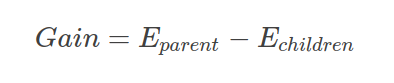Job interviews are…well, hard! Some interviewers ask hard questions while others ask relatively easy questions. As an interviewee, it is your choice to go prepared. And when it comes to a domain like Machine Learning, preparations might fall short. You have to be prepared for everything.
While preparing, you might have stuck at a point where you wonder what more shall I read. Well, based on almost 15-17 data science interviews that I have attended, here I have put 15, very commonly asked, as well as important Data Science and Machine Learning related questions that were asked to me in almost all of them and I recommend you must study these thoroughly. This will help you utilize your time efficiently and focus on what is important rather than wandering across the web to search for questions and answers to them.
15 Most Common Interview Questions
1. Explain the Difference between Classification and Regression with at least 1 example.
Ans. As the name suggests, Classification algorithms classify the output variables into two or more classes or categories so that they become discrete values. Whereas, Regression algorithms calculate continuous and real values, unlike Classification algorithms.
Explain this difference using an example. Using classification, a company can predict whether an employee might resign or not in the next 5-10 years, using their data, like their salary, bonus, work experience, their age etc. Using regression, the same company can analyse their product demand, analyse product manufacturing errors etc. using their product purchase history, customer satisfaction, returns, complaints etc.
2. Which is your favourite clustering algorithm? Explain why.
Ans. My favourite clustering algorithm is K-Means Clustering. The simplicity of this algorithm draws my attention. In K-Means all we have to do is these simple 4 steps-
1. Choose k number of clusters.
2. Specify the cluster seeds.
3. Assign each data point to a centroid
4. Adjust the centroids
By these steps, K-Means can scale according to the dataset and is also very efficient. The results are easy to interpret too.
Moreover, the elbow method is a very interesting and simplistic approach to optimise the K-Means algorithm taking account of the WCSS (Within Cluster Sum of Squares) Vs. the k number of clusters, which always produces a curve that looks like an elbow!
Source-Datanovia
The elbow point value is the optimal number of clusters for your data! It greatly improves your model performance in a very elegant yet easy way, which I admire!
3. What is the generalized equation of a supervised Machine Learning model and explain it in your own words.
Ans. Almost every supervised Machine Learning model is represented mathematically as y = f(x), where, y is the output variable and x is the dependent input feature. f(x) is a generalized representation of a Machine Learning model, that takes in input features(xi = x1, x2, x3….,xn) and gives out predicted output (ŷ).
4. What is bootstrap sampling? How is it useful in ML? Explain with a use-case.
Ans. The bootstrap method is a resampling technique used to estimate statistics on a population by sampling a dataset with replacement. It is used in applied Machine Learning to estimate the skill of machine learning models when making predictions on data not included in the training data.
In Machine Learning, bootstrap sampling is used in an ensemble algorithm called bootstrap aggregation or Bagging. It helps avoid overfitting and improves the stability of a Machine Learning algorithm.
For example, the Bootstrap Aggregation algorithm helps create multiple different models from a single training dataset. A very popular use case is predicting election results for an area using sample data instead of taking election data of the entire population.
5. What are overfitting and underfitting? Explain in terms of statistic terminologies and suggest measures to reduce both.
Ans. Overfitting is the phenomenon that occurs when we fit a huge amount of data into a Machine Learning model (which might include noisy and inaccurate data) or also when a model fits exactly to its training data points such that it starts giving wrong predictions. The model becomes ‘overconfident’ and treats data points outside its knowledge to be wrong or inaccurate. Statistically, Overfitting occurs due to low bias and high variance. Overfitting can be reduced by using a linear model for linear data, pruning unnecessary nodes in a Decision tree to reduce its complexity, training with more data where necessary etc.
Underfitting occurs when a Machine Learning model neither fits on the training data nor generalizes to the new data to test on. The model fails to recognize the underlying trends of the data. It usually happens when we have very fewer data to build an accurate model, also when we try to build a linear model with fewer non-linear data. Statistically, underfitting occurs due to high bias and low variance. Underfitting can be reduced by using other Machine Learning algorithms, fitting more data, removing noise from data, increasing the number of features by performing feature engineering etc.
