This article was published as a part of the Data Science Blogathon.
Introduction
MLOps, as a new area, is quickly gaining traction among Data Scientists, Machine Learning Engineers, and AI enthusiasts. MLOps are required for anything to reach production. Here’s everything you need to know about MLOps and why it’s so important for getting the most out of machine learning.
When organizations needed to adopt Machine Learning solutions in the early 2000s, they used vendor-licensed software like SAS, SPSS, and FICO. As open-source software and data became more freely available, more software practitioners used Python or R libraries to train ML models.

The deployment of the model in a scalable manner was solved utilizing Docker containers and Kubernetes as containerization technology matured. These technologies have evolved into machine learning deployment platforms covering the complete model development, training, deployment, and monitoring process.
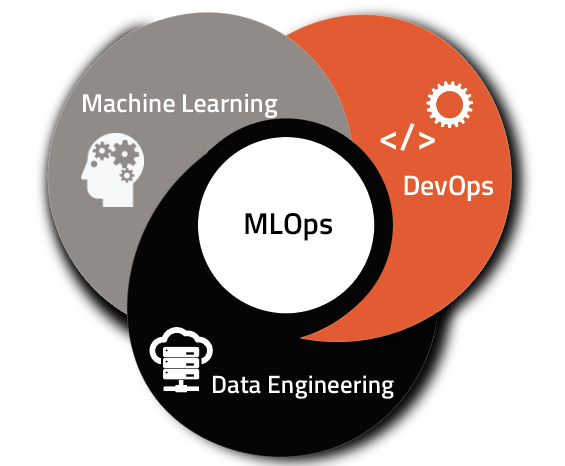
MLOps are the result of this. It was born at the crossroads of DevOps, Data Engineering, and Machine Learning, and while the concept is similar to DevOps, the execution differs. ML systems are more experimental in nature, with more components that are far more difficult to build and operate. Let’s get started!
What is MLOps?
The discipline of delivering Machine Learning models through repeatable and efficient workflows is known as Machine Learning Operations (MLOps).
MLOps, like DevOps for the software development lifecycle, enables the continuous delivery of high-performing ML applications into production at scale (SDLC). It considers ML’s unique need to establish a new lifecycle that sits alongside existing SDLC and CI/CD procedures, resulting in a more efficient workflow and better results for ML.
