This article was published as a part of the Data Science Blogathon.
Introduction
Natural Language Inferencing is a subset of Natural language processing. Inferencing means the machine is trying to understand if an assumption is a contradiction of the premise or it is an entailment or is neutral.
Let me give you an example:
Consider, the premise to be: “Boys played well” and the assumption is “Indian women’s team wins laurels internationally“. Here the assumption is a contradiction of the premise. Another example would be the premise is “Cyclone Asani can cause havoc in the bay of Bengal” and the assumption is “Evacuation is started in India by the government“. Here, the assumption would be an entailment of the premise, that is it follows the premise. I hope you find the examples useful. We would be working on a multilingual Kaggle dataset Contradictory, my dear Watson! We would begin by understanding the data.
Data Exploration
We check the balance of data, to begin with.
sns.countplot(data=train,x="label")
plt.show()
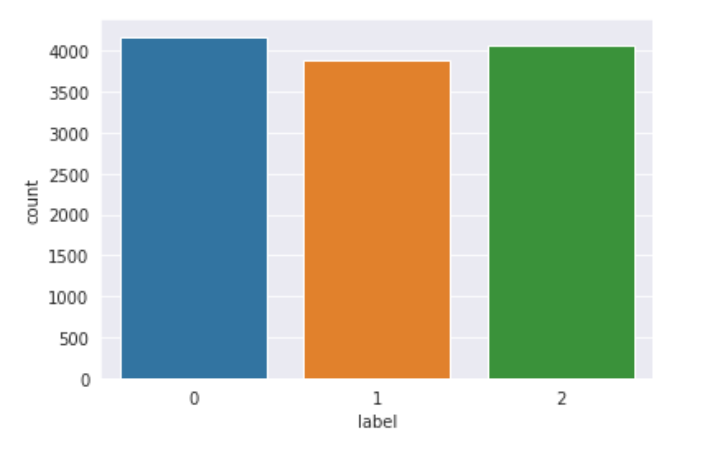
The data seems to be balanced.
Next, we check the samples for every language
chart = sns.countplot(data=train,x="language") chart.set_xticklabels(chart.get_xticklabels(), rotation=45) plt.show()
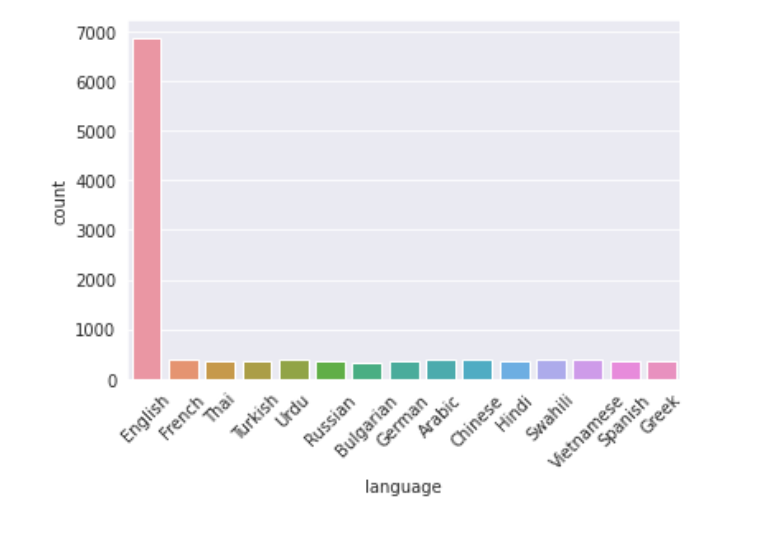
As is clear, out of 15 languages most of our data is from the English language almost 6870 samples whereas the other languages have around 400 samples.
More than 50% of the data is in English.
We would need to account for the same while model training.
We draw some word clouds in different languages.
plot_wordcloud(train,”German”)

plot_wordcloud(train,"Russian")

plot_wordcloud(train,"English")
plot_wordcloud(train,"Vietnamese")

