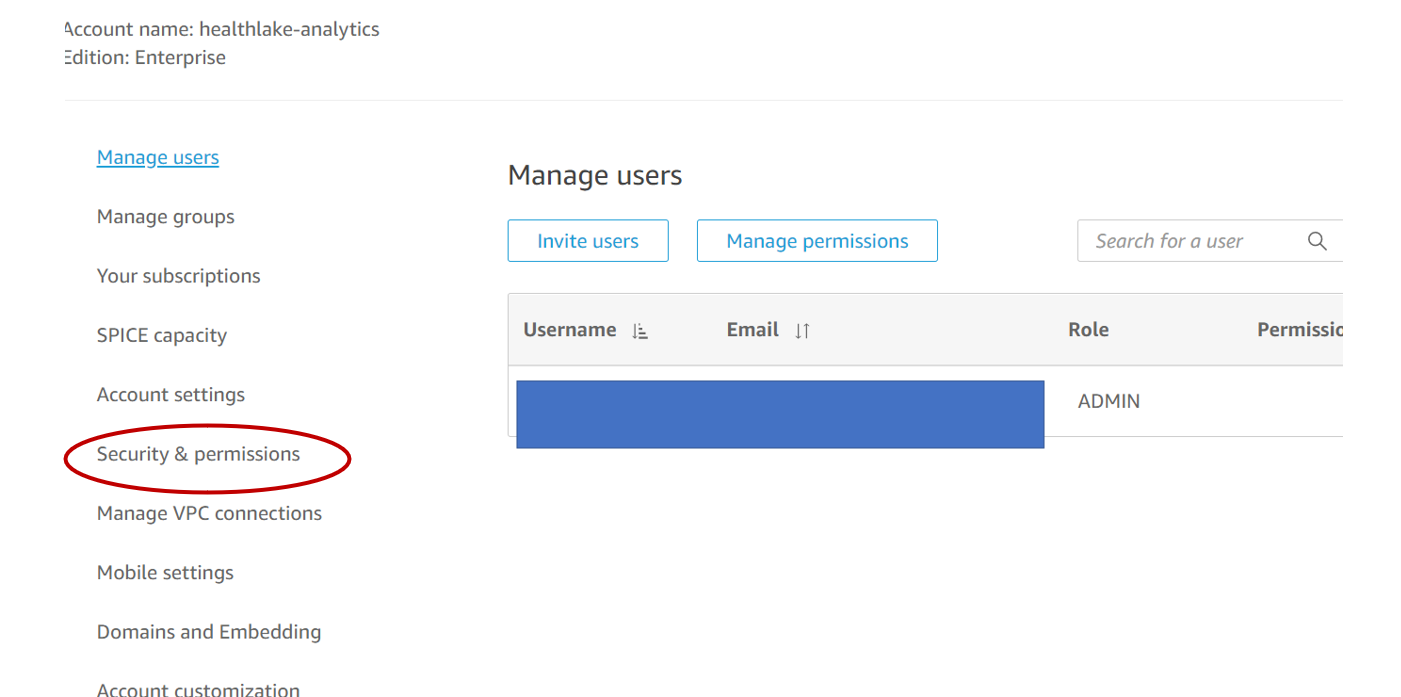
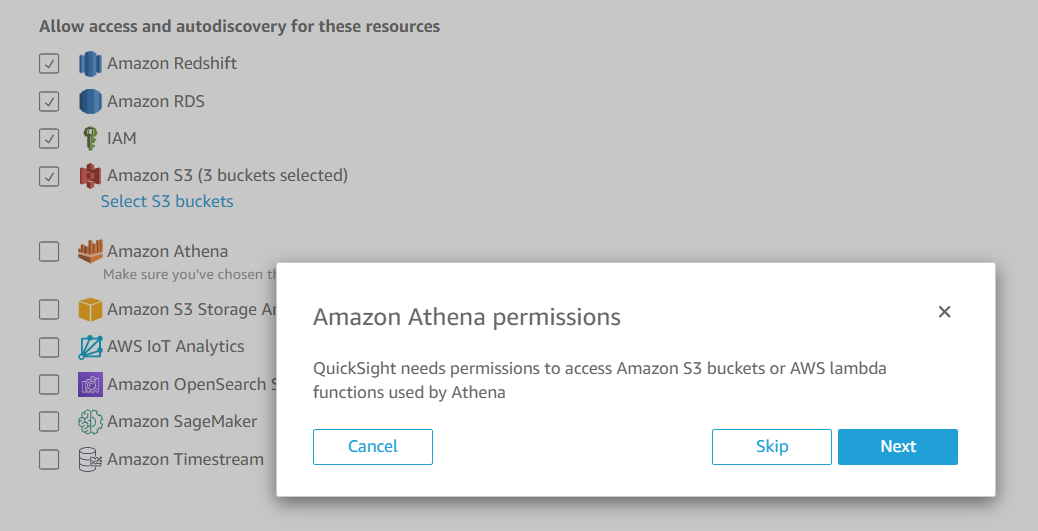
- Click on Manage QuickSight and go to Security and Permissions on the left menu.