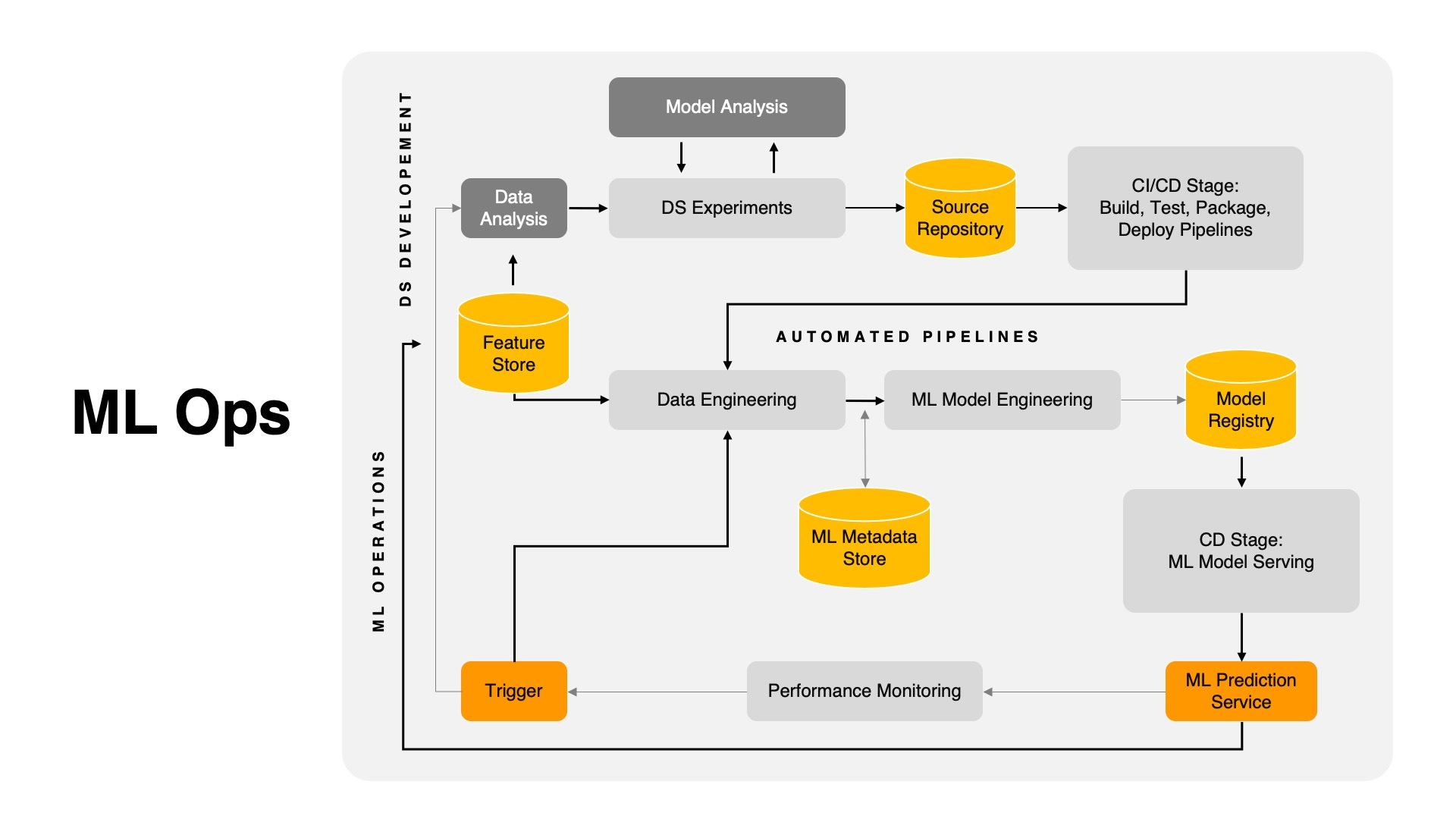
MLOps is a set of methods for data scientists and operations experts to collaborate and communicate. These methods improve the quality of Machine Learning and Deep Learning models, simplify the management process, and automate their deployment in large-scale production contexts. Models can be more easily aligned with business demands and regulatory requirements.
Why MLOps?
Once models are in production, machine learning becomes useful. On the other hand, organizations frequently misunderstand the complexity and obstacles of bringing machine learning into production, spending most of their resources on ML development and treating machine learning like normal software.
What’s the result? Organizations fail to see outcomes from their machine learning programs, resulting in lost money, squandered resources, and a struggle to retain personnel. In truth, machine learning isn’t like regular software. It necessitates its distinct strategy, and code is only a small part of what constitutes a good AI program.
ML necessitates its own distinct lifecycle:
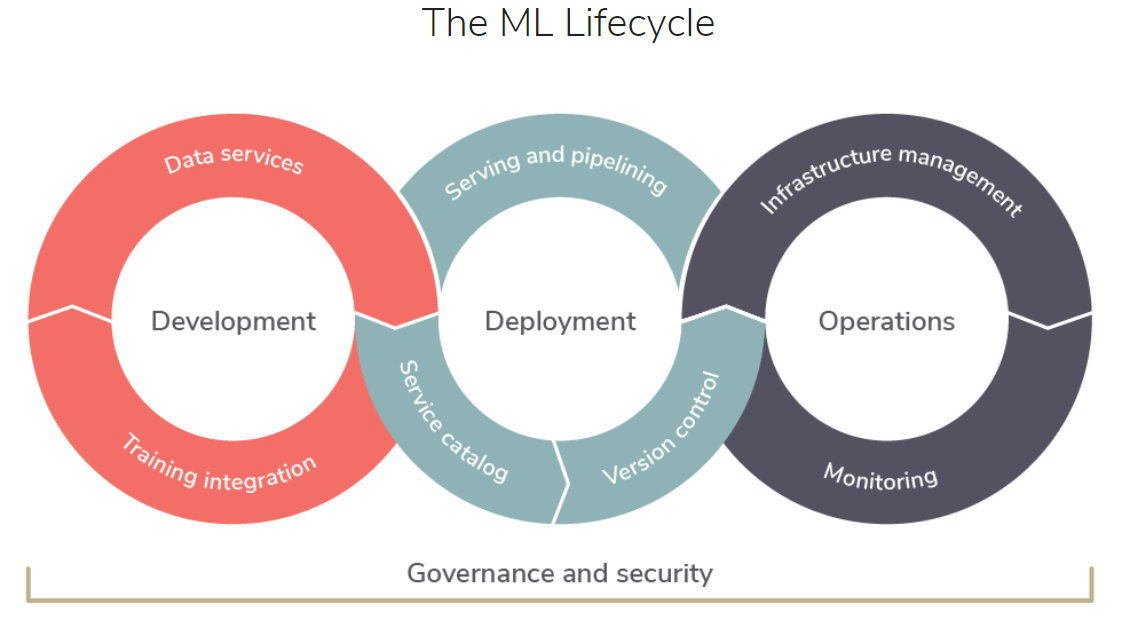
Because data is at the heart of the program, ML differs from normal software. This indicates that the code is centred on data management rather than application activity. ML is also an open-loop, ever-evolving system. The task has barely just begun once the models have been distributed. To achieve maximum performance, models in production must be regularly monitored, retrained, and redeployed in response to changing data signals.