Baseline Model
As a baseline, I took the following steps:
1) To translate all the data to one language (English)
2) Use TF IDF for vectorization of text data
3) Use the Random Forest model with Grid Search CV for hyperparameter optimization.
For translation to English, you can use google translate API
!pip install googletrans==3.1.0a0
def Translate(x):
translator = Translator()
translator.raise_Exception = True
return str(translator.translate(x,dest="en").text)
Using the above code we were able to complete the first step of our outline.
We then used TF IDF, code for the same.
from sklearn.feature_extraction.text import TfidfVectorizer vect = TfidfVectorizer(ngram_range=(1,3),min_df=15,max_features=500,stop_words='english')
train_premise = vect.fit_transform(trans_train["premise"]) test_premise = vect.transform(trans_test["premise"]) train_hypothesis = vect.fit_transform(trans_train["hypothesis"]) test_hypothesis = vect.transform(trans_test["hypothesis"]) train_lang_abv = vect.fit_transform(trans_train["lang_abv"]) test_lang_abv = vect.transform(trans_test["lang_abv"])
from scipy.sparse import hstack X = hstack([train_premise,train_hypothesis,train_lang_abv]) X_test = hstack([test_premise,test_hypothesis,test_lang_abv])
Code for random forest and Grid Search CV
# Define model
model=XGBClassifier(random_state=0,use_label_encoder=False)
# Parameters grid
param_grid = {'n_estimators': [50, 150, 200],
'max_depth': [4, 6, 8, 10, 12],
'learning_rate': [0.025, 0.05, 0.075, 0.1, 0.125, 0.15],
'eval_metric':['logloss']}
# Cross validation
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
# Grid Search
grid_model = GridSearchCV(model,param_grid,cv=kf)
# Train classifier with optimal parameters
grid_model.fit(X,y)
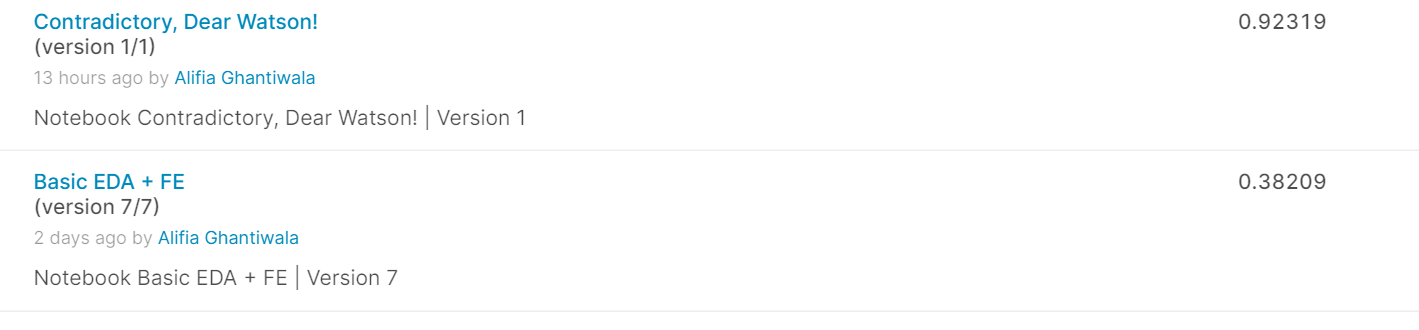
With this model, I was able to receive an accuracy of 38.209% which had a lot of room to improve.
After researching about best ways to work on NLI problems I came across the concept of transformers and transfer learning.
Using XML Roberta I was able to increase the accuracy of my model to 92%.
Using XML-Roberta Model
Transformers:
Transformers are deep neural network models which use attention mechanisms. Recurrent neural networks were not good with long-term dependencies. As natural language processing has long-term dependencies in them, transformers were introduced to solve these problems.
Transformers can be broadly classified into two components Encoder and Decoder.
The Encoder is a bidirectional LSTM, it is bidirectional to provide better context for the words in the sentence.
The Decoder is a unidirectional LSTM simply because words are to be generated one at a time sequentially.
Attention helps to focus on words that are in the vicinity of the target word by providing corresponding weights.
If you are new to the topic of transformers I would recommend the following readings.
1) https://jalammar.github.io/illustrated-transformer/
Transfer Learning:
Transfer learning was already a breakthrough concept in Computer vision, it was first used in the natural language processing domain with transformers themselves.
We do not have high computational power or large amounts of data at our disposal most of the time. Using a model which is already trained on Gigabytes of data, and fine-tuning it to our task, can save us a lot of time and help us with amazing results.
Roberta is an improvement over the BERT model, which is why we would have a brief discussion on the BERT model.
BERT:
BERT is short for Bidirectional Encoder Representations from Transformers.
It uses a stack of encoders and decoders in addition to using attention in working with NLP tasks like text classification and natural language inferencing.
It was trained on the whole of Wikipedia available in English. It is pre-trained on two tasks
1) Masked Language Model
15% of tokens are masked when provided as input to the BERT model. The model has to then predict the most likely token for the masked tokens, which in turn, helps it to learn the context of the words.
2) Next Sentence Prediction
It involves predicting if the next sentence would be good if it follows the given first sentence. This again helps BERT to generate contextual embeddings for words.
How is it different from other pre-trained embeddings like Glove or Word2Vec?
Word2Vec or Glove would give the same embedding for a word, irrespective of its context, which we know is it not the case with BERT.
Roberta:
Roberta stands for Robustly Optimised BERT Pretraining Approach.
It differs from BERT in the amount of data it has been pre-trained on. BERT was trained on 16GB of data, and Roberta is trained on 160GB of data. It uses dynamic masking instead of static masking used by BERT.
Dynamic masking is using different masks for your data. It performs slightly better than static masking.
We use a fine-tuned model of Roberta for NLI which is xlm-roberta-large-xnli for solving our problem at hand
Importing the model and tokenizer:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
nli_model = AutoModelForSequenceClassification.from_pretrained('joeddav/xlm-roberta-large-xnli')
tokenizer = AutoTokenizer.from_pretrained('joeddav/xlm-roberta-large-xnli')
Use the pre-trained model for predictions, without any fine-tuning
def get_tokens_xlmr_model(data):
batch_tokens = []
for i in range(len(data)):
tokens = tokenizer.encode(data["premise"][i], data["hypothesis"][i], return_tensors="pt", truncation_strategy="only_first")
batch_tokens.append(tokens)
return batch_tokens
def get_predicts_xlmr_model(tokens):
batch_predicts = []
for i in tokens:
predict = nli_model(i)[0][0]
predict = int(predict.argmax())
batch_predicts.append(predict)
return batch_predicts
sample_train_data_tokens = get_tokens_xlmr_model(train) sample_train_data_predictions = get_predicts_xlmr_model(sample_train_data_tokens)
The Roberta model helped us achieve an accuracy of 92.3% from the original 38% of our baseline model.
Conclusion
- The article provides an introduction to NLI with python code for both baseline models and using transfer learning by using a pre-trained model.
- Further improvement is possible on the score by understanding the errors made by the pre-trained model and fine-tuning it further.
Hope you liked my article on Natural Language Inferencing? Please share your views in the comments below.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.