- Locate the “QuickSight access to AWS Services” section, and click on the “Add or Remove” button.
- This will open up a page to select services for access.
Refer to the screenshots below:

Create QuickSight Dataset
Once Quicksight can access Athena and S3, let’s create the dataset for the dashboard.
Goto Quicksight console and click on Dataset as shown below and follow the subsequent screens.
Click on “New Dataset” and select Athena as a data source. Then follow the next screens and add the required tables in the datasets.
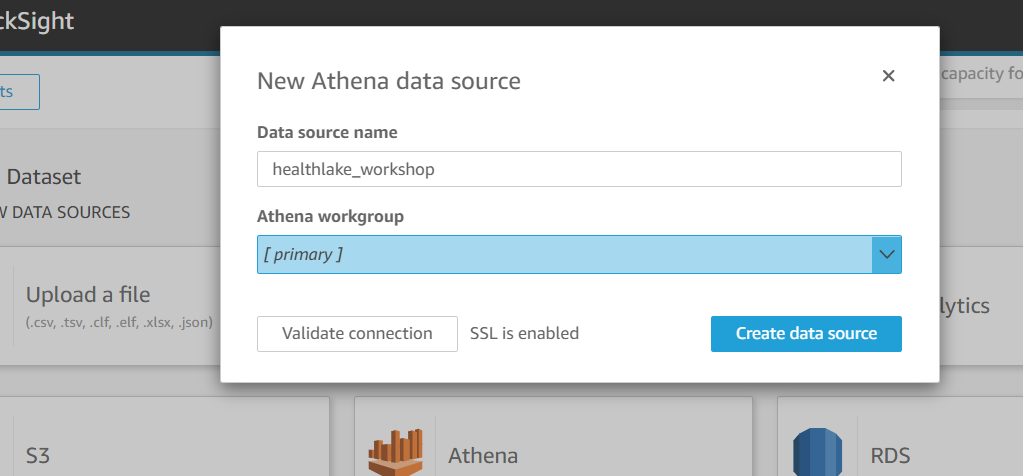
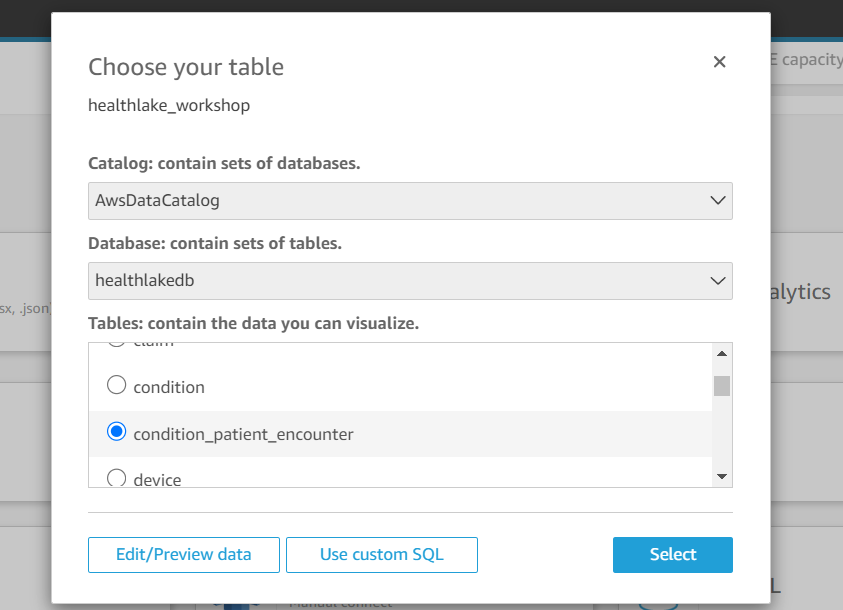
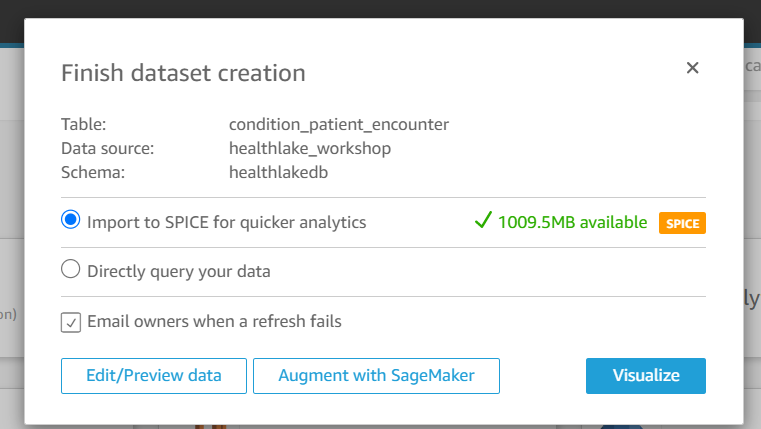
Then click on Visualize. On the visualized screen we will add different widgets with different field metrics to analyze the data.
Once the calculated field is created to extract the year from the start_enc field as shown below
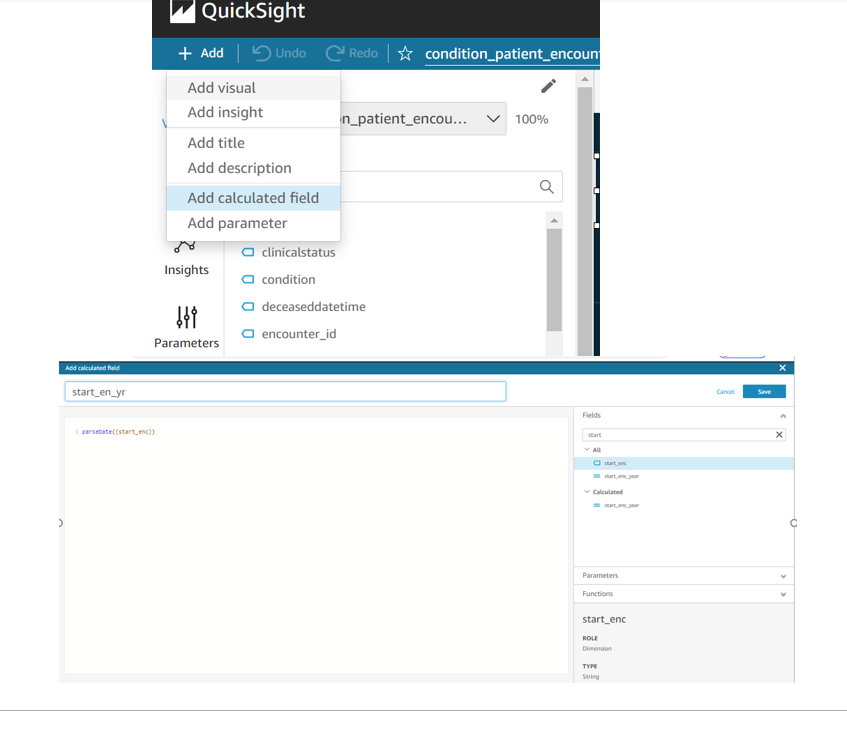
Create QuickSight Dashboard
Below screenshots are a few examples to show how to build a dashboard using Qucksight.