The ML lifecycle is continuous integration, development, and delivery process for machine learning models. Models constantly cycle through three key stages—development, deployment, and operations to facilitate their continuous adjustment in production. All three stages of the lifecycle require governance and security to guarantee that the entire process adheres to organizational standards.
How MLOps work?
MLOps is well-positioned to address many of the same concerns that DevOps addresses in the software engineering world. DevOps addresses issues when developers hand off projects to IT Operations for implementation and maintenance, while MLOps offers data scientists a comparable set of advantages. Data scientists, machine learning engineers, and app developers may use MLOps to focus on cooperatively delivering value to their clients.
MLOps includes all of the essential components and the ability to integrate them all together—from data sources to compliance tools.
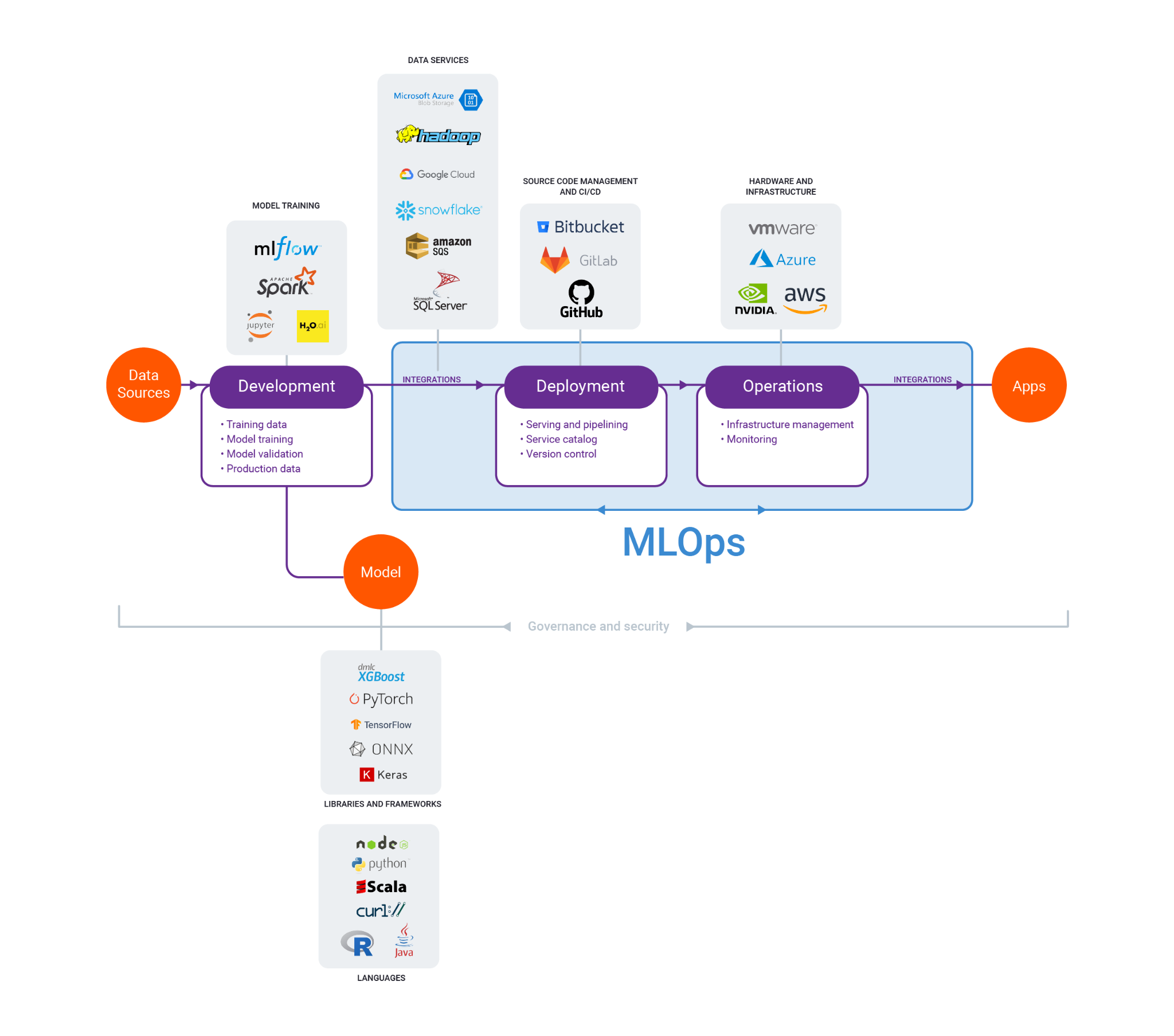 To build repeatable ML, the modelling code, dependencies, and any additional runtime requirements can be packed. The cost of shipping and maintaining model versions will be reduced because of reproducible ML. It will also be considerably easier to deploy at scale now that it has been packaged. This phase in the MLOps journey provides reproducibility and is one of several essential steps.
To build repeatable ML, the modelling code, dependencies, and any additional runtime requirements can be packed. The cost of shipping and maintaining model versions will be reduced because of reproducible ML. It will also be considerably easier to deploy at scale now that it has been packaged. This phase in the MLOps journey provides reproducibility and is one of several essential steps.Benefits of MLOps
MLOps projects benefit organizations in a variety of ways, including:
- Delivering more models, quicker: The speed with which you can deploy and iterate on models gives you a competitive advantage with machine learning. MLOps’ repeatable, scalable methods enable you to put machine learning into production much faster.
- Maximize ROI: Model and infrastructure monitoring is a fragmented endeavor without MLOps if it exists at all. You can now quickly monitor and adjust your models and infrastructure, resulting in additional profit margins while reducing infrastructure expenditures.
- Increase business agility: To keep ahead of the competition, you’ll need to tune your models on a frequent basis. But you don’t have to do it by hand! You may use MLOps to build automated pipelines and workflows that reduce your overall cost of ML while maintaining your competitiveness.
- Integrate flexibly: You want to use the most cutting-edge machine learning techniques, but the quick rate of change makes it tough to stay up. You can simply maintain integrations with a variety of data science tools using MLOps without incurring additional technical debt.
MLOps vs. DevOps
MLOps is a collection of machine learning-specific engineering methods based on the more widely used DevOps principles in software engineering. While DevOps focuses on delivering apps quickly and iteratively, MLOps applies the same ideas to putting machine learning models into production. Improved software quality, shorter patching, and release cycles, and higher customer satisfaction are the end results in both scenarios.
- Hybrid team composition: the team that will be required to construct and deploy models in production will not be only made up of software engineers. Data scientists or ML researchers are frequently part of an ML project’s team, and they focus on exploratory data analysis, model creation, and experimentation.
