This article was published as a part of the Data Science Blogathon.
Introduction
With a huge increment in data velocity, value, and veracity, the volume of data is growing exponentially with time. This outgrows the storage limit and enhances the demand for storing the data across a network of machines. A unique filesystem is required to manage all the complications of a network that appears while storing data across a network, and this is where HDFS finds its place.
What is HDFS?
HDFS stands for Hadoop Distributed File System. As the name suggests, it is a distributed file system with a unique design to handle a huge sum of data sets by providing the storage capability for huge files having data in the range of petabytes to zettabytes. Like MapReduce and YARN, HDFS is also a significant component of Apache Hadoop. It can deploy on commodity hardware that is handy and affordable. HDFS is highly fault-tolerant, and this feature distinguishes HDFS from other file systems. It provides one of the most reliable filesystems, designed on the principle of write-once and read-many-times and hence reduces the overhead of loading data every time.
Why HDFS?
Below are some reasons why you have to use Apache Hadoop’s HDFS:
-
Massive data sets – HDFS can scale thousands of nodes in a single cluster. It assures the high aggregate data bandwidth for real-world scenarios where data ranges from terabytes to petabytes.
-
Quick recovery from hardware failures – Hardware failure is a common issue that can occur without any prior notice and leads to data loss or server going down. But the building of HDFS contains the automatic failure detection and recovery features.
-
Portability – HDFS is highly portable to the hardware platforms and compatible with commodity hardware.
-
Access to streaming data – It is nothing but the ability to write once and read many times, which increases the data throughput.
HDFS Architecture and Components
The HDFS architecture follows the enslaver and enslaved person approach with the following HDFS components:
-
Namenode
-
Secondary Namenode
-
File system
-
Datanode
-
Block

Source:-https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
Let’s discuss each component one by one!
Namenode
The NameNode is the controller node responsible for receiving various tasks from the clients. The job of the primary node is to ensure that the data needed for the file operations are loaded in Hadoop and segregated into chunks of data segments. The main tasks of the primary node include−
-
Management of the file system namespace.
-
Regulation of client’s access to files.
-
There cannot be more than one NameNode server in an entire cluster. Hence, it acts as a core component of an HDFS cluster. It is responsible for various file systems namespace operations such as opening, closing, and renaming HDFS files and directories.
Secondary Namenode
People get confused with the name of a Secondary NameNode and treat it as a backup node. But the secondary node is not a backup node; instead, it is a helper node for the Namenode or a checkpoint node.
Working on a secondary Namenode

Source:- https://www.researchgate.net/figure/The-Secondary-NameNode_fig3_316926812
-
In the regular intervals, it takes the edit logs from the Namenode and applies them to the fsimage.
-
As soon as it gets a new fsimage, it copies the updated Fsimage back to Namenode.
-
Namenode can use this Fsimage for the next restart to reduce the startup time.
File System
HDFS follows the traditional hierarchical file system with directories and files and stores all the user data in the field format. Users can perform various operations on files like creating files, removing files, renaming files, copying or moving files from one place to another, etc. The NameNode allows the users to work with directories and files by keeping track of the file system namespace. The NameNode maintains the file system namespace and records the changes made to the metadata information.
Datanode
Datanode is also known as an agent node in HDFS. It is responsible for storing the actual data as per the instructions of the Namenode. More than one DataNode is available for a functional filesystem based on the type of network and the storage system, with data replicated across them. The Datanodes perform read-write operations on the Hadoop files per client request. It is also responsible for various functions like block creation, deletion, and replication, as instructed by Namenode.
The data block approach is helpful as it provides the following:
-
Simplified data replication
-
Fault-tolerance capability, and
-
Reliability
Block
HDFS stores a vast amount of user data in the form of files. The files can further be divided into small segments or chunks. These segments are known as blocks, and they act as a physical representation of data and are used to store the minimum amount of data that can be written/read by the HDFS file system. By default, the size of a block is 64MB, which can be increased based on the need to change in HDFS configuration.
Starting HDFS
To start the HDFS in the distributed mode, first, we have to format the configured HDFS file system. Execute the below command to open the HDFS server(Namenode).
$ Hadoop Namenode -format
Once we format the HDFS, we can start the distributed file system. Run the below command to start the Namenode and the Datanode as a cluster.
$ start-dfs.sh
NOTE:- .sh is the extension for the Hadoop shell.
Listing Files in HDFS
Once we load the file information into the server, we can find a specific list of all the files and directories present in HDFS. To get the names of files and directories with their status, we use the “ls” command.
Syntax:
$HADOOP_HOME/bin/hadoop fs -ls
Data Insertion in HDFS
It should be present in our local system before inserting the data into the Hadoop file system. So, first of all, we create a sample file in Cloudera and then move it to the Hadoop system. Below are the steps to insert data in the Hadoop distributed file system.
Step 1
Create an input directory in HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir /user/input
Step 2
With the help of the ‘put’ command, transfer the data from local systems and store it into the Hadoop file system.
Note:- sample.txt should be present at Cloudera(local system).
$HADOOP_HOME/bin/hadoop fs -put /home/sample.txt /user/input
Step 3
Verify the file using the ‘ls’ command.
$HADOOP_HOME/bin/hadoop fs -ls /user/input
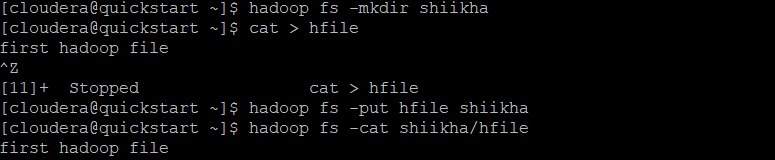

Data Retrieval from HDFS
To retrieve the file present in the HDFS, we use the “get” command.
Note:- We are assuming that the “sample” file is already present in the output directory of Hadoop.
Step 1
We use the cat command to view the content of a Hadoop file named sample.
$HADOOP_HOME/bin/Hadoop fs -cat /user/output/sample
Step 2
Run the “get” command to retrieve the file from HDFS to the local file system.
$HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/cloudera/

Shutting Down the HDFS
Run the below command to stop the HDFS and return to the local server.
$ stop-dfs.sh
Conclusion
In this blog, we learned the basic commands of the Hadoop Distributed File System to store and manage the metadata and performed some Linux-based HDFS commands.
- We discussed commands for starting the HDFS, inserting the data into Hadoop files, retrieving the data from Hadoop files, and shutting down the HDFS.
- We don’t have to install Hadoop explicitly. We can open the Cloudera to run these Linux-based HDFS commands.
- Cloudera and Apache natively support Hadoop.
If you have any queries, let me know in the comment section.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