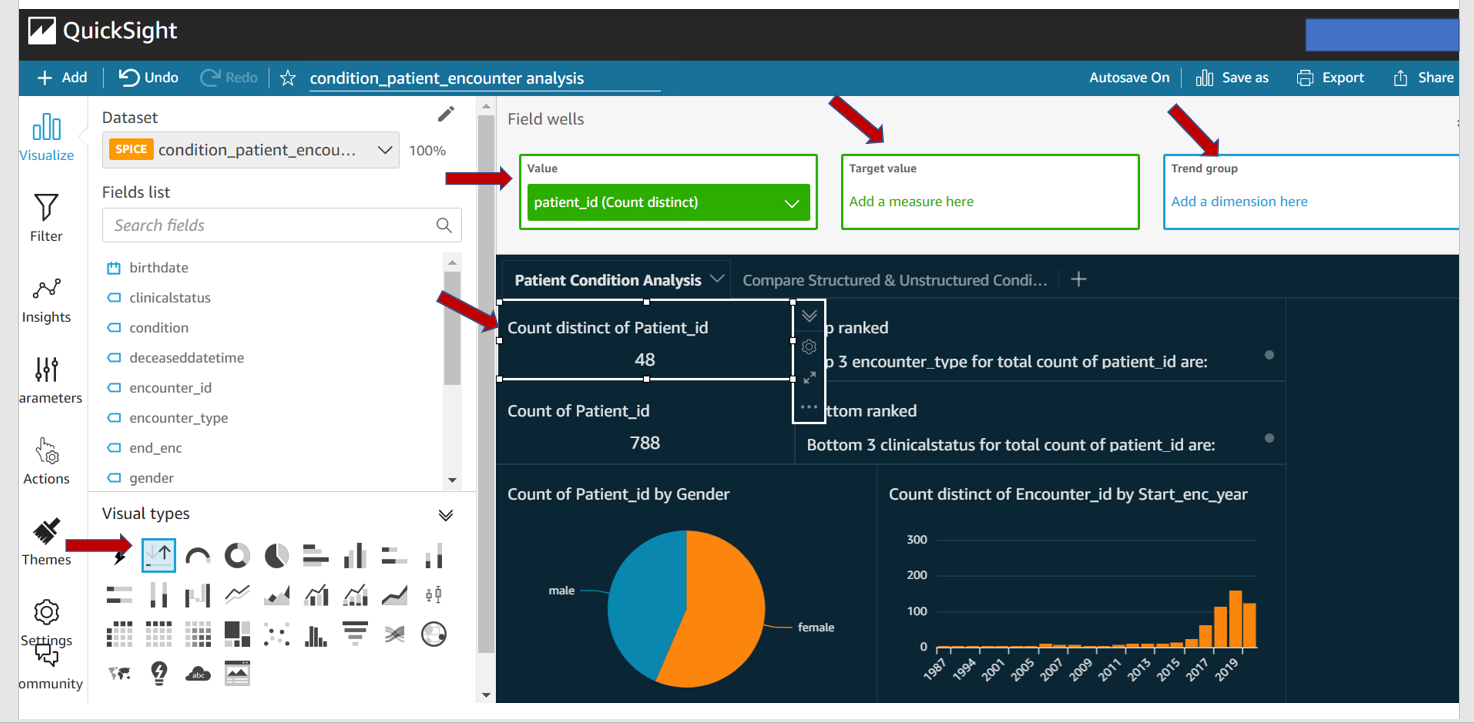
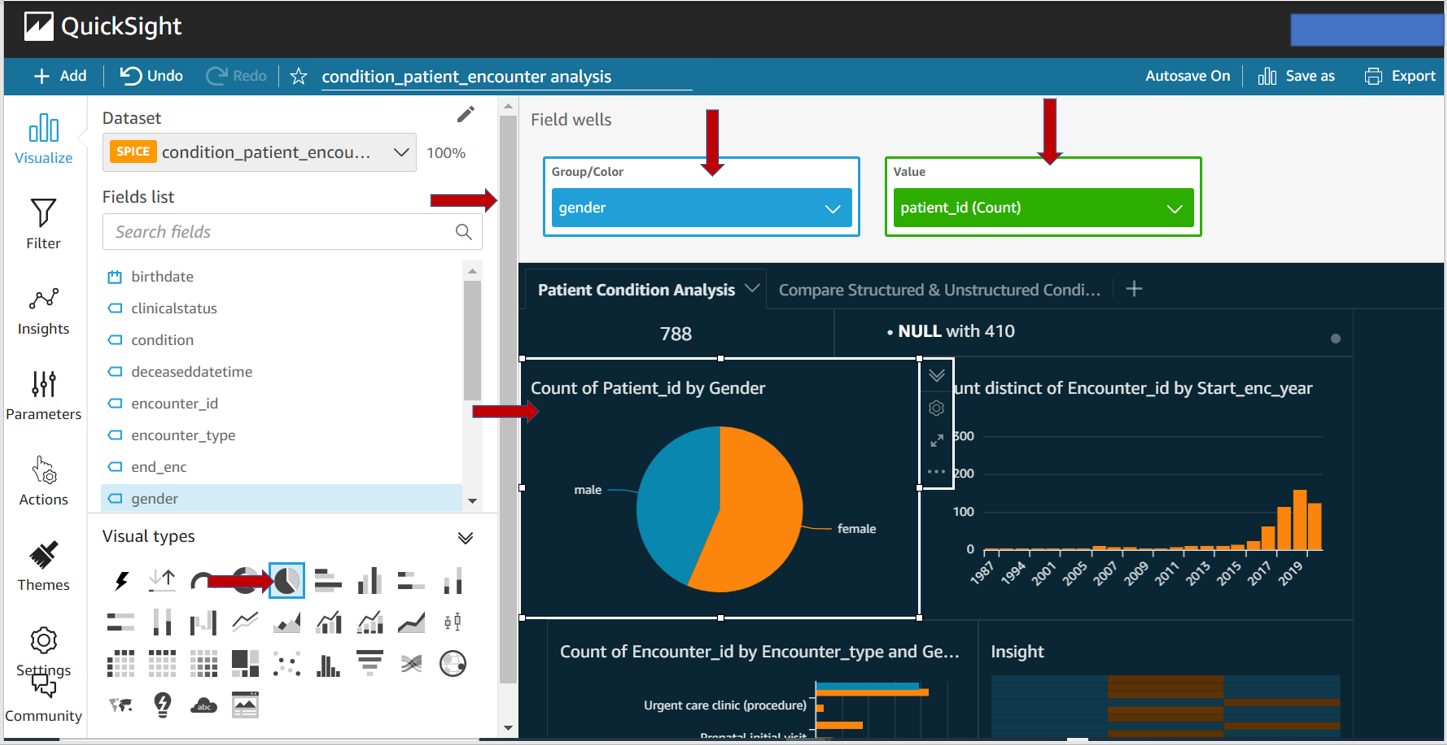
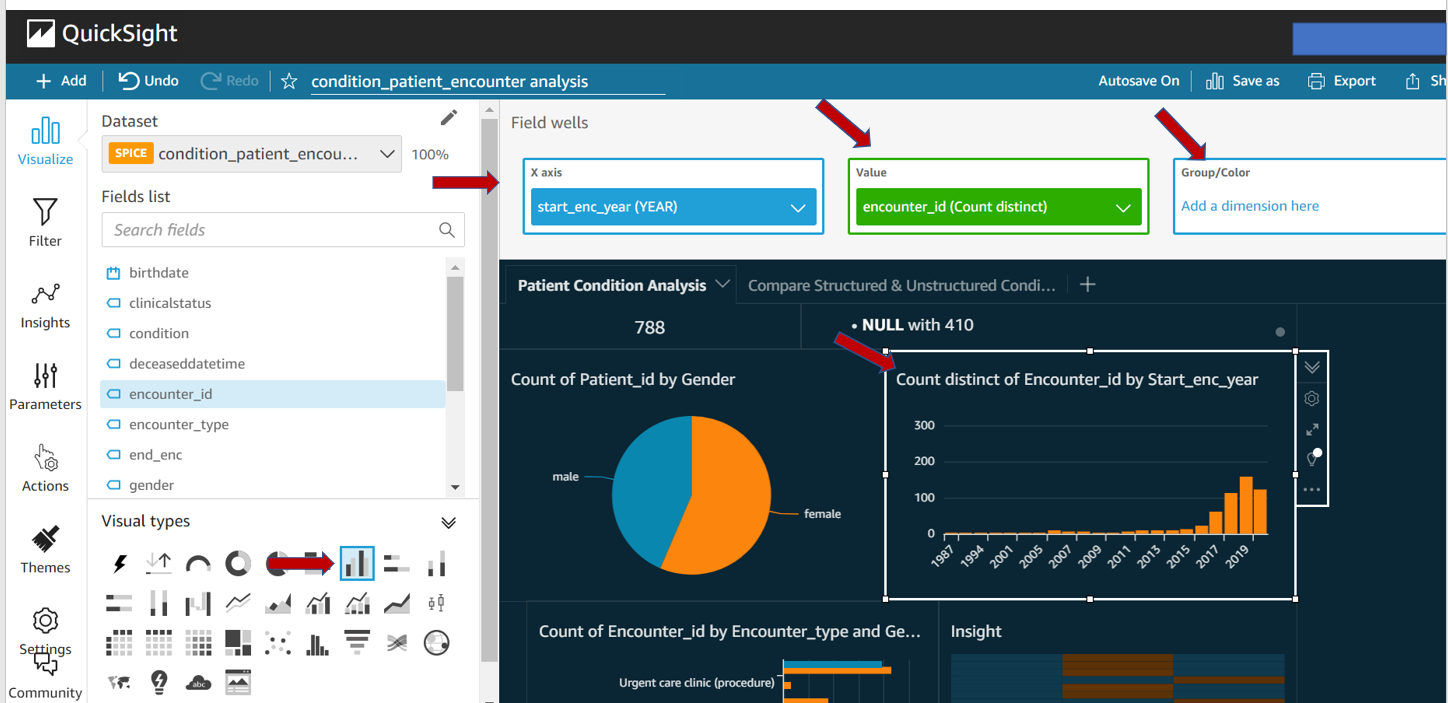
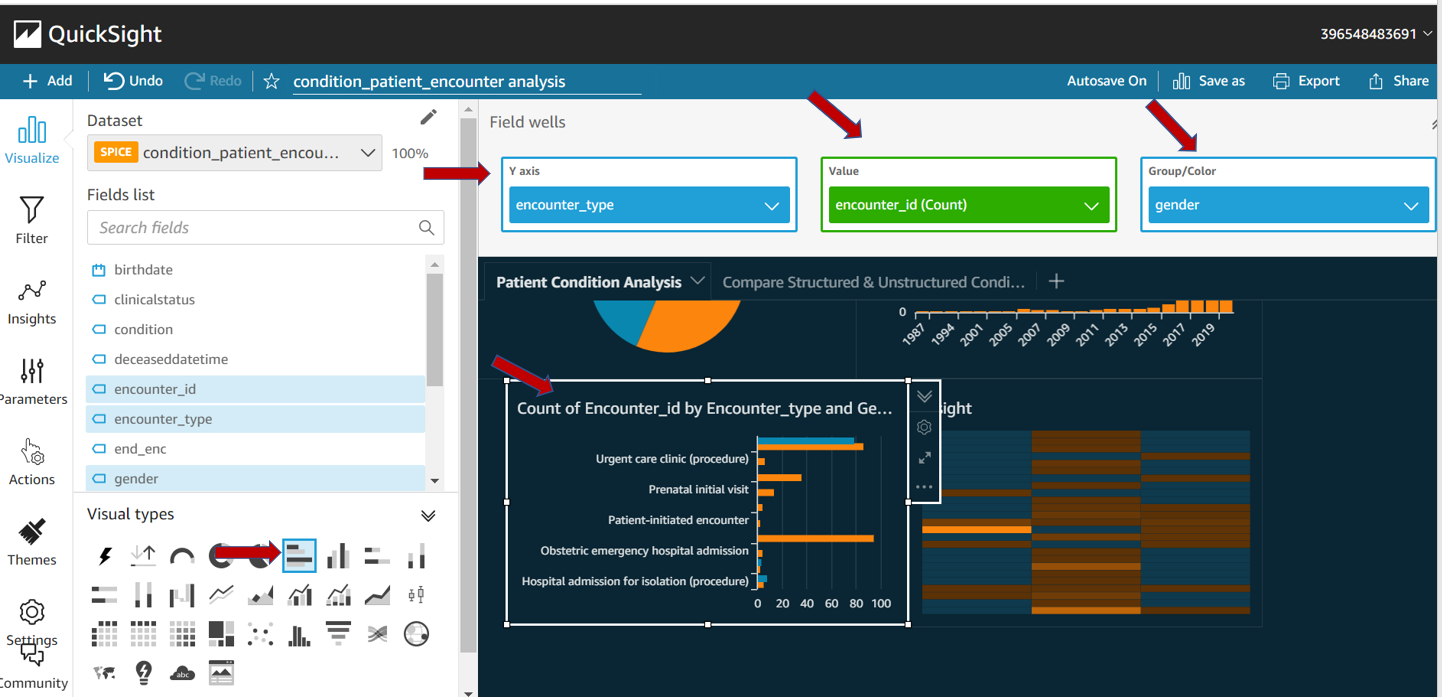
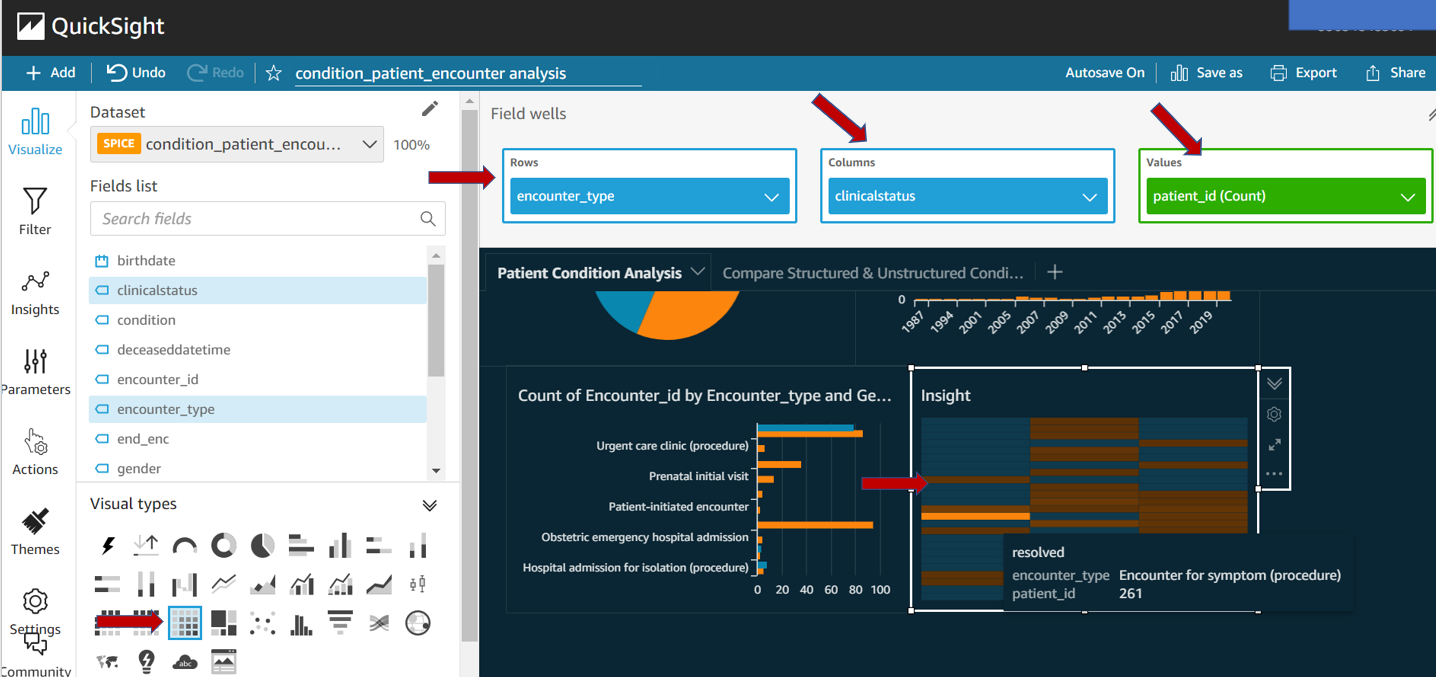
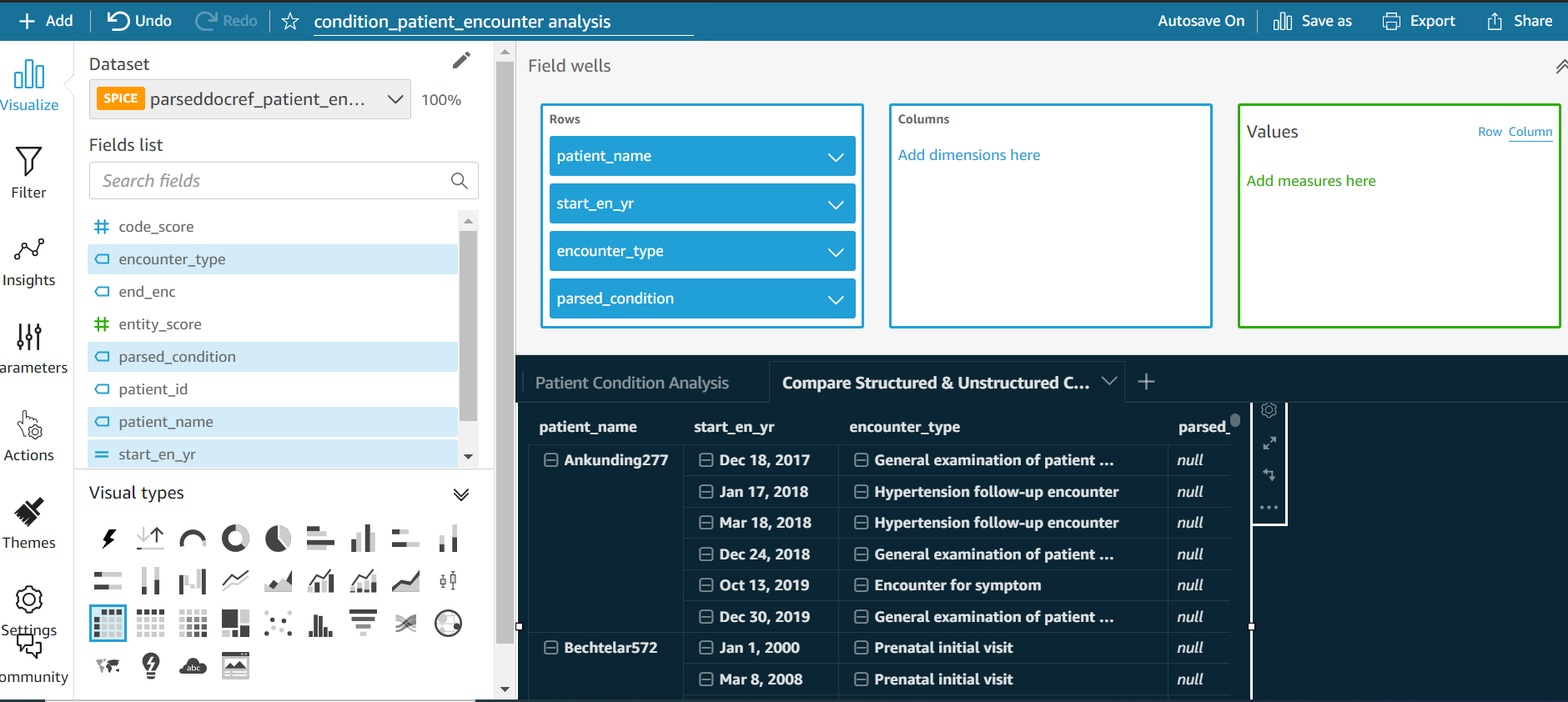
The below dashboard is created from the parsed dataset to extract information from unstructured data. Then the patient condition is extracted from structured data and the parsed dataset is compared.
Cleanup