- Automated Deployment: As a prediction service, you can’t merely deploy an offline-trained ML model. To automatically retrain and deploy a model, you’ll require a multi-step pipeline. Because you need to automate the activities that data scientists conduct manually before deployment to train and validate new models, this pipeline adds complexity.
- Testing: In addition to traditional code tests like unit and integration testing, evaluating an ML system entails model validation, model training, and so forth.
How to Implement MLOps at an Organization?
The three best approaches for implementing MLOps in an organization are listed below:
Integrate with your existing systems
Machine learning does not occur in a vacuum. Integrate your MLOps platform with your existing enterprise systems, infrastructure, development tools, and reporting applications. Make a list of all the integrations you’ll need to support using our MLOps guide.
Don’t reinvent the wheel
When you consider the cost of people, missed opportunities, and mistakes made along the road, building an MLOps platform from scratch will put you back years and cost far more than an off-the-shelf option. Consider using a commercial MLOps platform that is more cost-effective, stable, and future-proofed.
Say no to lock-in
Allowing your processes to limit the data science technology that your team can use is a mistake. Look for an MLOps platform that works with the tools you already have and enables growth and flexibility.
Sample Code
Some frequent operations in MLOps are listed below, along with tips on how to test them.
Saving and loading data
In MLOps projects, popular scenarios include reading and writing to CSV, reading pictures, and loading audio files.
def load_data(filename: str) -> pd.DataFrame:
if os.path.isfile(filename):
df = pd.read_csv(filename, index_col='ID')
return df
return None
import utils
from mock import patch
@patch('utils.os.path.isfile')
@patch('utils.pd.read_csv')
def test_load_data_calls_read_csv_if_exists(mock_isfile, mock_read_csv):
utils.os.path.isfile.return_value = True
filename = 'file.csv'
# act
_ = utils.load_data(filename)
# assert
utils.pd.read_csv.assert_called_once_with(filename, index_col='ID')
|
Transforming data
Test fixed input and output while cleaning and altering data, but aim to keep each test to one verification. Create one test, for example, to ensure that the data output shape is correct.
def test_resize_image_generates_the_correct_size(): # Arrange original_image = np.ones((10, 5, 2, 3)) # act resized_image = utils.resize_image(original_image, 100, 100) # assert resized_image.shape[:2] = (100, 100) |
And one to double-check that any padding is done correctly.
def test_resize_image_pads_correctly(): # Arrange original_image = np.ones((10, 5, 2, 3)) # Act resized_image = utils.resize_image(original_image, 100, 100) # Assert assert resized_image[0][0][0][0] == 0 assert resized_image[0][0][2][0] == 1 |
Use parametrize to test different inputs and expected outputs automatically.
@pytest.mark.parametrize('orig_height, orig_width, expected_height, expected_width',
[
# smaller than target
(10, 10, 20, 20),
# larger than target
(20, 20, 10, 10),
# wider than target
(10, 20, 10, 10)
])
def test_resize_image_generates_the_correct_size(orig_height, orig_width, expected_height, expected_width):
# Arrange
original_image = np.ones((orig_height, orig_width, 2, 3))
# act
resized_image = utils.resize_image(original_image, expected_height, expected_width)
# assert
resized_image.shape[:2] = (expected_height, expected_width)
|
Model load or predict
@pytest.mark.longrunning
def test_integration_between_two_systems():
# this might take a while
|
Conclusion
- MLOps attempts to combine the machine learning and software application release cycles.
- MLOps enables machine learning artifacts to be tested automatically (For example, data validation, machine learning model testing, and machine learning model integration testing)
- MLOps allows machine learning projects to be run using agile principles.
- MLOps provides CI/CD systems to support machine learning models and datasets in order to create these models as first-class citizens.
- MLOps helps machine learning models reduce technical debt.
- MLOps must be a practice that is independent of language, framework, platform, and infrastructure.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A graduate in Computer Science and Engineering from Tezpur Central University. Currently, I am pursuing my M.Tech in Computer Science and Engineering in the Department of CSE at NIT Durgapur. I expect to Postgraduate in the spring, 2022. A Grounded and Solution-oriented Computer Engineer with a wide variety of experiences. Adept at motivating self and others. Passionate about programming and educating the next generation of technology users and innovators.