6. Define Euclidean, Manhattan and Minkowski distance. In what kind of problems are they used and why?
Ans. Euclidean distance: Euclidean distance between two points is the length of the line that joins the two points. Consider two points A(x1, y1) and B(x2, y2) in the cartesian plane. The Euclidean distance between them is represented as:
Manhattan distance: Manhattan distance between two points in an n-dimensional space is the sum of the distances in each dimension. Consider two points A(x1, y1) and B(x2, y2) in the cartesian plane. The Manhattan distance between them is represented as:
Minkowski distance: Minkowski distance is a generalized form of Euclidean and Manhattan distances. For two points A(x1, x2) and B(y1, y2) the Minkowski between them is:
7. Describe what you mean by bias-variance trade-off in ML.
Ans. Bias is the difference between the actual and predicted output. In n-dimensional space, bias can be the distance between the true value points and the predicted value points. A high bias means the model is streamlining the common data points and hence such a simplified approach leads to incorrect prediction and a huge distance gap between true and predicted values. Such bias introduces underfitting.
On the other hand, variance is how varied predictions our model is doing. In a space where data points are widely scattered, the model tries to learn every data point so perfectly that instead of recognizing patterns, it becomes more like a forcefully memorizing them. Memorization will only lead to good performance as long as it is predicting training data’s outputs. As soon as we give new unknown data to predict, it will give an error. Such behaviour occurs when the model tries to fit the noise and fluctuations (variance). It introduces overfitting.
So bias and variance are opposites to each other, and the trade-off is simply computing the balance between bias and variance so that error is minimised. Whenever we have a low bias, variance increases and vice versa. So, we have to model in a way that bias and variance both stay balanced and neither overfitting nor underfitting occurs. Such kind of tuning is called Bias Variance Tradeoff.
8. What is Vectorization? Why is Vectorization important in NLP use cases?
Ans. Machine Learning algorithms cannot work on raw text data. They are to be converted to numerical data. Vectorization is a method of converting text data to numerical vectors so that the text can be easily analyzed or consumed by the Machine Learning algorithm.
In NLP, Vectorization is used to map words or phrases from vocabulary to a corresponding vector of real numbers to enable word predictions, word similarities/semantics and grammar checks.
9. Mention some differences between covariance and correlation.
Ans. a. Correlation coefficients range from -1 to 1 and covariance values range from -∞ to +∞.
b. Correlation measures how two variables are related to each other and by how much. Covariance measures whether a variation in one variable results in a variation in another variable.
c. Changing the scale of variables affects covariance i.e. if the variables are changed using similar or different constants, the calculated covariance between the variables changes. But in the case of correlation, this doesn’t happen. Correlation is not affected by a change of scale.
10. Why is the Naive Bayes algorithm, naive? Mention its advantages and disadvantages.
Ans. A naive Bayes classifier presumes that a particular feature of a class is unrelated to any other feature, given the class variable. Simply, Naive Bayes assumes that the variables are independent of each other. This assumption may or may not be correct as it falls under the probabilistic classifiers in statistics. This is the reason it’s called Naive.
Advantages
1. Extremely easy to implement and follows a simple probabilistic approach (Bayes’ Theorem).
2. Works great in small datasets, and can classify stuff even when no data is there!
3. Massively used for spam-filtering and specially text-classification tasks ( as it works better when attributes/features in data are independent of each other).
Disadvantages
1. Works poorly with numerical data, as numerical data is mostly normally distributed.
2. The ‘naive’ approach to considering attributes independent of each other, doesn’t often work well in complex problems.
11. Explain a decision tree. What do you know about the ID3 algorithm?
Ans. A decision tree is a tree-like structure that contains leaves, nodes and edges. It has a root node, parent nodes and child nodes. Each parent node is split into one or more child nodes. The terminal nodes or leaf nodes represent the output variables.
In the decision tree, ID3 stands for Iterative Dichotomiser 3. Dichotomiser means dividing. The algorithm is used for feature selection in a decision tree by the top-down greedy approach (builds the tree from the top and selects the best feature at each step iteratively using Entropy/Information Gain). Each parent node is divided into one or more child nodes iteratively till no more division is possible.
12. Entropy or Gini Impurity? – define them and decide which is better for selecting the best features in your data.
Ans. Entropy: It is the measure of impurity of a variable. It describes how well a node is split. The higher the entropy of a node, the higher will be its impurity. For the best split, it is always suggested to choose nodes with low entropy. Entropy is calculated by –
Gini Impurity: Like Entropy, Gini impurity also measures the impurity of a variable or how good a node is split. In both, Entropy and Gini impurity, a node that has multiple classes is considered impure and a node having a single class is pure.