- Delete the Healthlake datastore
- Delete Cloudformation stacks
- Delete S3 buckets.
- A quick sight account is created for this demo. You can unsubscribe Quicksight account by using this link
- Make sure the Sagemaker Notebook instance is stopped after the use to stop the cost.
- Check the billing details the next day to check any unwanted costs in the billing.
- For any billing, the issue raises a support ticket with billing details and screenshots.
Conclusion
Healthcare AI is a vast, complex domain. The opportunities are immense and we can improve human lives with the help of strong domain expertise, technology, and innovations. There are many use cases in Healthcare AI eg. clinical data science, medical AI, precision health, population & individual health care, critical care systems, diagnostics, genome analysis, optimization of hospital operations, provider claim systems, etc, etc. The challenges are due to non-standard low quality data, data privacy & protection laws, and complex infrastructure. Cloud-based solutions like Healthlake, Quicksight, Sagemaker, and other AI/ML services are helping to extract medical entities from unstructured data quickly, building various predictive decision support systems and visualizing the insight for clinicians, doctors, and medical professionals.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Sarbani Maiti,
Vice President, Data and AI Practice at Veersa Technology.
She is having 20 + yrs of experience in various technologies including cloud, AI/Ml, and data analytics. In her current role, she focuses on developing data-driven solutions for healthcare, finance, and other industries.
As an AWS Community Builder, speaker, and tech blog writer, Sarbani is dedicated to sharing her knowledge and experience with others.