Source – thatascience
If we compare both the methods then Gini Impurity is more efficient than entropy in terms of computing power. Training time when using the Entropy criterion is much higher because Entropy is calculated using logarithms. Hence, Gini impurity must be preferred over Entropy.
13. What are leaf nodes in the Decision tree?
Ans. Leaf nodes in a Decision tree are the end or terminal or child nodes. These nodes cannot be split any further. Hence, they are the output classes or categories like YES or NO; GOOD, BAD and SATISFACTORY etc.
14. What are the disadvantages of the Decision tree?
Ans. a. Decision tree has a broad chance of getting overfitted. This generally happens when the dataset is huge, has many features or when we try to fit more data into it. An overfitted model will give wrong predictions for unseen data.
b. It tends to become more complex when we add more data to it. Upon adding new data points, the nodes get calculated again and the tree is restructured. This reduces the efficiency of the model. Hence, for time-series analysis, the Decision tree is not used. Random forest is used instead.
c. Decision tree is vulnerable to noisy datasets. It tries to fit all the data including the noisy data, and later tends to give wrong predictions.
15. Explain Information Gain in the Decision tree algorithm with its mathematical formula.
Ans. Information gain tells us how good a split between a parent node and its children nodes is. The higher the Information gain, the better is the split. High entropy indicates that data is uniform and low entropy means data is more scattered or distributed. Hence, with decreasing entropy, Information gain increases. Information gain is mathematically represented as:
Here, Eparent is the entropy of the parent node, and Echildren is the entropy of the child nodes.
Tips for Interviews
Some tips to bear in mind before attending/during data science interviews-
Always remember to explain your answers with a pen and paper using graphs/formulas as proof of concepts in an interview. It increases your chance of getting selected as data scientists are much preferred to be extremely detailed with whatever they do! Hence, such a storytelling habit must reflect in your interviews.
Avoid the use of abbreviations like ML/DL/NLP/CV if you are sitting for an entry-level role interview. Be as much thorough as you can.
Try to not put skills or frameworks that you have used barely 1-2 times and only put those you extensively work with.
Try to be honest and humble while answering questions. Learn to humbly address that you don’t know the answer to a particular question asked rather than covering it up with irrelevant information. Most of the time candidates get rejected for such arrogant behaviour.
Be friendly yet professional. Have confidence and don’t show up with a “stressed” and “anxious” face.
Conclusion on Interview Questions
Hope this article will help you get a quick and efficient revision before your gruelling data science interviews.
Key takeaways from this article are-
You learned about very important concepts like bias-variance tradeoff, classification, regression etc.
The pros and cons of one of the most used classifiers Naive Bayes.
Important concepts like Entropy and Gini Impurity in Decision trees.
Very crucial mathematical and statistical concepts like covariance and correlation, vectorization, and distance metrics.
Overfitting Vs Under-fitting which is a MUST to know concept for any machine learning enthusiast.
Cheers and all the best! Hope you ace your data science interviews!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A Machine Learning and Deep Learning practitioner with a background in Computer Science Engineering. My work interests include Machine Learning, Deep Learning, Computer Vision and NLP, with expertise in Generative AI and Retrieval Augmented Generation.
We use cookies essential for this site to function well. Please click to help us improve its usefulness with additional cookies. Learn about our use of cookies in our Privacy Policy & Cookies Policy.
Show details
Powered By
Cookies
This site uses cookies to ensure that you get the best experience possible. To learn more about how we use cookies, please refer to our Privacy Policy & Cookies Policy.
brahmaid
It is needed for personalizing the website.
csrftoken
This cookie is used to prevent Cross-site request forgery (often abbreviated as CSRF) attacks of the website
Identityid
Preserves the login/logout state of users across the whole site.
sessionid
Preserves users' states across page requests.
g_state
Google One-Tap login adds this g_state cookie to set the user status on how they interact with the One-Tap modal.
MUID
Used by Microsoft Clarity, to store and track visits across websites.
_clck
Used by Microsoft Clarity, Persists the Clarity User ID and preferences, unique to that site, on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
_clsk
Used by Microsoft Clarity, Connects multiple page views by a user into a single Clarity session recording.
SRM_I
Collects user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
SM
Use to measure the use of the website for internal analytics
CLID
The cookie is set by embedded Microsoft Clarity scripts. The purpose of this cookie is for heatmap and session recording.
SRM_B
Collected user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the website is doing. The data collected includes the number of visitors, the source where they have come from, and the pages visited in an anonymous form.
_ga_#
Used by Google Analytics, to store and count pageviews.
_gat_#
Used by Google Analytics to collect data on the number of times a user has visited the website as well as dates for the first and most recent visit.
collect
Used to send data to Google Analytics about the visitor's device and behavior. Tracks the visitor across devices and marketing channels.
AEC
cookies ensure that requests within a browsing session are made by the user, and not by other sites.
G_ENABLED_IDPS
use the cookie when customers want to make a referral from their gmail contacts; it helps auth the gmail account.
test_cookie
This cookie is set by DoubleClick (which is owned by Google) to determine if the website visitor's browser supports cookies.
_we_us
this is used to send push notification using webengage.
WebKlipperAuth
used by webenage to track auth of webenagage.
ln_or
Linkedin sets this cookie to registers statistical data on users' behavior on the website for internal analytics.
JSESSIONID
Use to maintain an anonymous user session by the server.
li_rm
Used as part of the LinkedIn Remember Me feature and is set when a user clicks Remember Me on the device to make it easier for him or her to sign in to that device.
AnalyticsSyncHistory
Used to store information about the time a sync with the lms_analytics cookie took place for users in the Designated Countries.
lms_analytics
Used to store information about the time a sync with the AnalyticsSyncHistory cookie took place for users in the Designated Countries.
liap
Cookie used for Sign-in with Linkedin and/or to allow for the Linkedin follow feature.
visit
allow for the Linkedin follow feature.
li_at
often used to identify you, including your name, interests, and previous activity.
s_plt
Tracks the time that the previous page took to load
lang
Used to remember a user's language setting to ensure LinkedIn.com displays in the language selected by the user in their settings
s_tp
Tracks percent of page viewed
AMCV_14215E3D5995C57C0A495C55%40AdobeOrg
Indicates the start of a session for Adobe Experience Cloud
s_pltp
Provides page name value (URL) for use by Adobe Analytics
s_tslv
Used to retain and fetch time since last visit in Adobe Analytics
li_theme
Remembers a user's display preference/theme setting
li_theme_set
Remembers which users have updated their display / theme preferences
We do not use cookies of this type.
_gcl_au
Used by Google Adsense, to store and track conversions.
SID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SAPISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
__Secure-#
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
APISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
HSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
DV
These cookies are used for the purpose of targeted advertising.
NID
These cookies are used for the purpose of targeted advertising.
1P_JAR
These cookies are used to gather website statistics, and track conversion rates.
OTZ
Aggregate analysis of website visitors
_fbp
This cookie is set by Facebook to deliver advertisements when they are on Facebook or a digital platform powered by Facebook advertising after visiting this website.
fr
Contains a unique browser and user ID, used for targeted advertising.
bscookie
Used by LinkedIn to track the use of embedded services.
lidc
Used by LinkedIn for tracking the use of embedded services.
bcookie
Used by LinkedIn to track the use of embedded services.
aam_uuid
Use these cookies to assign a unique ID when users visit a website.
UserMatchHistory
These cookies are set by LinkedIn for advertising purposes, including: tracking visitors so that more relevant ads can be presented, allowing users to use the 'Apply with LinkedIn' or the 'Sign-in with LinkedIn' functions, collecting information about how visitors use the site, etc.
li_sugr
Used to make a probabilistic match of a user's identity outside the Designated Countries
MR
Used to collect information for analytics purposes.
ANONCHK
Used to store session ID for a users session to ensure that clicks from adverts on the Bing search engine are verified for reporting purposes and for personalisation
We do not use cookies of this type.
Cookie declaration last updated on 24/03/2023 by Analytics Vidhya.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies, we need your permission. This site uses different types of cookies. Some cookies are placed by third-party services that appear on our pages. Learn more about who we are, how you can contact us, and how we process personal data in our Privacy Policy.

.png)
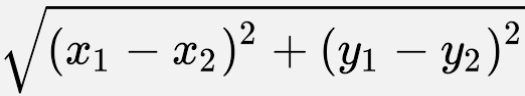
.png)
.png)